Handling whitespace
The presence of whitespace in the DOM can cause layout problems and make manipulation of the content tree difficult in unexpected ways, depending on where it is located. This article explores when difficulties can occur, and looks at what can be done to mitigate resulting problems.
What is whitespace?
Whitespace characters consist of different characters in different programming language contexts. Document white space characters, as far as the CSS whitespace processing rules are concerned, only include spaces (U+0020), tabs (U+0009), line feeds (LF, U+000A), and carriage returns (CR, U+000D), where CR characters are equivalent to spaces in every regard. These characters allow you to format your code for readability. Much of our source code is full of these whitespace characters, and we tend to remove them only as part of a production build step to reduce file size.
Note that this list does not include non-breaking spaces (U+00A0, in HTML). So these characters don't trigger any collapsing, which is why they are often used to create longer spaces in HTML.
CSS also defines the concept of segment breaks, which in the context of HTML are equivalent to LF characters.
How does HTML process whitespace?
It is a common myth that "HTML ignores whitespace", which is untrue: HTML preserves all whitespace text content as you wrote them in the source code. As a markup language, HTML produces a DOM where all whitespace in the text content is preserved, which can be retrieved and manipulated via DOM APIs such as Node.textContent. If HTML strips whitespace from the DOM, then CSS, a downstream rendering engine that works on the DOM, would not be able to preserve them using the white-space property.
Note: To be clear, we're talking about whitespace between HTML tags, which becomes text nodes in the DOM. Any whitespace inside a tag (between the angle brackets but not as part of an attribute value) is just part of the HTML syntax and does not appear in the DOM.
Note:
Due to the magic that is HTML parsing (quote from DOM spec), there do exist certain places where whitespace characters could be ignored. For example, whitespace between the <html> and <head> opening tags or between the </body> and </html> closing tags is ignored and does not appear in the DOM. Also, when parsing the <pre> element's text content, a single leading newline character gets stripped. We ignore these edge cases.
Furthermore, the HTML parser does normalize certain whitespaces: it replaces CR and CRLF sequences with a single LF. However, CR characters can also be inserted into the DOM either via character references or JavaScript, so the CSS whitespace processing rules still need to define how to handle them.
Take the following document, for example:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
The DOM tree for this looks like so:

Note that:
- Some text nodes will contain only whitespace.
- Other text nodes may have whitespace at the beginning or the end.
Note: Firefox DevTools supports highlighting text nodes, enabling you to see exactly which nodes contain whitespace characters. Pure whitespace nodes are marked with a "whitespace" label.
Conserving whitespace characters in the DOM is useful in many ways, but it can also make certain layouts more difficult to implement and may cause problems for developers who want to iterate over DOM nodes. We'll look at these issues and some solutions later on, in the solving common problems with whitespace nodes section.
How does CSS process whitespace?
When the DOM is passed to CSS for rendering, the whitespace is largely stripped by default. This means that the way your code is formatted is not visible to the end user—creating space around and inside elements is the job of CSS.
<!doctype html>
<h1> Hello World! </h1>
This source code contains a couple of line feeds after the doctype and a bunch of space characters before, after, and inside the <h1> element. But the browser ignores these spaces and just shows the words "Hello World!" as if these characters didn't exist at all:
CSS ignores most, but not all, whitespace characters. In this example, one of the spaces between "Hello" and "World!" still exists when the page is rendered in a browser. CSS uses a specific algorithm to decide which whitespace characters are user-irrelevant and how they are removed or transformed. We'll explain how this processing works in the next few sections.
Collapsing and transformation
Let's look at an example. To make the whitespace characters more salient, we've also added a comment to show all spaces as ◦, all tabs as ⇥, and all line breaks as ⏎:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
This example is rendered in the browser like so:
The <h1> element contains:
- A text node (consisting of some spaces, the word "Hello", a line break, and some tabs).
- An inline element (
<span>, which contains a space, and the word "World!"). - Another text node (with a tab and spaces after the
<span>).
Because this <h1> element contains only inline elements, it establishes an inline formatting context. This is one of the several layout rendering contexts that browser engines use to arrange content on the page.
Inside this inline formatting context, whitespace characters are processed as follows:
Note:
This algorithm can be configured via the white-space-collapse property (or its shorthand property white-space). We'll start by assuming its default value (white-space-collapse: collapse), then look at how different property values affect this algorithm.
-
First, all spaces and tabs immediately before and after a line break are ignored. So, if we take our example markup from before:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>...and apply this first rule, we get:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
Next, consecutive line breaks are collapsed into a single line break. We don't have any in this example.
-
Next, lines in the source code are joined into single lines by removing any remaining line break characters. They are either transformed into spaces (U+0020) or simply removed, depending on the context before and after the break. The exact choice between the two is browser- and language-dependent. In our example here in English (where spaces separate words), we can expect all line breaks to be "transformed" into spaces. So we end up with:
html<h1>◦◦◦Hello◦<span>◦World!</span>⇥◦◦</h1>Notably, in languages that have no word separators, such as Chinese, lines are joined with no intervening space. So:
html<div>你好 世界</div>might be rendered as "你好世界" without any spaces in between, depending on the browser's heuristics.
-
Next, all tab characters are transformed into space characters, so the example becomes:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> -
After that, any space immediately following another space (even across two separate inline elements) is ignored, so we end up with:
html<h1>◦Hello◦<span>World!</span>◦</h1>
This is why people visiting the web page will see the phrase "Hello World!" nicely written at the top of the page, rather than a weirdly indented "Hello" followed by an even more weirdly indented "World!" on the next line.
After these steps, the browser processes line wrapping and bidirectional text, which we will ignore here. Note that there are still spaces left after the opening <h1> tag and before the closing </h1> tag, but these are not rendered in the browser. We'll handle that next, as each line is laid out.
Different white-space-collapse values skip different steps of this algorithm:
preserveandbreak-spaces: the whole algorithm is skipped, and no whitespace collapsing or transformation happens.preserve-breaks: steps 2 and 3 are skipped, and line breaks are preserved.preserve-spaces: the whole algorithm is skipped and replaced with a single step to convert each tab or line break into a space.
In a nutshell, different whitespace characters are collapsed and transformed in the following fashion:
- Tabs are generally converted to spaces.
- If segment breaks are to be collapsed:
- Sequences of segment breaks are collapsed to a single segment break.
- They are converted to spaces in languages that separate words with spaces (like English), or removed altogether in languages that do not separate words with spaces (like Chinese).
- If spaces are to be collapsed:
- Spaces or tabs before or after segment breaks are removed.
- Sequences of spaces are collapsed to a single space.
- When spaces are preserved, sequences of spaces are treated as non-breaking, except that they will soft wrap at the end of each sequence — that is, the next line will always start with the next non-space character. In the case of the
break-spacesvalue, however, a soft wrap could potentially occur after each space, so the next line may start with one or more spaces.
Trimming and positioning
In both inline and block formatting contexts, elements are laid out in lines. In an inline formatting context, lines are created by text wrapping. In a block formatting context, on the other hand, each block forms its own line. As each line is laid out, whitespace is processed further. Let's take a look at an example to explain how this works.
In this example, as before, we've marked the whitespace characters in a comment. We have three text nodes that contain only whitespace: one before the first <div>, one between the 2 <div>s, and one after the second <div>.
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
This renders like so:
The whitespace in this example is handled as follows:
Note:
This algorithm can be configured via the white-space-collapse property (or its shorthand property white-space). We'll start by assuming its default value (white-space-collapse: collapse), then look at how different property values affect this algorithm.
-
First, the whitespace is collapsed the same way as we saw in the previous section, turning this:
html<body>⏎ ⇥<div>⇥Hello⇥</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>...into this:
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>Lines are then laid out according to the block formatting context established by
<body>. In this example, each of<body>'s five child nodes is laid out as a separate line. (Each line in this code block represents a line in the rendered layout, not a line in our original HTML code):html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>Note that if the lines become too long, each line may wrap and create more lines. In reality, browsers determine the content of the lines as the lines are laid out. We'll skip the part about how text wrapping works.
-
Sequences of spaces at the beginning of a line are removed, so the example becomes:
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
Each tab that's preserved at this point is rendered according to
tab-size. This can only happen withwhite-space-collapseset topreserveorbreak-spacesbecause all other settings turn tabs into spaces. -
Sequences of spaces at the end of a line are removed, so the above becomes:
html<body> <div>Hello</div> <div>World!</div> </body>
The three empty lines we now have are not going to occupy any space in the final layout, because they don't contain any visible content. So we'll end up with only two lines taking up space in the page. People viewing the web page see the words "Hello" and "World!" on two separate lines, just as you'd expect two <div>s to be laid out. Browsers essentially ignore all of the whitespace that was included in the HTML code.
Different white-space-collapse values skip different steps of this algorithm:
preserveandbreak-spaces: The whole algorithm is skipped except for step 3, so no whitespace collapsing or transformation happens.preserve-spaces: The whole algorithm is skipped, so whitespace characters at the start and end of lines are preserved.preserve-breaks: The same algorithm is applied as with thecollapsevalue.
How do DOM APIs process whitespace?
As mentioned previously, whitespace is preserved in the DOM. This means that if you retrieve Node.textContent, you will get the text content as you wrote it in the HTML source code, and if you retrieve Node.childNodes, you will get all the text nodes, including those that contain only whitespace.
Not all DOM APIs preserve whitespace; some APIs deal with the rendered text by design. For example, HTMLElement.innerText returns the text exactly as it's rendered, with all whitespace collapsed and trimmed. Selection.toString() returns the text as it would be pasted, which generally means that whitespace is collapsed. However, in Firefox (which collapses whitespace between Chinese characters, as mentioned in the collapsing and transformation section above), the collapsed whitespace is still preserved both in the string returned by toString() and in the pasted text.
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
Solving common problems with whitespace nodes
Whitespace nodes are invisible to the website visitor due to the CSS processing rules, but they can interfere with certain layouts and DOM manipulation that rely on the exact structure of the DOM. Let's look at some common problems and how to solve them.
Whitespace processing between inline and inline-block elements
Let's look at one layout issue with whitespace nodes: spaces between inline and inline-block elements. As we saw earlier with inline and block elements, most whitespace characters are ignored, but word-separating characters like spaces remain. The extra whitespace that does make it to the layout is helpful to separate the words in the sentence.
With inline-block elements, it gets more interesting: these elements behave like inline elements on the outside and blocks on the inside. (They're often used to display more complex pieces of UI, placed side by side on the same line, such as navigation menu items.) Any whitespace between adjacent inline or inline-block elements will result in spaces in the layout, just like the spaces between words in text. (This can surprise developers because they are blocks, and blocks don't normally show extra spaces.)
Consider this example (as before, we've included a comment in the HTML code to show the whitespace characters):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
This renders as follows:
You probably don't want the gaps between the blocks. Depending on your use case (such as a list of avatars or a horizontal row of navigation buttons), you probably want the elements to flush against each other, and to be able to control any spacing yourself.
The Firefox DevTools HTML Inspector can highlight text nodes and also show you exactly the area the elements are taking up. This is useful to check out if you suspect there's extra margin or unexpected whitespace causing gaps.
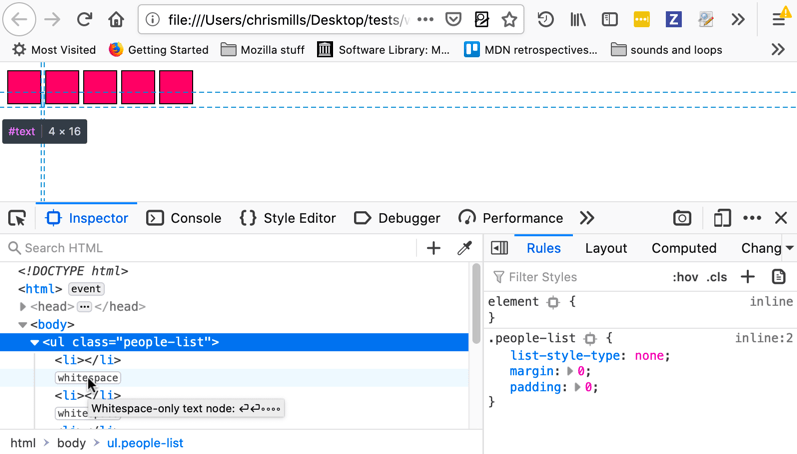
There are a few ways of getting around this problem:
-
Use Flexbox to create the horizontal list of items instead of trying an
inline-blocksolution. Flexbox handles spacing and alignment for you, and is definitely the preferred solution:cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
If you need to rely on
inline-block, you could set thefont-sizeof the list to0. This only works if the blocks are not sized withemunits (sinceemis based onfont-size, the block size would also end up being sized as0). Usingremunits would be a good choice here:cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
Alternatively, you could set negative margin on the list items:
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
You can also solve this problem by avoiding whitespace nodes between
<li>items:html<li> ... </li><li> ... </li>
Working with whitespace in the DOM
As mentioned previously, whitespace is collapsed and trimmed when rendered, but preserved in the DOM. This may present some pitfalls when trying to do DOM manipulation in JavaScript. For example, if you have a reference to a parent node and want to manipulate its first element child using Node.firstChild, a rogue whitespace node just after the opening parent tag will give you the wrong result. The text node would be selected instead of the element you want to target.
As another example, if you want to do something to a subset of elements based on whether they are empty (have no child nodes), you could use Node.hasChildNodes(). But if any of those elements contain text nodes, you could end up with false results.
The following JavaScript code shows several functions that deal with whitespace in the DOM:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the `CharacterData` interface (i.e.,
* a `Text`, `Comment`, or `CDATASection` node)
* @return `true` if all of the text content of `nod` is whitespace,
* otherwise `false`.
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the `Node` interface.
* @return `true` if the node is:
* 1) A `Text` node that is all whitespace
* 2) A `Comment` node
* and otherwise `false`.
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // a comment node
(nod.nodeType === 3 && isAllWs(nod))
); // a text node, all ws
}
/**
* Version of `previousSibling` that skips nodes that are entirely
* whitespace or comments. (Normally `previousSibling` is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return The closest previous sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null` if
* no such node exists.
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `nextSibling` that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return The closest next sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null`
* if no such node exists.
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `lastChild` that skips nodes that are entirely
* whitespace or comments. (Normally `lastChild` is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return The last child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of `firstChild` that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return The first child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of `data` that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* `data` is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
The following code demonstrates the use of the functions above. It iterates over the children of an element (whose children are all elements) to find the one whose text is "This is the third paragraph", and then changes the class attribute and the contents of that paragraph.
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = nodeAfter(cur);
}