ウェブオーディオ API に関わる基本概念
この記事では、アプリを経由したオーディオ伝達方法の設計をする際に、十分な情報に基づいた決断をする助けとなるよう、ウェブオーディオ API の特徴がいかに働いているか、その背後にあるオーディオ理論について説明します。この記事はあなたを熟練のサウンドエンジニアにさせることはできないものの、ウェブオーディオ API が動く理由を理解するための十分な背景を提供します。
オーディオグラフ
ウェブオーディオ API は、オーディオコンテキスト内部でのオーディオ操作に対する処理を含み、モジュラールーティングを可能とするために設計されてきました。それぞれのオーディオノードは基本的なオーディオ処理を行い、他の 1 つ以上のオーディオノードと連結されて、オーディオルーティンググラフを形成します。1つのコンテキスト内であっても、異なるチャンネル構成を持つ複数の音源に対応しています。このモジュール式の設計により、ダイナミックなエフェクトを備えた複雑なオーディオ機能を作成するための柔軟性が確保されています。
オーディオノードは、それら入出力を経由し接続され、単一あるいは複数の音源から開始される一連のチェーンを作り、一つ以上のノードを経由しつつ、最終的な行き先に届き終了します。ただし、たとえば、オーディオデータを視覚化することのみを求める場合などは、このような宛先は省いて構いません。シンプルで典型的なウェブオーディオのワークフローでは、以下のようになります。
- オーディオコンテキストを作成します。
- コンテキスト内に音源を生成します(
<audio>、オシレーター、ストリームなど)。 - リバーブ、バイカッドフィルター、パンナーコンプレッサーといった、音響効果用ノードを作成します。
- オーディオの最終出力先(ユーザーのコンピューターのスピーカーなど)を選択します。
- 音源ノードを 0 個以上のエフェクトノードに接続し、その後、選択した宛先ノードに接続します。
メモ: 信号上で利用できるオーディオチャンネルの数字は、2.0 や 5.1 のように、しばしば、数値の形式で表現されます。これはチャンネル数表記と呼ばれます。最初の数値は、該当の信号が含んでいるオーディオチャンネルの数です。ピリオドの後にある数値は、低音増強用出力として確保されているチャンネルの数を示しています。それらはしばしばサブウーファーとも称されます。

各入出力は、互いに特定のオーディオレイアウトを代表する、一つ以上のオーディオチャンネルにより構成されます。個別のチャンネル構造それぞれは、モノラル、ステレオ、クアッド、5.1 等を含んでサポートされています。

オーディオはいくつかの方法で取得できます。
- JavaScript 内部で(オシレーターのような)オーディオノードにより、直接オーディオを生成。
- 未加工の PCM データから生成(この場合、該当オーディオコンテキストは、対応しているオーディオフォーマット形式へのデコード手段を有しています)。
- (
<video>や<audio>のような)HTML のメディア要素より取得。 - (ウェブカメラやマイクのような)WebRTC
MediaStreamにより直接取得。
オーディオデータ: サンプルとは?
オーディオ信号が処理されるとき、サンプリングが行われます。サンプリングとは連続信号を離散信号へ変換することです。あるいは別の言い方をすると、バンドのライブ演奏のような連続的な音波を、コンピューターがそのオーディオを区別されたブロックで処理できるようになる(離散時間信号の)一連のサンプルに変換します。
より詳しい情報は、ウィキペディアの標本化から見ることができます。
オーディオバッファー: フレーム、サンプル、チャンネルセクション
AudioBuffer は、次の 3 つのパラメータで定義されます。
- チャンネル数(モノラルは 1、ステレオは 2 など)、
- バッファ内のサンプルフレーム数、
- サンプルレート(1 秒あたりに再生されるサンプルフレーム数)。
サンプルとは、特定のチャンネル(ステレオの場合は左または右)内の特定の時点におけるオーディオストリームの値を表す、単一の 32 ビット浮動小数点値のことです。フレーム、またはサンプルフレームとは、特定の時点において再生されるすべてのチャンネルの値の集合のことです。つまり、同時に再生されるすべてのチャンネルのすべてのサンプル(ステレオ音源の場合は 2 つ、5.1ch の場合は 6 つなど)を指します。
サンプルレートとは、1 秒間に再生される、それらサンプルの数(または、1 フレームのサンプルすべてが同時に再生させることから、フレーム)であり、単位は Hz で測定されます。サンプルレートが高まるにつれ、音質は向上します。
モノラルとステレオのオーディオバッファーを見てみましょう。それらは 1 秒間、44100Hz で再生されます。
- モノラルバッファーは 44100 サンプル、44100 フレームで構成され、length プロパティは 44100 となる。
- ステレオバッファーは 88200 サンプル、44100 フレームで構成され、length プロパティは、そのフレーム数に等しいため 44100 のままである。

バッファが再生されると、最も左のサンプルフレームが聞こえ、次にそのサンプルフレームのすぐ隣のサンプルフレームが続いてゆきます。ステレオの場合、両方のチャンネルから同時に聴こえます。サンプルフレームは、チャンネルの数とは独立しているため非常に便利であり、正確にオーディオを取り扱う有効な手段として、時間を表現してくれます。
メモ: フレーム数から秒数を得るためには、フレーム数をサンプルレートで単に除算するだけです。サンプル数からフレーム数を得るためには、チャンネル数で単に除算するだけです。
以下はいくつかの単純なサンプルです。
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 2,
length: 22050,
sampleRate: 44100,
});
メモ: デジタルオーディオにおいて、44100Hz(44.1kHz とも表記される)は一般的なサンプリング周波数です。なぜ 44.1kHz なのでしょう?
第一に、人間の耳の可聴域は、およそ 20 から 20000Hz の範囲です。Nyquist-Shannon のサンプリング定理により、サンプリング周波数は再現したい最大周波数の 2 倍以上でなくてはなりません。したがって、サンプリングレートは 40kHz 以上でなくてはなりません。
第二に、信号はサンプリング前に、偽信号の発生をさせないため、ローパスフィルタリングされていなければなりません。理想的ローパスフィルターが 20kHz 以下の周波数を(減衰させずに)完璧に通し、20kHz 以上の周波数を完璧に遮断する一方で、実際には、周波数が部分的に減衰する場所となる、トランジションバンド(英語)が必要です。このバンドが広くなるにつれ、アンチエイリアスフィルターを作るのは簡単かつ効率的になります。44.1kHz サンプリング周波数は、2.05kHz のトランジションバンドを与えます。
この呼び出しをする場合、チャンネル数 2 のステレオバッファーを取得し、AudioContext 上で(非常に一般的で、通常のサウンドカードではほとんどはレートとなる)44100Hz にて再生される音源が、0.5 秒間続きます: 22,050 フレーム/44,100Hz = 0.5 秒。
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 1,
length: 22050,
sampleRate: 22050,
});
この呼び出しをする場合、モノラルバッファーをチャンネル数 1 で取得し、AudioContext 上で 44100Hz にて再生される際に自動で 44100Hz へ再サンプリングされ(したがって 44100 フレームとなり)、1 秒間続きます: 44100 フレーム/44100Hz = 1 秒。
メモ: オーディオの再サンプリングは、画像のサイズ変更とよく似たものです。例えば 16x16 の画像があり、32x32 の空間を満たしたいとします。サイズ変更(あるいは再サンプリング)を行い、結果として(サイズ変更アルゴリズムの違いに依存して、エッジがぼやけたりと)画質の低下を伴いますが、空間を減らすサイズ変更済み画像が作れます。再サンプリングされたオーディオもまったく同じです。空間を保てるものの、実際には高音域のコンテンツや高音を適切に再現することはできません。
バッファーセクションの平面性対交差性
ウェブオーディオ API は平面的なバッファー形式を採用しています。左右のチャンネルは、以下のように格納されています。
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (16 フレームのバッファー)
これはオーディオ処理における一般的な形式です。これにより各チャンネルの独立した処理が簡単になります。
代替方式としては、交差的な形式が用いられます。
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (16 フレームのバッファー)
この形式は、大掛かりな処理を必要としないオーディオを、格納し再生する目的として一般的です。例えばデコード済み MP3 音楽ストリームなどがあります。
ウェブオーディオ API は、オーディオ処理に適することを理由に、平面的なバッファーのみを採用しています。通常は平面的ですが、再生用にオーディオがサウンドカードへ送られる際は、交差的に変換されます。反対に、MP3 オーディオがデコードされる場合、元々は交差形式だったものの、オーディオ処理のため平面形式へと変換されます。
オーディオチャンネル
異なるオーディオバッファーでは、それぞれ異なった数のチャンネルを含んでいます: より基本的なモノラルとステレオ(それぞれチャンネル数 1 と 2)から始まり、より複雑なクアッドもしくは 5.1 のような、異なるサウンドサンプルが各チャンネルに含まれ、よりリッチなオーディオ体験を導くセットもあります。チャンネルは通常、以下のテーブルに示される、標準的な略語によって示されます:
| 名前 | チャンネル |
|---|---|
| Mono | 0: M: mono |
| Stereo | 0: L: left 1: R: right |
| Quad | 0: L: left 1: R: right 2: SL: surround left 3: SR: surround right |
| 5.1 | 0: L: left 1: R: right 2: C: center 3: LFE: subwoofer 4: SL: surround left 5: SR: surround right |
アップミキシングとダウンミキシング
入力と出力のチャンネル数が一致しない場合、以下のルールに基づいてアップミキシングまたはダウンミキシングが行われます。これはAudioNode.channelInterpretation プロパティを speakers または discrete へとセットしてコントロールできます。
| 解釈 | 入力チャンネル | 出力チャンネル | ミキシングルール |
|---|---|---|---|
speakers |
1 (Mono) |
2 (Stereo) |
モノラルからステレオへのアップミックス。M入力チャンネルは(L と
R の)両出力チャンネル用に使われます。output.L = input.M
|
1 (Mono) |
4 (Quad) |
モノラルからクアッドへのアップミックス。M
入力チャンネルは(L と
R の)ノンサラウンド出力チャンネル用に使われます。(SL
と SR の)サラウンド出力チャンネルは無音です。output.L = input.M
|
|
1 (Mono) |
6 (5.1) |
モノラルから 5.1.へのアップミックス。M
入力チャンネルは(C
の)ノン中央出力チャンネル用に使われます。その他すべての(L,
R, LFE, SL,
SR)出力チャンネルは無音です。output.L = 0output.C = input.M
|
|
2 (Stereo) |
1 (Mono) |
ステレオからモノラルへのダウンミックス。 ( L
と
R
の)両入力チャンネルは等しく結合され、単一出力チャンネル(M)になります。output.M = 0.5 * (input.L + input.R)
|
|
2 (Stereo) |
4 (Quad) |
ステレオからクアッドへのアップミックス。 左右( L
と R)入力チャンネルはそれぞれ(L と
R の)ノンサラウンド出力チャンネル用に使われます。(SL
と SR の)サラウンド出力チャンネルは無音です。output.L = input.L
|
|
2 (Stereo) |
6 (5.1) |
ステレオから 5.1.へのアップミックス。 左右( L
と R)入力チャンネルはそれぞれ(L と
R の)ノンサラウンド出力チャンネル用に使われます。(SL
と
SR
の)サラウンド出力チャンネル、中央チャンネル(C)、サブウーファー(LFE)はすべて同様に無音です。output.L = input.L
|
|
4 (Quad) |
1 (Mono) |
クアッドからモノラルへのダウンミックス。 ( L,
R, SL,
SR)入力チャンネルは等しく結合され、単一出力チャンネル(M)になります。output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (Quad) |
2 (Stereo) |
クアッドからステレオへのダウンミックス。両左入力チャンネル ( L と
SL)は等しく結合され、単一左出力チャンネル(L)になります。同様に、両右入力チャンネル(R
と
SR)は等しく結合され、単一右出力チャンネル(R)になります。output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (Quad) |
6 (5.1) |
クアッドから 5.1.へのアップミックス。 ( L,
R, SL,
SR)入力チャンネルはそれぞれ(L と
R
の)出力チャンネル用に使われます。中央チャンネル(C)、サブウーファー(LFE)は無音です。output.L = input.L
|
|
6 (5.1) |
1 (Mono) |
5.1.からモノラルへのダウンミックス。左チャンネル(L, SL)、右チャンネル(R,
SR)、中央チャンネルはそれぞれ混合されます。サラウンドチャンネルは僅かに減衰され、標準側面チャンネルは利用のために、単一チャンネルを√2/2
で乗算したものとして出力が補強されます。サブウーファー(LFE)チャンネルは失われます。output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL +
input.SR)
|
|
6 (5.1) |
2 (Stereo) |
5.1.からステレオへのダウンミックス。 中央チャンネルは各側面サラウンドチャンネル( SL と
SR)と合算され、各側面チャンネルへ混合されます。2
チャンネルへとミックスダウンされる過程は低労力で行われ、各々の場合について、√2/2
で乗算されます。サブウーファー (LFE)
チャンネルは失われます。output.L = input.L + 0.7071 * (input.C + input.SL)+ 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (Quad) |
5.1.からクアッドへのダウンミックス。 中央チャンネルは各側面ノンサラウンドチャンネル( L と
R)と合算され、各側面チャンネルへ混合されます。2
チャンネルへとミックスダウンされる過程は低労力で行われ、各々の場合について、√2/2
で乗算されます。サラウンドチャンネルへの伝達には変化がありません。サブウーファー
(LFE) チャンネルは失われます。output.L = input.L + 0.7071 * input.C
|
|
| その他、非標準レイアウト |
非標準チャンネルレイアウトは channelInterpretation を discrete に設定したものとして操作されます。新たなスピーカーレイアウトの将来的な定義を、仕様書でははっきりと認めています。従ってこの予備部分は、チャンネルに用いられる特定の数字が示すブラウザーの挙動が、将来的に変更された場合のために用意されたものではありません。 |
||
discrete |
各 (x) |
各 (y) (x<y の場合) |
離散チャンネルのアップミックス。 各出力チャンネルに、それに対応する同番号の入力チャンネルによる入力をします。対応する入力チャンネルが存在しないチャンネルは無音になります。 |
各 (x) |
各 (y) (x>y の場合) |
離散チャンネルのダウンミックス。 各出力チャンネルに、それに対応する同番号の入力チャンネルによる入力をします。対応する出力チャンネルが存在しない入力チャンネルは無視されます。 |
|
視覚化
原則、オーディオ視覚化は出力オーディオデータ(基本的にはゲインまたは周波数データ)に時間毎にアクセスすることで行われ、更にグラフなどの視覚化出力へ渡すためのグラフィカル技術が用いられます。ウェブオーディオ API は AnalyserNode で、経由して渡されたオーディオ信号を変換せず利用することができます。ただしその出力は、<canvas> などのような視覚化技術へ受け渡せるオーディオデータです。

以下のメソッドを利用して、データの取得が可能です。
AnalyserNode.getFloatFrequencyData()-
現在の周波数データを渡された
Float32Array型配列にコピーします。 AnalyserNode.getByteFrequencyData()-
現在の周波数データを渡された
Uint8Array型配列(符号なしバイト配列)にコピーします。 AnalyserNode.getFloatTimeDomainData()-
現在の波形データまたはタイムドメインデータを渡された
Float32Array型配列にコピーします。 AnalyserNode.getByteTimeDomainData()-
現在の波形データまたはタイムドメインデータを渡された
Uint8Array型配列(符号なしバイト配列)にコピーします。
メモ: より詳しい情報は、ウェブオーディオ API 記事中の ウェブオーディオ API による視覚化を参照してください。
立体化
(ウェブオーディオ API の PannerNode と AudioListener ノードによって操作される)立体音響化によって、オーディオ信号の、空間を介した点における位置や振る舞いをモデル化することができ、そのオーディオをリスナーが聞くことができます。
パンナーの位置は、直行座標の右側に描かれています。ドップラー効果を作るに必要な、速度ベクトルを用いた移動、そして方向コーンを用いた方向性があります。このコーンは、例えば無指向性音源などのため、とても大きくなり得ます。

リスナーの位置は、直行座標の右側に描かれています。度ベクトルを用いた移動と、リスナーの頭がポイントされている(頭部側と顔面側の)二方向ベクターを用いた方向性があります。これらはそれぞれリスナーの頭部の頂点からの方向と、リスナーの鼻にポイントされている方向とを定義しており、これらは直角となっています。
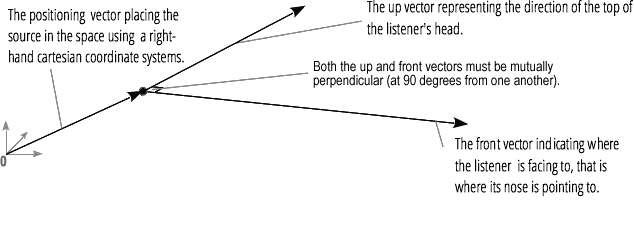
メモ: より詳しい情報は、ウェブオーディオの空間化の基礎を参照してください。
ファンインとファンアウト
オーディオ用語では、fan-in はChannelMergerNode が一連の単一入力ソースを受け、単一マルチチャンネル信号を出力するプロセスを意味します。

Fan-out はその対となるプロセスを意味します。ChannelSplitterNode が一つのマルチチャンネル入力源を受け、複数のモノラル出力信号を出力します。
