Grundlegende Konzepte hinter der Web Audio API
Dieser Artikel erklärt einige theoretische Grundlagen der Audioverarbeitung, um zu verstehen, wie die Funktionen der Web Audio API arbeiten. Dies wird Ihnen helfen, fundierte Entscheidungen zu treffen, wenn Sie Ihre App zur Verarbeitung von Audio entwerfen. Wenn Sie noch kein Tontechniker sind, gibt Ihnen dieser Artikel genügend Hintergrundwissen, um zu verstehen, warum die Web Audio API so funktioniert, wie sie es tut.
Audiographen
Die Web Audio API beinhaltet die Verarbeitung von Audiooperationen innerhalb eines Audio-Kontextes und wurde entwickelt, um modulare Signalführung zu ermöglichen. Jeder Audio-Knoten führt eine grundlegende Audiooperation durch und ist mit einem oder mehreren anderen Audio-Knoten verbunden, um einen Audio-Routing-Graphen zu bilden. Mehrere Quellen mit unterschiedlichen Kanal-Layouts werden unterstützt, sogar innerhalb eines einzigen Kontexts. Dieses modulare Design bietet die Flexibilität, komplexe Audiofunktionen mit dynamischen Effekten zu erstellen.
Audio-Knoten sind über ihre Ein- und Ausgänge verbunden und bilden eine Kette, die mit einer oder mehreren Quellen beginnt, durch einen oder mehrere Knoten verläuft und dann an einem Ziel endet (obwohl Sie kein Ziel angeben müssen, wenn Sie nur einige Audiodaten visualisieren möchten). Ein einfacher, typischer Workflow für Web-Audio würde in etwa so aussehen:
- Erstellen Sie den Audio-Kontext.
- Erstellen Sie Audioquellen innerhalb des Kontexts (wie
<audio>, einen Oszillator oder Stream). - Erstellen Sie Audioeffekte (wie die Hall-, Biquad-Filter-, Panner-, oder Kompressor-Knoten).
- Wählen Sie das endgültige Ziel für das Audio (wie die Lautsprecher des Benutzers).
- Verbinden Sie die Quellknoten mit null oder mehr Effekt-Knoten und dann mit dem gewählten Ziel.
Hinweis: Die Kanalnotation ist ein numerischer Wert, wie 2.0 oder 5.1, der die Anzahl der Audiokanäle angibt, die in einem Signal verfügbar sind. Die erste Zahl ist die Anzahl der Audiokanäle im vollen Frequenzbereich, die das Signal enthält. Die Zahl nach dem Punkt steht für die Anzahl der Kanäle, die für den Low-Frequency-Effekt (LFE) reserviert sind; diese werden oft als Subwoofer bezeichnet.

Jeder Eingang oder Ausgang besteht aus einem oder mehreren Audio-Kanälen, die zusammen ein bestimmtes Audio-Layout darstellen. Jede diskrete Kanalstruktur wird unterstützt, einschließlich Mono, Stereo, Quad, 5.1 usw.

Es gibt mehrere Möglichkeiten, um Audio zu erhalten:
- Der Sound kann direkt in JavaScript von einem Audio-Knoten (wie einem Oszillator) generiert werden.
- Er kann aus rohen PCM-Daten erstellt werden (zum Beispiel .WAV-Dateien oder andere Formate, die von
decodeAudioData()unterstützt werden). - Er kann von HTML-Media-Elementen wie
<video>oder<audio>generiert werden. - Er kann von einem WebRTC
MediaStreamwie einer Webcam oder einem Mikrofon erlangt werden.
Audiodaten: Was in einem Sample steckt
Wenn ein Audiosignal verarbeitet wird, erfolgt eine Abtastung. Abtastung ist die Umwandlung eines kontinuierlichen Signals in ein diskretes Signal. Anders ausgedrückt, eine kontinuierliche Schallwelle, wie sie von einer Band live gespielt wird, wird in eine Abfolge von digitalen Samples (ein diskretes Zeitsignal) umgewandelt, die es einem Computer ermöglichen, das Audio in getrennten Blöcken zu verarbeiten.
Weitere Informationen finden Sie auf der Wikipedia-Seite Abtastung (Signalverarbeitung).
Audiopuffer: Frames, Samples und Kanäle
Ein AudioBuffer ist mit drei Parametern definiert:
- der Anzahl der Kanäle (1 für Mono, 2 für Stereo usw.),
- seiner Länge, also der Anzahl der Sample-Frames im Puffer,
- und der Abtastrate, der Anzahl der Sample-Frames, die pro Sekunde abgespielt werden.
Ein Sample ist ein einzelner 32-Bit-Gleitkommawert, der den Wert des Audio-Streams zu jedem bestimmten Zeitpunkt innerhalb eines bestimmten Kanals (links oder rechts, im Fall von Stereo) repräsentiert. Ein Frame oder Sample-Frame ist die Menge aller Werte für alle Kanäle, die zu einem bestimmten Zeitpunkt abgespielt werden: alle Samples aller Kanäle, die zur gleichen Zeit abgespielt werden (zwei für einen Stereo-Sound, sechs für 5.1 usw.).
Die Abtastrate ist die Menge dieser Samples (oder Frames, da alle Samples eines Frames gleichzeitig abgespielt werden), die in einer Sekunde abgespielt werden und wird in Hz gemessen. Je höher die Abtastrate, desto besser die Klangqualität.
Schauen wir uns einen Mono und einen Stereo Audiopuffer an, die jeweils eine Sekunde lang bei einer Rate von 44100Hz sind:
- Der Mono-Puffer hat 44.100 Samples und 44.100 Frames. Die Eigenschaft
lengthwird 44.100 sein. - Der Stereo-Puffer hat 88.200 Samples, aber immer noch 44.100 Frames. Die Eigenschaft
lengthwird immer noch 44.100 sein, da sie gleich der Anzahl der Frames ist.

Wenn ein Puffer abgespielt wird, hören Sie zuerst den ganz links befindlichen Sample-Frame, dann den direkt daneben, dann den nächsten und so weiter bis zum Ende des Puffers. Im Fall von Stereo hören Sie beide Kanäle gleichzeitig. Sample-Frames sind praktisch, da sie unabhängig von der Anzahl der Kanäle sind und die Zeit auf ideale Weise für präzise Audiomanipulation darstellen.
Hinweis: Um eine Zeit in Sekunden aus einer Frame-Anzahl zu berechnen, teilen Sie die Anzahl der Frames durch die Abtastrate. Um die Anzahl der Frames aus der Anzahl der Samples zu berechnen, müssen Sie nur den letzteren Wert durch die Anzahl der Kanäle teilen.
Hier sind einige einfache Beispiele:
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 2,
length: 22050,
sampleRate: 44100,
});
Hinweis: In digitaler Audioverarbeitung ist 44.100 Hz (alternativ dargestellt als 44,1 kHz) eine gängige Abtastfrequenz. Warum 44,1 kHz?
Erstens, weil der Hörbereich des menschlichen Ohrs ungefähr von 20 Hz bis 20.000 Hz reicht. Gemäß dem Nyquist-Shannon-Abtasttheorem muss die Abtastfrequenz größer sein als das Doppelte der maximalen Frequenz, die man reproduzieren möchte. Daher muss die Abtastrate größer als 40.000 Hz sein.
Zweitens müssen Signale Tiefpass-gefiltert werden, bevor sie abgetastet werden, andernfalls tritt Aliasing auf. Während ein idealer Tiefpassfilter perfekt Frequenzen unter 20 kHz durchlassen würde (ohne sie zu dämpfen) und Frequenzen über 20 kHz perfekt abschneiden würde, ist in der Praxis ein Übergangsbereich notwendig, in dem Frequenzen teilweise gedämpft werden. Je breiter dieser Übergangsbereich ist, desto einfacher und wirtschaftlicher ist es, einen Antialiasing-Filter herzustellen. Die Abtastfrequenz von 44,1 kHz ermöglicht einen Übergangsbereich von 2,05 kHz.
Wenn Sie den obigen Aufruf verwenden, erhalten Sie einen Stereo-Puffer mit zwei Kanälen, der beim Abspielen auf einem AudioContext, der bei 44.100 Hz läuft (sehr häufig, die meisten normalen Soundkarten laufen mit dieser Rate), 0,5 Sekunden dauert: 22.050 Frames/44.100 Hz = 0,5 Sekunden.
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 1,
length: 22050,
sampleRate: 22050,
});
Wenn Sie diesen Aufruf verwenden, erhalten Sie einen Mono-Puffer (Einkanal-Puffer), der beim Abspielen auf einem AudioContext, der bei 44.100 Hz läuft, automatisch auf 44.100 Hz neu abgetastet wird (und daher 44.100 Frames ergibt) und 1,0 Sekunde dauert: 44.100 Frames/44.100 Hz = 1 Sekunde.
Hinweis: Audio-Resampling ist dem Bild-Resizing sehr ähnlich. Sagen Sie, Sie haben ein 16 x 16 Bild, möchten es aber auf einen 32 x 32 Bereich füllen. Sie passen es an (oder ändern die Abtastung). Das Ergebnis hat weniger Qualität (es kann unscharf oder kantig sein, je nach Resize-Algorithmus), aber es funktioniert, wobei das angepasste Bild weniger Speicherplatz benötigt. Neugewonnenes Audio ist dasselbe: Sie sparen Speicherplatz, aber in der Praxis können Sie keine hochfrequenten Inhalte oder hohe Töne korrekt reproduzieren.
Planare versus verschachtelte Puffer
Die Web Audio API verwendet ein planares Pufferformat. Die linken und rechten Kanäle werden so gespeichert:
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (for a buffer of 16 frames)
Diese Struktur ist in der Audiobearbeitung weit verbreitet und erleichtert die unabhängige Bearbeitung jedes Kanals.
Die Alternative ist die Verwendung eines verschachtelten Pufferformats:
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (for a buffer of 16 frames)
Dieses Format ist häufig für die Speicherung und Wiedergabe von Audio ohne große Bearbeitung, zum Beispiel: .WAV-Dateien oder ein decodierter MP3-Stream.
Da die Web Audio API auf die Verarbeitung ausgelegt ist, bietet sie nur planare Puffer. Sie verwendet das planare Format, konvertiert das Audio jedoch beim Senden an die Soundkarte zur Wiedergabe in ein verschachteltes Format. Umgekehrt, wenn die API einen MP3 decodiert, beginnt sie mit dem verschachtelten Format und wandelt es zur Verarbeitung in das planare Format um.
Audiokanäle
Jeder Audiopuffer kann unterschiedliche Anzahlen von Kanälen enthalten. Die meisten modernen Audiogeräte verwenden die grundlegenden Mono- (nur ein Kanal) und Stereo- (linke und rechte Kanäle) Einstellungen. Einige komplexere Geräte unterstützen Surround Sound-Einstellungen (wie Quad und 5.1), was zu einem reichhaltigeren Klangerlebnis führen kann, dank ihrer hohen Kanalanzahl. Wir repräsentieren die Kanäle in der Regel mit den standardmäßigen Abkürzungen, die in der folgenden Tabelle aufgeführt sind:
| Name | Kanäle |
|---|---|
| Mono | 0: M: mono |
| Stereo | 0: L: links 1: R: rechts |
| Quad | 0: L: links 1: R: rechts 2: SL: surround links 3: SR: surround rechts |
| 5.1 | 0: L: links 1: R: rechts 2: C: center 3: LFE: subwoofer 4: SL: surround links 5: SR: surround rechts |
Up-Mixing und Down-Mixing
Wenn die Anzahl der Kanäle des Eingangs und des Ausgangs nicht übereinstimmen, muss ein Up-Mixing oder Down-Mixing durchgeführt werden. Die folgenden Regeln, die durch die Einstellung der AudioNode.channelInterpretation-Eigenschaft auf speakers oder discrete gesteuert werden, gelten:
| Interpretation | Eingangskanäle | Ausgangskanäle | Mixing-Regeln |
|---|---|---|---|
speakers |
1 (Mono) |
2 (Stereo) |
Up-Mix von Mono zu Stereo. Der M-Eingangskanal
wird für beide Ausgangskanäle (L und R) verwendet.output.L = input.M
|
1 (Mono) |
4 (Quad) |
Up-Mix von Mono zu Quad. Der M-Eingangskanal
wird für die nicht-surround-Ausgangskanäle (L und R)
verwendet. Surround-Ausgangskanäle (SL und SR)
sind stumm.output.L = input.M
|
|
1 (Mono) |
6 (5.1) |
Up-Mix von Mono zu 5.1. Der M-Eingangskanal
wird für den Center-Ausgangskanal (C) verwendet. Alle
anderen (L, R, LFE, SL,
und SR) sind stumm.output.L = 0output.C = input.M
|
|
2 (Stereo) |
1 (Mono) |
Down-Mix von Stereo zu Mono. Beide Eingangskanäle ( L
und R) werden gleichmäßig kombiniert, um den einzigen Ausgangskanal
(M) zu erzeugen.output.M = 0.5 * (input.L + input.R)
|
|
2 (Stereo) |
4 (Quad) |
Up-Mix von Stereo zu Quad. Die L- und
R-Eingangskanäle werden für ihre nicht-surround entsprechenden
Ausgangskanäle (L und R) verwendet. Surround-Ausgangskanäle
(SL und SR) sind stumm.output.L = input.L
|
|
2 (Stereo) |
6 (5.1) |
Up-Mix von Stereo zu 5.1. Die L- und
R-Eingangskanäle werden für ihre nicht-surround entsprechenden
Ausgangskanäle (L und R) verwendet. Surround-Ausgangskanäle
(SL und SR), sowie die Center (C)
und Subwoofer (LFE) Kanäle sind stumm.output.L = input.L
|
|
4 (Quad) |
1 (Mono) |
Down-Mix von Quad zu Mono. Alle vier Eingangskanäle ( L, R, SL, und SR)
werden gleichmäßig kombiniert, um den einzigen Ausgangskanal
(M) zu erzeugen.output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (Quad) |
2 (Stereo) |
Down-Mix von Quad zu Stereo. Beide linken Eingangskanäle ( L und SL) werden gleichmäßig kombiniert, um den
einzigen linken Ausgangskanal (L) zu erzeugen. Und ähnlich
werden beide rechten Eingangskanäle (R und SR)
gleichmäßig kombiniert, um den einzigen rechten Ausgangskanal
(R) zu erzeugen.output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (Quad) |
6 (5.1) |
Up-Mix von Quad zu 5.1. Die L,
R, SL, und SR-Eingangskanäle werden
für ihre entsprechenden Ausgangskanäle (L und R)
verwendet. Center (C) und Subwoofer (LFE) Kanäle
sind stumm.output.L = input.Loutput.R = input.Routput.C = 0output.LFE = 0output.SL = input.SLoutput.SR = input.SR
|
|
6 (5.1) |
1 (Mono) |
Down-Mix von 5.1 zu Mono. Die linken ( L und
SL), rechten (R und SR) und
zentralen Kanäle werden alle zusammengemischt. Die Surround-Kanäle sind
leicht gedämpft, und die regulären seitlichen Kanäle werden leistungskompensiert,
um sie als einen einzigen Kanal zu zählen, indem sie mit √2/2
multipliziert werden. Der Subwoofer (LFE) Kanal geht verloren.output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
|
|
6 (5.1) |
2 (Stereo) |
Down-Mix von 5.1 zu Stereo. Der zentrale Kanal ( C)
wird mit jedem seitlichen Surround-Kanal (SL oder SR)
summiert und zu jedem seitlichen Kanal gemischt. Da es auf zwei Kanäle
heruntergemischt wird, wird es mit einer niedrigeren Leistung gemischt: in
jedem Fall wird es mit √2/2 multipliziert. Der Subwoofer
(LFE) Kanal geht verloren.output.L = input.L + 0.7071 * (input.C + input.SL)output.R = input.R + 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (Quad) |
Down-Mix von 5.1 zu Quad. Der zentrale ( C)
wird mit den seitlichen nicht-surround Kanälen (L und
R) gemischt. Da es auf zwei Kanäle heruntergemischt wird, wird
es mit einer niedrigeren Leistung gemischt: in jedem Fall wird es mit
√2/2 multipliziert. Die Surround-Kanäle werden unverändert
weitergeben. Der Subwoofer (LFE) Kanal geht verloren.output.L = input.L + 0.7071 * input.Coutput.R = input.R + 0.7071 * input.Coutput.SL = input.SLoutput.SR = input.SR
|
|
| Andere, nicht standardmäßige Layouts |
Nicht-standardmäßige Kanal-Layouts verhalten sich so, als ob
channelInterpretation auf
discrete gesetzt ist.Die Spezifikation erlaubt ausdrücklich die zukünftige Definition neuer Lautsprecher-Layouts. Daher ist dieser Fallback nicht zukunftssicher, da das Verhalten der Browser für eine bestimmte Anzahl von Kanälen sich in Zukunft ändern kann. |
||
discrete |
beliebig (x) |
beliebig (y) wobei x<y |
Up-Mix diskrete Kanäle. Füllen Sie jeden Ausgangskanal mit seinem Eingabepartner — das heißt, dem Eingangskanal mit dem gleichen Index. Kanäle ohne entsprechende Eingangskanäle bleiben stumm. |
beliebig (x) |
beliebig (y) wobei x>y |
Down-Mix diskrete Kanäle. Füllen Sie jeden Ausgangskanal mit seinem Eingabepartner — das heißt, dem Eingangskanal mit dem gleichen Index. Eingangskanäle ohne entsprechende Ausgangskanäle werden fallen gelassen. |
|
Visualisierungen
Im Allgemeinen erhalten wir den Ausgang im Laufe der Zeit, um Audio-Visualisierungen zu erzeugen, normalerweise durch Lesen der Verstärkung oder Frequenzdaten. Dann verwenden wir ein grafisches Werkzeug, um die gewonnenen Daten in eine visuelle Darstellung, wie ein Diagramm, umzuwandeln. Die Web Audio API verfügt über einen AnalyserNode, der das durchlaufende Audiosignal nicht verändert. Darüber hinaus gibt er die Audiodaten aus, was uns ermöglicht, sie mit einer Technologie wie <canvas> zu verarbeiten.

Sie können Daten mit den folgenden Methoden abrufen:
AnalyserNode.getFloatFrequencyData()-
Kopiert die aktuellen Frequenzdaten in ein übergebenes
Float32ArrayArray. AnalyserNode.getByteFrequencyData()-
Kopiert die aktuellen Frequenzdaten in ein übergebenes
Uint8Array(unsigned Byte Array). AnalyserNode.getFloatTimeDomainData()-
Kopiert die aktuelle Wellenform oder Zeit-Domänendaten in ein übergebenes
Float32ArrayArray. AnalyserNode.getByteTimeDomainData()-
Kopiert die aktuelle Wellenform oder Zeit-Domänendaten in ein übergebenes
Uint8Array(unsigned Byte Array).
Hinweis: Für weitere Informationen, siehe unseren Visualisierungen mit der Web Audio API Artikel.
Raumklang
Die Audio-Raumklangerweiterung ermöglicht uns, die Position und das Verhalten eines Audiosignals an einem bestimmten Punkt im physischen Raum zu modellieren, um zu simulieren, dass der Zuhörer dieses Audio hört. In der Web Audio API wird die Raumklangerweiterung durch den PannerNode und den AudioListener behandelt.
Der Panner verwendet ein kartesisches Koordinatensystem, um die Position der Audioquelle als Vektor und ihre Orientierung als 3D-Richtkegel zu beschreiben. Der Kegel kann ziemlich groß sein, zum Beispiel für omnidirektionale Quellen.

Ebenso beschreibt die Web Audio API den Zuhörer mit einem kartesischen Koordinatensystem: Seine Position als Vektor und seine Orientierung als zwei Richtungsvektoren, oben und vorne. Diese Vektoren definieren die Richtung des Kopfes des Zuhörers und die Richtung, in die die Nase des Zuhörers zeigt. Die Vektoren sind zueinander senkrecht.
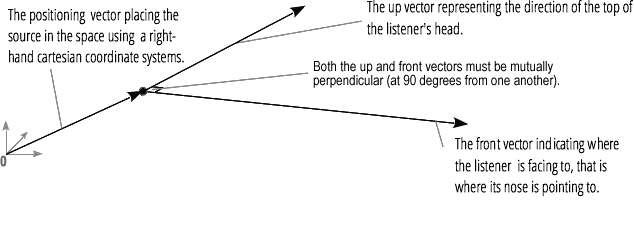
Hinweis: Für weitere Informationen, siehe unseren Basislehrgang zur Web-Audio-Raumklangverarbeitung Artikel.
Fan-in und Fan-out
Im Audiobereich beschreibt Fan-in den Vorgang, bei dem ein ChannelMergerNode eine Serie von Mono-Eingangsquellen aufnimmt und ein einziges Mehrkanalsignal als Ausgang erzeugt:

Fan-out beschreibt den entgegengesetzten Vorgang, bei dem ein ChannelSplitterNode eine Mehrkanal-Eingangsquelle aufnimmt und mehrere Mono-Ausgangssignale erzeugt:
