Debugging HTML
HTML zu schreiben ist in Ordnung, aber was passiert, wenn etwas schiefgeht und Sie den Fehler im Code nicht finden können? Dieser Artikel wird Ihnen einige Werkzeuge vorstellen, die Ihnen helfen können, Fehler in HTML zu finden und zu beheben.
| Voraussetzungen: | Grundlegende HTML-Kenntnisse, wie sie in Basic HTML Syntax behandelt werden. Textbasierte Semantik wie Überschriften und Absätze und Listen. Strukturelles HTML. |
|---|---|
| Lernziele: |
|
Debugging ist nicht beängstigend
Beim Schreiben von Code läuft alles gut, bis zu dem gefürchteten Moment, in dem ein Fehler auftritt — Sie haben etwas falsch gemacht, sodass Ihr Code nicht funktioniert — entweder überhaupt nicht, oder nicht ganz so, wie Sie es wollten. Im Beispiel wird ein Fehler angezeigt, der beim Versuch auftritt, ein einfaches Programm zu kompilieren, das in der Rust-Sprache geschrieben ist.

Hier ist die Fehlermeldung relativ leicht zu verstehen — "nicht abgeschlossenes Doppel-Anführungszeichen-String". Wenn Sie sich die Auflistung ansehen, können Sie wahrscheinlich nachvollziehen, warum println!(Hello, world!"); möglicherweise ein Anführungszeichen fehlt. Allerdings können Fehlermeldungen schnell komplizierter und weniger leicht zu interpretieren werden, wenn Programme größer werden, und selbst einfache Fälle können für jemanden einschüchternd wirken, der nichts über Rust weiß.
Debugging muss jedoch nicht beängstigend sein — der Schlüssel, um sich beim Schreiben und Debuggen von Code wohl zu fühlen, ist die Vertrautheit mit der Sprache und den zugehörigen Werkzeugen.
HTML und Debugging
HTML ist nicht so kompliziert zu verstehen wie Rust. HTML wird nicht vor dem Parsen in eine andere Form kompiliert (es wird interpretiert, nicht kompiliert). Und die Element-Syntax von HTML ist wohl wesentlich einfacher zu verstehen als eine "echte Programmiersprache" wie Rust, JavaScript oder Python.
Die Art und Weise, wie Browser HTML parsen, ist viel freizügiger als die Art und Weise, wie die meisten Programmiersprachen geparst werden, was sowohl gut als auch schlecht ist.
Aber was meinen wir eigentlich mit freizügig? Nun, im Allgemeinen gibt es zwei Hauptarten von Fehlern, auf die Sie stoßen können, wenn Sie etwas im Code falsch machen:
- Syntaxfehler: Dies sind Tippfehler in Ihrem Code, die dazu führen, dass das Programm nicht ausgeführt wird, ähnlich wie der Rust-Fehler, der oben gezeigt wurde. Diese sind normalerweise einfach zu beheben, solange Sie die Syntax der Sprache kennen und wissen, was die Fehlermeldungen bedeuten.
- Logikfehler: Dies sind Fehler, bei denen die Syntax tatsächlich korrekt ist, der Code aber nicht das tut, was Sie wollten, was bedeutet, dass das Programm falsch ausgeführt wird. Diese sind oft schwerer zu beheben als Syntaxfehler, da es keine Fehlermeldung gibt, die Sie zur Fehlerquelle führt.
HTML selbst leidet nicht unter Syntaxfehlern, da Browser es freizügig parsen, was bedeutet, dass die Seite sogar angezeigt wird, wenn es Syntaxfehler im Quellcode gibt. Browser haben eingebaute Regeln, um zu bestimmen, wie falsch geschriebenes HTML-Markup (oft als ungültiges oder schlecht geformtes Markup bezeichnet) interpretiert wird, indem es automatisch in irgendein gültiges Markup geändert wird.
Zum Beispiel enthält das folgende HTML-Snippet falsch geschachtelte Elemente:
<p>I didn't expect to find the <em>next-door neighbor's <strong>cat</em></strong> here!</p>
Der schließende </strong>-Tag sollte vor dem schließenden </em>-Tag stehen, tut es aber nicht — er steht danach.
Wenn Sie dieses HTML in einen Browser laden und den gerenderten DOM ansehen, werden Sie sehen, dass die Schachtelung vom Browser korrigiert wurde:
<p>
I didn't expect to find the
<em>next-door neighbor's <strong>cat</strong></em> here!
</p>
Warum ist das sowohl gut als auch schlecht? Nun, in diesem Fall hat der Browser das beabsichtigte Ergebnis erstellt, aber wie Sie später sehen werden, ist dies nicht immer der Fall. Sie werden immer etwas zum Laufen bekommen, aber der Browser liegt nicht immer richtig, was zu Problemen führen kann. Es ist besser, korrekte Markup von Anfang an zu schreiben.
Hinweis: HTML wird freizügig geparst, weil beim ersten Erstellen des Webs entschieden wurde, dass es wichtiger ist, Inhalte zu veröffentlichen, als darauf zu bestehen, dass die Syntax absolut korrekt ist. Das Web wäre wahrscheinlich nicht so populär wie heute, wenn es von Anfang an strenger gewesen wäre.
Wie finden Sie also Markup-Fehler? Später werden wir Ihnen zeigen, wie Sie Fehler in HTML mit einem Tool namens HTML Validator finden, aber zuerst zeigen wir Ihnen, wie Sie Ihr HTML manuell mit einem DOM-Inspektor überprüfen und welche Arten von Markup-Fehlern Sie dabei suchen könnten und wie der Browser diese interpretieren könnte.
Verwendung des DOM-Inspektors
Alle modernen Browser haben eine Reihe von Entwicklerwerkzeugen (DevTools) in ihnen integriert, die eine Reihe von Funktionen bieten, um die in die aktuelle Registerkarte geladene Webseite zu untersuchen. Diese können Ihnen zeigen, welches HTML auf der Seite gerendert wird, welches CSS auf jeden DOM-Knoten angewendet wird, welches JavaScript auf der Seite läuft und mehr. Sie ermöglichen es Ihnen auch, den aktuell laufenden Code zu bearbeiten und die Auswirkungen live auf der Seite zu sehen.
Sie können die DevTools in jedem Browser auf ähnliche Weise öffnen — sehen Sie sich Wie man die DevTools in Ihrem Browser öffnet an, um zu erfahren, wie.
Für diesen Artikel ist die einzig relevante DevTools-Funktion der DOM-Inspektor, der den aktuell gerenderten HTML-DOM zeigt und es Ihnen ermöglicht, ihn zu bearbeiten. Schauen wir uns das nun an:
- Öffnen Sie die DevTools in Ihrem Browser.
- Öffnen Sie den DOM-Inspektor. Er befindet sich an derselben Stelle in jedem Browser — dem ersten Tab in den DevTools am Anfang der Zeile. In Firefox ist er mit Inspector beschriftet, während er in Safari, Edge und Chrome mit Elements beschriftet ist. Dies sollte der Tab sein, der standardmäßig ausgewählt ist, wenn Sie die DevTools zum ersten Mal öffnen, aber wählen Sie ihn aus, wenn dies nicht der Fall ist.
- Untersuchen Sie die im Tab angezeigte DOM-Struktur und beachten Sie, wie Sie auf die kleinen Expansionspfeile am Anfang jedes DOM-Knotens klicken können, um sie zu erweitern und zusammenzuklappen und ihre Knoten nach unten zu offenbaren. Sie können auch die Aufwärts- und Abwärtspfeiltasten verwenden, um sich auf den Knoten zu bewegen, und die Rechts- und Linkspfeiltasten, um die Knoten zu erweitern und zu kollabieren.
- Versuchen Sie auch, über die Knoten zu schweben (oder diese mit den Pfeiltasten auszuwählen) und achten Sie darauf, wie das aktuell in der Ansicht schwebende (oder ausgewählte) Element hervorgehoben wird.
- Sie können den gerenderten DOM auch bearbeiten. In diesem Artikel verwenden wir die Bearbeitungsfunktionalität nicht, aber nehmen Sie sich Zeit, herauszufinden, wie Sie dies tun können, falls Sie neugierig sind.
Ihr Zug: Studium von HTML mit dem DOM-Inspektor
In diesem Abschnitt werden Sie etwas Code mit dem DOM-Inspektor untersuchen und sehen, wie der Browser mit häufigen Markup-Fehlern umgeht.
-
Speichern Sie zunächst das folgende HTML-Dateilisting als
debug-example.htmlirgendwo auf Ihrem lokalen Gerät. Diese Demo ist absichtlich mit einigen eingebauten Fehlern geschrieben, die wir erkunden werden.html<!doctype html> <html lang="en-US"> <head> <meta charset="utf-8"> <title>HTML debugging examples</title> </head> <body> <h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly,then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> </body> </html> -
Öffnen Sie sie anschließend in einem Browser. Sie werden etwas wie das Folgende sehen:

-
Das sieht sofort nicht gut aus; lassen Sie uns den Quellcode ansehen, um zu sehen, ob wir herausfinden können, warum (nur der Inhalt des Bodys wird angezeigt):
html<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> -
Lassen Sie uns die Probleme überprüfen:
- Die Absatz und Listeneintrag-Elemente haben keine schließenden Tags. Anhand des obigen Bildes scheint dies das Markup-Rendering nicht allzu sehr beeinträchtigt zu haben, da es einfach ist, zu folgern, wo ein Element enden und ein anderes beginnen sollte.
- Das erste
<strong>-Element hat keinen schließenden Tag. Dies ist etwas problematischer, da es nicht einfach ist, zu sagen, wo das Element enden soll. Tatsächlich wurde der gesamte restliche Text fett dargestellt. - Dieser Abschnitt ist schlecht geschachtelt:
<strong>stark <em>betont stark?</strong> was ist das?</em>. Aufgrund des vorherigen Problems ist es nicht leicht zu erkennen, wie dies interpretiert wurde. - Der
href-Attributwert fehlt das schließende Anführungszeichen. Dies scheint das größte Problem verursacht zu haben – der Link wurde überhaupt nicht gerendert.
-
Schauen wir uns nun den gerenderten DOM an, im Gegensatz zum Quellcode. Um dies zu tun, öffnen Sie den DOM-Inspektor Ihres Browsers. Sie werden eine Darstellung des gerenderten Markups sehen:

-
Sehen Sie sich an, wie der Browser versucht hat, unsere HTML-Fehler zu beheben (wir haben die Überprüfung in Firefox durchgeführt; andere moderne Browser sollten dasselbe Ergebnis liefern):
-
Die Absätze und Listeneinträge wurden mit schließenden Tags versehen.
-
Es ist nicht klar, wo das erste
<strong>-Element geschlossen werden sollte, daher hat der Browser jeden separaten Textblock in ein eigenes<strong>-Element eingewickelt, bis zum Ende des Dokuments! -
Die falsche Schachtelung wurde vom Browser wie folgt korrigiert:
html<strong> strong <em>strong emphasized?</em> </strong> <em> what is this?</em> -
Der Link mit dem fehlenden Anführungszeichen wurde vollständig gelöscht. Der letzte Listeneintrag sieht so aus:
html<li> <strong> Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
-
HTML-Validierung
Wie Sie am obigen Beispiel sehen können, möchten Sie wirklich sicherstellen, dass Ihr HTML gut geformt ist! Aber wie? In einem kleinen Beispiel wie dem oben gesehenen, ist es einfach, die Zeilen zu durchsuchen und die Fehler zu finden, aber was ist mit einem riesigen, komplexen HTML-Dokument?
Das Tool für diese Aufgabe ist der Markup Validation Service (oder HTML-Validator), der von der W3C erstellt und gepflegt wird (den Sie in Das Webstandards-Modell kennengelernt haben). Der Validator nimmt ein HTML-Dokument als Eingabe, überprüft es und gibt Ihnen einen Bericht, der Ihnen mitteilt, was mit Ihrem HTML nicht stimmt.

Um das HTML zu validieren, können Sie eine Webadresse angeben, eine HTML-Datei hochladen oder direkt etwas HTML-Code eingeben.
Validierung eines HTML-Dokuments
In dieser Aufgabe werden wir Sie den HTML-Validator ausprobieren lassen. Sie werden unser Beispieldokument validieren und sehen, welche Ergebnisse zurückgegeben werden. Dieses Beispiel enthält dasselbe HTML, das Sie zuvor mit dem DOM-Inspektor untersucht haben.
- Laden Sie zuerst den Markup Validation Service in einem neuen Browser-Tab, falls er noch nicht geöffnet ist.
- Wechseln Sie zum Tab Validate by Direct Input.
- Kopieren Sie den gesamten Code des Beispieldokuments (nicht nur den Body) und fügen Sie ihn in das große Textfeld des Markup Validation Service ein.
- Drücken Sie auf die Check-Schaltfläche.
Dies sollte Ihnen eine Liste von Fehlern und anderen Informationen geben.
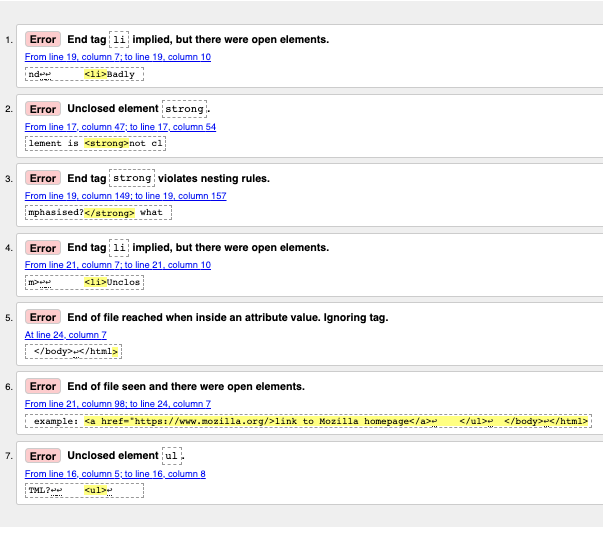
Fehlernachrichten interpretieren
Die Fehlermeldungen sind normalerweise hilfreich, manchmal aber nicht so leicht zu verstehen. Mit ein wenig Übung können Sie herausfinden, wie Sie diese interpretieren, um Ihren Code zu reparieren. Gehen wir die Fehlermeldungen durch und sehen, was sie bedeuten. Sie werden sehen, dass jede Nachricht mit einer Zeilen- und Spaltennummer versehen ist, um Ihnen zu helfen, den Fehler leicht zu finden.
-
"End-Tag
liimpliziert, aber es gibt offene Elemente" (2 Instanzen): Diese Nachrichten deuten darauf hin, dass ein Element geöffnet ist, das geschlossen werden sollte. Das End-Tag ist impliziert, aber tatsächlich nicht vorhanden. Die Zeilen-/Spalteninformationen weisen auf die erste Zeile nach der Zeile hin, wo das schließende Tag wirklich sein sollte, aber dies ist ein ausreichender Hinweis, um zu sehen, was falsch ist. -
"Nicht geschlossenes Element
strong": Dies ist einfacher zu verstehen — ein<strong>-Element ist nicht geschlossen, und die Zeilen-/Spalteninformationen zeigen genau an, wo es sich befindet. -
"End-Tag
strongverletzt Schachtelungsregeln": Dies weist auf die falsch geschachtelten Elemente hin, und die Zeilen-/Spalteninformationen zeigen, wo sie sich befinden. -
"Ende der Datei erreicht, während sich innerhalb eines Attributwertes. Tag ignorieren": Dies ist ziemlich kryptisch; es bezieht sich auf die Tatsache, dass irgendwo ein Attributwert nicht richtig formatiert ist, möglicherweise in der Nähe des Dateiende, da das Ende der Datei innerhalb des Attributwertes erscheint. Die Tatsache, dass der Browser den Link nicht rendert, sollte uns einen guten Hinweis geben, welches Element schuld ist.
-
"Ende der Datei gesehen und es gab offene Elemente": Dies ist etwas zweideutig, bezieht sich im Grunde auf die Tatsache, dass es offene Elemente gibt, die richtig geschlossen werden müssen. Die Zeilennummern weisen auf die letzten Zeilen der Datei hin, und diese Fehlermeldung enthält eine Zeile Code, die ein Beispiel für ein offenes Element anzeigt:
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Hinweis: Ein Attribut, dem ein schließendes Anführungszeichen fehlt, kann zu einem offenen Element führen, da der Rest des Dokuments als Inhalt des Attributs interpretiert wird.
-
"Nicht geschlossenes Element
ul": Dies ist nicht sehr hilfreich, da das<ul>-Element korrekt geschlossen ist. Dieser Fehler tritt auf, da das<a>-Element nicht geschlossen ist, aufgrund des fehlenden schließenden Anführungszeichens.
Wenn Sie nicht herausfinden können, was jede Fehlermeldung bedeutet, machen Sie sich keine Sorgen. Eine gute Strategie ist es, einige Fehler auf einmal zu beheben und dann Ihr HTML nach jeder Menge von Korrekturen erneut zu validieren, um zu sehen, welche Fehler noch übrig sind. Manchmal wird durch das Beheben eines früheren Fehlers auch andere Fehlermeldungen losgelöst — mehrere Fehler können oft durch ein einziges Problem verursacht werden, in einem Dominoeffekt.
Sie werden wissen, dass alle Ihre Fehler behoben sind, wenn Sie ein schönes kleines grünes Banner sehen, das Ihnen sagt, dass es keine Fehler zu melden gibt. Zum Zeitpunkt des Schreibens sagte es: "Dokumentenprüfung abgeschlossen. Keine Fehler oder Warnungen zu melden."
Zusammenfassung
Da haben Sie es also, eine Einführung in das Debuggen von HTML, die Ihnen einige nützliche Fähigkeiten bieten sollte, auf die Sie zählen können, wenn Sie HTML, aber auch CSS und JavaScript-Code später im Kurs debuggen. Dies markiert auch das Ende des Moduls Inhalte mit HTML strukturieren.
Ihr nächster Schritt ist es, in unserem Modul CSS-Grundlagen des Stylings mit dem Stylen des Webs zu beginnen.