Basic concepts behind Web Audio API
This article explains some of the audio theory behind how the features of the Web Audio API work to help you make informed decisions while designing how your app routes audio. If you are not already a sound engineer, it will give you enough background to understand why the Web Audio API works as it does.
Audio graphs
The Web Audio API involves handling audio operations inside an audio context, and has been designed to allow modular routing. Each audio node performs a basic audio operation and is linked with one more other audio nodes to form an audio routing graph. Several sources with different channel layouts are supported, even within a single context. This modular design provides the flexibility to create complex audio functions with dynamic effects.
Audio nodes are linked via their inputs and outputs, forming a chain that starts with one or more sources, goes through one or more nodes, then ends up at a destination (although you don't have to provide a destination if you only want to visualize some audio data). A simple, typical workflow for web audio would look something like this:
- Create the audio context.
- Create audio sources inside the context (such as
<audio>, an oscillator, or stream). - Create audio effects (such as the reverb, biquad filter, panner, or compressor nodes).
- Choose the final destination for the audio (such as the user's computer speakers).
- Connect the source nodes to zero or more effect nodes and then to the chosen destination.
Note: The channel notation is a numeric value, such as 2.0 or 5.1, representing the number of audio channels available on a signal. The first number is the number of full frequency range audio channels the signal includes. The number appearing after the period indicates the number of those channels reserved for low-frequency effect (LFE) outputs; these are often called subwoofers.

Each input or output is composed of one or more audio channels, which together represent a specific audio layout. Any discrete channel structure is supported, including mono, stereo, quad, 5.1, and so on.

You have several ways to obtain audio:
- Sound can be generated directly in JavaScript by an audio node (such as an oscillator).
- It can be created from raw PCM data (such as .WAV files or other formats supported by
decodeAudioData()). - It can be generated from HTML media elements, such as
<video>or<audio>. - It can be obtained from a WebRTC
MediaStream, such as a webcam or microphone.
Audio data: what's in a sample
When an audio signal is processed, sampling happens. Sampling is the conversion of a continuous signal to a discrete signal. Put another way, a continuous sound wave, such as a band playing live, is converted into a sequence of digital samples (a discrete-time signal) that allows a computer to handle the audio in distinct blocks.
You'll find more information on the Wikipedia page Sampling (signal processing).
Audio buffers: frames, samples, and channels
An AudioBuffer is defined with three parameters:
- the number of channels (1 for mono, 2 for stereo, etc.),
- its length, meaning the number of sample frames inside the buffer,
- and the sample rate, the number of sample frames played per second.
A sample is a single 32-bit floating point value representing the value of the audio stream at each specific moment in time within a particular channel (left or right, if in the case of stereo). A frame, or sample frame, is the set of all values for all channels that will play at a specific moment in time: all the samples of all the channels that play at the same time (two for a stereo sound, six for 5.1, etc.).
The sample rate is the quantity of those samples (or frames, since all samples of a frame play at the same time) that will play in one second, measured in Hz. The higher the sample rate, the better the sound quality.
Let's look at a mono and a stereo audio buffer, each one second long at a rate of 44100Hz:
- The mono buffer will have 44,100 samples and 44,100 frames. The
lengthproperty will be 44,100. - The stereo buffer will have 88,200 samples but still 44,100 frames. The
lengthproperty will still be 44100 since it equals the number of frames.

When a buffer plays, you will first hear the leftmost sample frame, then the one right next to it, then the next, and so on, until the end of the buffer. In the case of stereo, you will hear both channels simultaneously. Sample frames are handy because they are independent of the number of channels and represent time in an ideal way for precise audio manipulation.
Note: To get a time in seconds from a frame count, divide the number of frames by the sample rate. To get the number of frames from the number of samples, you only need to divide the latter value by the channel count.
Here are a couple of simple examples:
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 2,
length: 22050,
sampleRate: 44100,
});
Note: In digital audio, 44,100 Hz (alternately represented as 44.1 kHz) is a common sampling frequency. Why 44.1 kHz?
Firstly, because the hearing range of human ears is roughly 20 Hz to 20,000 Hz. Via the Nyquist–Shannon sampling theorem, the sampling frequency must be greater than twice the maximum frequency one wishes to reproduce. Therefore, the sampling rate has to be greater than 40,000 Hz.
Secondly, signals must be low-pass filtered before sampling, otherwise aliasing occurs. While an ideal low-pass filter would perfectly pass frequencies below 20 kHz (without attenuating them) and perfectly cut off frequencies above 20 kHz, in practice, a transition band is necessary, where frequencies are partly attenuated. The wider this transition band is, the easier and more economical it is to make an anti-aliasing filter. The 44.1 kHz sampling frequency allows for a 2.05 kHz transition band.
If you use this call above, you will get a stereo buffer with two channels that, when played back on an AudioContext running at 44100 Hz (very common, most normal sound cards run at this rate), will last for 0.5 seconds: 22,050 frames/44,100 Hz = 0.5 seconds.
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 1,
length: 22050,
sampleRate: 22050,
});
If you use this call, you will get a mono buffer (single-channel buffer) that, when played back on an AudioContext running at 44,100 Hz, will be automatically resampled to 44,100 Hz (and therefore yield 44,100 frames), and last for 1.0 second: 44,100 frames/44,100 Hz = 1 second.
Note: Audio resampling is very similar to image resizing. Say you've got a 16 x 16 image but want it to fill a 32 x 32 area. You resize (or resample) it. The result has less quality (it can be blurry or edgy, depending on the resizing algorithm), but it works, with the resized image taking up less space. Resampled audio is the same: you save space, but, in practice, you cannot correctly reproduce high-frequency content or treble sound.
Planar versus interleaved buffers
The Web Audio API uses a planar buffer format. The left and right channels are stored like this:
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (for a buffer of 16 frames)
This structure is widespread in audio processing, making it easy to process each channel independently.
The alternative is to use an interleaved buffer format:
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (for a buffer of 16 frames)
This format is prevalent for storing and playing back audio without much processing, for example: .WAV files or a decoded MP3 stream.
Because the Web Audio API is designed for processing, it exposes only planar buffers. It uses the planar format but converts the audio to the interleaved format when it sends it to the sound card for playback. Conversely, when the API decodes an MP3, it starts with the interleaved format and converts it to the planar format for processing.
Audio channels
Each audio buffer may contain different numbers of channels. Most modern audio devices use the basic mono (only one channel) and stereo (left and right channels) settings. Some more complex sets support surround sound settings (like quad and 5.1), which can lead to a richer sound experience thanks to their high channel count. We usually represent the channels with the standard abbreviations detailed in the table below:
| Name | Channels |
|---|---|
| Mono | 0: M: mono |
| Stereo | 0: L: left 1: R: right |
| Quad | 0: L: left 1: R: right 2: SL: surround left 3: SR: surround right |
| 5.1 | 0: L: left 1: R: right 2: C: center 3: LFE: subwoofer 4: SL: surround left 5: SR: surround right |
Up-mixing and down-mixing
When the numbers of channels of the input and the output don't match, up-mixing, or down-mixing, must be done. The following rules, controlled by setting the AudioNode.channelInterpretation property to speakers or discrete, apply:
| Interpretation | Input channels | Output channels | Mixing rules |
|---|---|---|---|
speakers |
1 (Mono) |
2 (Stereo) |
Up-mix from mono to stereo. The M input
channel is used for both output channels (L and
R).output.L = input.M
|
1 (Mono) |
4 (Quad) |
Up-mix from mono to quad. The M input channel
is used for non-surround output channels (L and
R). Surround output channels (SL and
SR) are silent.output.L = input.M
|
|
1 (Mono) |
6 (5.1) |
Up-mix from mono to 5.1. The M input channel
is used for the center output channel (C). All the others
(L, R, LFE, SL, and
SR) are silent.output.L = 0output.C = input.M
|
|
2 (Stereo) |
1 (Mono) |
Down-mix from stereo to mono. Both input channels ( L
and R) are equally combined to produce the unique output
channel (M).output.M = 0.5 * (input.L + input.R)
|
|
2 (Stereo) |
4 (Quad) |
Up-mix from stereo to quad. The L and
R input channels are used for their non-surround respective
output channels (L and R). Surround output
channels (SL and SR) are silent.output.L = input.L
|
|
2 (Stereo) |
6 (5.1) |
Up-mix from stereo to 5.1. The L and
R input channels are used for their non-surround respective
output channels (L and R). Surround output
channels (SL and SR), as well as the center
(C) and subwoofer (LFE) channels, are left
silent.output.L = input.L
|
|
4 (Quad) |
1 (Mono) |
Down-mix from quad to mono. All four input channels ( L, R, SL, and SR)
are equally combined to produce the unique output channel
(M).output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (Quad) |
2 (Stereo) |
Down-mix from quad to stereo. Both left input channels ( L and SL) are equally combined to produce the
unique left output channel (L). And similarly, both right
input channels (R and SR) are equally combined
to produce the unique right output channel (R).output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (Quad) |
6 (5.1) |
Up-mix from quad to 5.1. The L,
R, SL, and SR input channels are
used for their respective output channels (L and
R). Center (C) and subwoofer
(LFE) channels are left silent.output.L = input.Loutput.R = input.Routput.C = 0output.LFE = 0output.SL = input.SLoutput.SR = input.SR
|
|
6 (5.1) |
1 (Mono) |
Down-mix from 5.1 to mono. The left ( L and
SL), right (R and SR) and central
channels are all mixed together. The surround channels are slightly
attenuated, and the regular lateral channels are power-compensated to
make them count as a single channel by multiplying by √2/2.
The subwoofer (LFE) channel is lost.output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
|
|
6 (5.1) |
2 (Stereo) |
Down-mix from 5.1 to stereo. The central channel ( C) is summed with each lateral surround channel (SL
or SR) and mixed to each lateral channel. As it is mixed
down to two channels, it is mixed at a lower power: in each case, it is
multiplied by √2/2. The subwoofer (LFE)
channel is lost.output.L = input.L + 0.7071 * (input.C + input.SL)output.R = input.R + 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (Quad) |
Down-mix from 5.1 to quad. The central ( C) is
mixed with the lateral non-surround channels (L and
R). As it is mixed down to two channels, it is mixed at a
lower power: in each case, it is multiplied by √2/2. The
surround channels are passed unchanged. The subwoofer (LFE)
channel is lost.output.L = input.L + 0.7071 * input.Coutput.R = input.R + 0.7071 * input.Coutput.SL = input.SLoutput.SR = input.SR
|
|
| Other, non-standard layouts |
Non-standard channel layouts behave as if
channelInterpretation is set to
discrete.The specification explicitly allows the future definition of new speaker layouts. Therefore, this fallback is not future-proof as the behavior of the browsers for a specific number of channels may change in the future. |
||
discrete |
any (x) |
any (y) where x<y |
Up-mix discrete channels. Fill each output channel with its input counterpart — that is, the input channel with the same index. Channels with no corresponding input channels are left silent. |
any (x) |
any (y) where x>y |
Down-mix discrete channels. Fill each output channel with its input counterpart — that is, the input channel with the same index. Input channels with no corresponding output channels are dropped. |
|
Visualizations
In general, we get the output over time to produce audio visualizations, usually reading its gain or frequency data. Then, using a graphical tool, we turn the obtained data into a visual representation, such as a graph. The Web Audio API has an AnalyserNode available that doesn't alter the audio signal passing through it. Additionally, it outputs the audio data, allowing us to process it via a technology such as <canvas>.

You can grab data using the following methods:
AnalyserNode.getFloatFrequencyData()-
Copies the current frequency data into a
Float32Arrayarray passed into it. AnalyserNode.getByteFrequencyData()-
Copies the current frequency data into a
Uint8Array(unsigned byte array) passed into it. AnalyserNode.getFloatTimeDomainData()-
Copies the current waveform, or time-domain, data into a
Float32Arrayarray passed into it. AnalyserNode.getByteTimeDomainData()-
Copies the current waveform, or time-domain, data into a
Uint8Array(unsigned byte array) passed into it.
Note: For more information, see our Visualizations with Web Audio API article.
Spatializations
Audio spatialization allows us to model the position and behavior of an audio signal at a certain point in physical space, simulating the listener hearing that audio. In the Web Audio API, spatialization is handled by the PannerNode and the AudioListener.
The panner uses right-hand Cartesian coordinates to describe the audio source's position as a vector and its orientation as a 3D directional cone. The cone can be pretty large, for example, for omnidirectional sources.

Similarly, the Web Audio API describes the listener using right-hand Cartesian coordinates: their position as one vector and their orientation as two direction vectors, up and front. These vectors define the direction of the top of the listener's head and the direction the listener's nose is pointing. The vectors are perpendicular to one another.
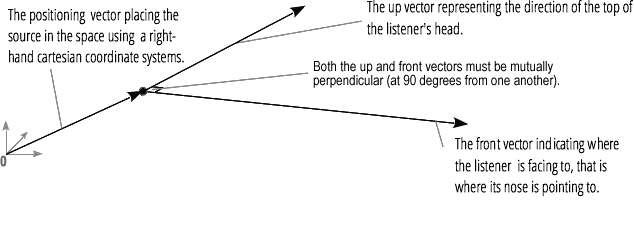
Note: For more information, see our Web audio spatialization basics article.
Fan-in and Fan-out
In audio terms, fan-in describes the process by which a ChannelMergerNode takes a series of mono input sources and outputs a single multi-channel signal:

Fan-out describes the opposite process, whereby a ChannelSplitterNode takes a multi-channel input source and outputs multiple mono output signals:
