ホワイトスペースの処理
DOM にホワイトスペースが存在すると、レイアウトの問題が発生したり、ホワイトスペースがある場所によっては、予期せぬ形でコンテンツツリーの操作が困難になったりすることがあります。この記事では、どのような場合に問題が発生するかを探り、その結果生じる問題を軽減するために何ができるかを見ていきます。
ホワイトスペースとは
ホワイトスペース文字は、プログラミング言語のコンテキストによって、構成する文字が異なります。文書のホワイトスペース文字によると、CSS のホワイトスペース処理ルールにおいては、空白 (U+0020)、タブ (U+0009)、行送り (LF、U+000A)、キャリッジリターン (CR、U+000D) のみが対象になります。ここで、CR 文字はあらゆる点で空白と同等です。これらの文字を使用することで、自分や他の人が読みやすいようにコードを整形することができます。実際、私たちのソースコードの多くはこれらのホワイトスペースであふれており、コードのダウンロードサイズを減らすために、本番のビルド段階でホワイトスペースを取り除く傾向があります。
なお、このリストには、非改行空白 (U+00A0、HTML では ) は含まれていません。したがって、これらの文字は統合を引き起こさず、HTML で長い空白を作成する場合に多く使用されます。
CSS では、セグメント区切りという概念も定義しています。これは、HTML のコンテキストでは LF 文字と同等です。
HTML のホワイトスペースの処理方法
「HTML はホワイトスペースを無視する」とよく言われますが、それは事実ではありません。HTML は、ソースコードで記述したとおりに、すべてのホワイトスペースのテキストコンテンツを保存します。 マークアップ言語である HTML は DOM を作成するとき、テキストコンテンツ内のすべてのホワイトスペースを保存します。この DOM は、Node.textContent などの DOM API を使用して取得および操作することができます。もし HTML が DOM からホワイトスペースを削除してしまうと、DOM 上で動作する下流のレンダリングエンジンである CSS は、white-space プロパティを使用してそのまま残すことができなくなります。
メモ: 正確には、ここでは HTML タグ間のホワイトスペースについて話しています。これは DOM ではテキストノードになります。タグ内のホワイトスペース(山括弧の間にあるが、属性値の一部ではないもの)は、 HTML 構文の一部であり、DOM には現れません。
メモ:
HTML の構文解析の特性(DOM 仕様書から)により、ホワイトスペース文字が無視される場所があります。例えば、<html> と <head> の開始タグの間、または </body> と </html> の終了タグの間のホワイトスペースは無視され、DOM には表示されません。また、<pre> 要素のテキストコンテンツを構文解析する場合、先頭に改行文字があると 1 つ削除されます。ここでは、これらの例外は無視しています。
さらに、 HTML パーサーは特定のホワイトスペースを正規化します。 CR および CRLF の並びを単一の LF に置き換えます。ただし、 CR 文字は、文字参照または JavaScript によって DOM に挿入されることもあるため、 CSS のホワイトスペース処理ルールでは、それらをどのように処理するかを定義しておく必要があります。
例えば、次の文書を見てください。
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
この DOM ツリーは次のように見えます。

以下の点に注意してください。
- ホワイトスペースのみが含まれるテキストノードがあります。
- 他のテキストノードは、先頭または末尾にホワイトスペースを保有することがあります。
メモ: [Firefox 開発者ツール] (https://firefox-source-docs.mozilla.org/devtools-user/index.html) は、テキストノードの強調表示に対応しており、ホワイトスペース文字が含まれているノードを確認できます。純粋なホワイトスペースノードには "whitespace" というラベルが付いています。
DOM 内でホワイトスペース文字を保存することは、さまざまな点で有用ですが、一部のレイアウトの実装が難しくなったり、DOM ノードを反復処理したい開発者に問題を引き起こしたりする可能性もあります。これらの課題と、その解決策については、後でホワイトスペースノードに関する一般的な問題の解決の節で見ていきます。
CSS のホワイトスペースの処理方法
DOM がレンダリングのために CSS に渡されると、既定ではホワイトスペースは大部分が削除されます。つまり、コードの書式化方法はユーザーには見えません。要素の周囲や内部に空間を作成するのは、CSS の仕事です。
<!doctype html>
<h1> Hello World! </h1>
このソースコードには、 doctype の後に 2 つの改行と <h1> 要素の前後と内部にホワイトスペースの束が含まれています。しかし、ブラウザーはこれらのホワイトスペースを無視して、これらの文字が全く存在しないかのように "Hello World!" という言葉を表示しています。
ほとんどのホワイトスペースは無視されますが、すべてが無視されるわけではありません。先ほどの例では、 "Hello" と "World!" の間のホワイトスペースの一つは、ブラウザーでページがレンダリングされるときにまだ存在しています。 CSS は、特定のアルゴリズムを使用して、ユーザーには無関係なホワイトスペース文字を判断し、それらを除去または変換する方法を決定します。この処理がどのように動作するのかについては、次のいくつかの節で説明します。
統合と変換
例を見てみましょう。分かりやすいように、コメントの中ですべての空白を ◦ で、すべてのタブを ⇥ で、すべての改行を ⏎ で表現します。
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
これはブラウザーで次のようにレンダリングされます。
<h1> 要素には次のものが含まれています。
- 1 つのテキストノード(いくつかの空白、 "Hello" という語、いくつかのタブから成る)
- 1 つのインライン要素(
<span>で、中に空白と "World!" という語を含む) - もう 1 つのテキストノード(
<span>の後のタブと空白のみから成る)
この <h1> 要素にはインライン要素しか含まれていないため、インライン整形コンテキストを確立します。これは、ブラウザーエンジンが作業を行う存在する可能性のあるレイアウトレンダリングコンテキストの一つです。
このコンテキストの中では、ホワイトスペース文字の処理は次のように要約されます。
メモ:
このアルゴリズムは、 white-space-collapse プロパティ (またはその一括指定プロパティ white-space) で構成される可能性があります。まず、その既定値 (white-space-collapse: collapse) を想定して、さまざまなプロパティ値がこのアルゴリズムにどのように影響するかを見ていきます。
-
まず、改行の直前と直後の空白とタブはすべて無視されるので、以前のマークアップの例を参考にすると、次のようになります。
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>...そして最初のルールを適用すると、次のようになります。
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
次に、連続する改行は単一の改行に統合されます。この例では、そのような改行は存在しません。
-
次に、ソースコード内の行は、残っている改行文字が除去されて単一の行に結合されます。改行文字は、その前後のコンテキストに応じて、空白 (U+0020) に変換されるか、単に除去されます。どちらが選択されるかは、ブラウザーや言語によって異なります。この例では、英語(単語は空白で区切られる)を使用しているため、すべての改行は空白に「変換」されることが予想されます。その結果、次のような結果になります。
html<h1>◦◦◦Hello◦<span>◦World!</span>⇥◦◦</h1>なお、中国語のように単語の区切り文字が存在しない言語では、行は空白を含まずに結合されます。したがって、
html<div>你好 世界</div>これは、ブラウザーの経験則によっては、間の空白がすべて削除されて「你好世界」と表示される場合があります。
-
次に、すべてのタブ文字が空白文字に変換されるため、この例は次のようになります。
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> -
その後で、空白の直後に他の空白がある場合は(2 つが別々なインライン要素をまたぐ場合も含めて)無視されるので、次のようになります。
html<h1>◦Hello◦<span>World!</span>◦</h1>
このため、ウェブページを訪れた人は、ひどく字下げされた "Hello" に続いてもっとひどく字下げされた "World!" をその下の行に見かけるのではなく、ページの先頭にきれいに書かれた "Hello World!" という文言を見ることになります。
これらの手順の後、ブラウザーは行の折り返しと双方向テキストを処理しますが、ここでは無視します。開始タグ <h1> の後と終了タグ </h1> の前にまだ空白が残っていることに注意してください。これらはブラウザーでは表示されません。それぞれの行のレイアウトを行う次の段階で、これを処理します。
white-space-collapse の値が異なる場合、このアルゴリズムのさまざまな段階が省略されます。
preserveおよびbreak-spaces: アルゴリズム全体がスキップされ、ホワイトスペースの統合や変換は行われません。preserve-breaks: 段階 2 および 3 が省略され、改行が保持されます。preserve-spaces: アルゴリズム全体が省略され、それぞれのタブまたは改行を空白に変換する単一段階で置き換えられます。
簡単に言えば、さまざまなホワイトスペース文字は、次の方法で統合および変換されます。
- タブは通常、空白に変換されます。
- セグメント区切りを統合する場合:
- セグメント区切りは、単一のセグメント区切りに統合されます。
- これらは、単語を空白で区切る言語(英語など)では空白に変換され、単語を空白で区切らない言語(中国語など)では完全に除去されます。
- 空白を統合する場合:
- セグメント区切り前の空白やタブは除去されます。
- 連続する空白は単一の空白に統合されます。
- 空白が保持される場合、一連の空白は改行されない扱いになりますが、それぞれの並びの終わりではソフト改行されます。つまり、次の行は常に次の空白文字以外の文字で始まります。ただし、
break-spacesの値の場合、各空白の後にソフト改行が発生する可能性があるため、次の行は 1 つ以上の空白で始まる場合があります。
トリミングと位置指定
インラインおよびブロックの両方の整形コンテキストでは、要素は 行 でレイアウトされます。インライン整形コンテキストでは、行はテキストの折り返しによって作成されます。一方、ブロック整形コンテキストでは、それぞれのブロックが自分自身で行を形成します。それぞれの行がレイアウトされるにつれて、空白がさらに処理されます。これがどのように動作するのか、例を見てみましょう。
この例では、前と同じようにホワイトスペース文字をマークしようと思います。ここにはホワイトスペースのみを含む 3 つのテキストノードがあります。 <div> の前に 1 つ、 2 つの <div> の間に 1 つ、 2 つ目の <div> の後に 1 つです。
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
これは次のように表示されます。
この例では、ホワイトスペースは次のように処理されます。
メモ:
このアルゴリズムは、white-space-collapse プロパティ(またはその一括指定プロパティ white-space)で構成できます。まず、その既定値(white-space-collapse: collapse)を仮定して、さまざまなプロパティ値がこのアルゴリズムにどのように影響するかをみていきます。
-
まず、ホワイトスペースは、前回と同じ方法で統合されます。これにより、
html<body>⏎ ⇥<div>⇥Hello⇥</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>...これは次のようになります。
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>行は、
<body>によって確立されたブロック整形コンテキストに従ってレイアウトされます。この例では、<body>の 5 つの子ノードはそれぞれ別個の行としてレイアウトされます。(このコードブロックの各行は、レンダリングされたレイアウトの行を表しており、元の HTML コードの行を表しているわけではありません)。html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>行が長くなりすぎると、それぞれの行が折り返して複数の行が作成される場合があることに注意してください。実際には、ブラウザーは、行がレイアウトされる際にその行のコンテンツを決定します。テキストの折り返しの動作についてはここでは省略します。
-
そして、これらのブロックにインライン整形コンテキストにおけるホワイトスペースの処理ルールを適用することで、さらに簡素化されます。
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
この時点で保持されているそれぞれのタブは、
tab-sizeに応じてレンダリングされます。これは、white-space-collapseがpreserveまたはbreak-spacesに設定されている場合にのみ現れます。それ以外の設定では、タブはすべて空白に変換されるためです。 -
行の末尾の空白は除去されるため、上記のものは次のように変更されます。
html<body> <div>Hello</div> <div>World!</div> </body>
できた 3 つの空のブロックは、最終的なレイアウトでは何も含まれないので、ページ内の空間を占有するブロックは 2 つだけになります。このウェブページを見る人には、 "Hello" と "World!" という言葉が、 2 つの別々の行にあるように見えます。これは 2 つの <div> が並べられた場合の期待通りです。ブラウザーエンジンは、ソースコードに追加されたすべての空白を基本的に無視しています。
Different white-space-collapse の各値によって、このアルゴリズムのさまざまな段階が省略されます。
preserveおよびbreak-spaces: 段階 3 を除くアルゴリズム全体が省略されるため、ホワイトスペースの統合や変換は行われません。preserve-spaces: アルゴリズム全体がスキップされるため、行の先頭と末尾のホワイトスペース文字が保持されます。preserve-breaks:collapse値に対応するアルゴリズムが適用されます。
DOM API のホワイトスペースの処理方法
前回述べたように、ホワイトスペースは DOM 内で保持されます。つまり、 Node.textContent を取得すると、 HTML ソースコードで記述したとおりにテキストコンテンツが取得され、 Node.childNodes を取得すると、ホワイトスペースのみを含むものも含め、すべてのテキストノードが取得されます。
すべての DOM API がホワイトスペースを保持するわけではありません。一部の API は、設計上、レンダリングされたテキストを扱います。例えば、 HTMLElement.innerText は、すべてのホワイトスペースが統合されてトリミングされ、レンダリングされるとおりのテキストを返します。 Selection.toString() は、貼り付けられるとおりのテキストを返します。これは、通常、ホワイトスペースが統合されるということです。ただし、 Firefox では(上記の ホワイトスペースの統合と変換で述べたように、漢字間のホワイトスペースは統合されます)、折りたたまれたホワイトスペースは、toString() によって返される文字列と貼り付けられたテキストの両方で保持されます。
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
ホワイトスペースノードに関する一般的な問題の解決
ホワイトスペースノードは、CSS の処理ルールにより、ウェブサイトの来訪者には見えません。しかし、DOM の正確な構造に依存する特定のレイアウトや DOM 操作に干渉する可能性があります。よくある問題と、その解決方法を見ていきましょう。
インライン要素やインラインブロック要素間のホワイトスペース
ホワイトスペースノードに関するレイアウトの課題の 1 つ、インライン要素とインラインブロック要素間の空白を見てみましょう。インライン要素とブロック要素で前述したように、ほとんどのホワイトスペース文字は無視されますが、空白と同様に単語を区切る文字は残ります。レイアウトに残る余分なホワイトスペースは、文中の単語を区切るのに役立ちます。
inline-block 要素を使用すると、さらに興味深い結果になります。これらの要素は、外側はインライン要素のように、内側はブロックのように動作します。(これらは、ナビゲーションメニューのアイテムなど、同じ行に横に並んでいる複雑な UI 要素を表示するために多く使用されます。隣接するインライン要素またはインラインブロック要素間のホワイトスペースは、テキスト内の単語間のスペースと同様に、レイアウトに空白として表示されます。(これらはブロックであるため、通常、余分なスペースは表示されないため、開発者は驚くかもしれません。)
この例を見てみてください(こちらも HTML のコメントの中で HTML のホワイトスペース文字を示しています)。
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
これは次のように表示されます。
おそらく、ブロック間の隙間は望ましくないでしょう。用途(アバターの一覧や横一列のナビゲーションボタンなど)によっては、要素を互いに揃えて、間隔を自分で制御できる方が望ましいでしょう。
Firefox 開発者ツールの HTML インスペクターでは、テキストノードを強調表示し、要素が占めている領域を正確に表示することができます。これは、余分なマージンや予期しない空白によって隙間が発生している疑いがある場合に、それを確認するのに役立ちます。
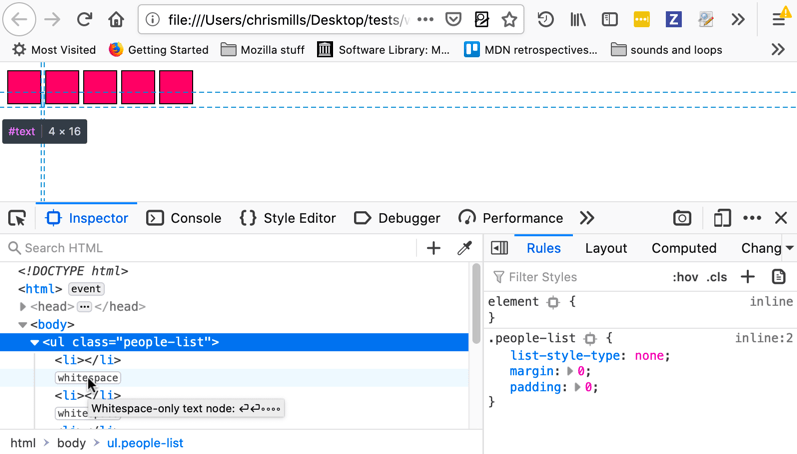
この問題を回避する方法は何通りかあります。
-
水平方向のアイテムのリストを生成するのに、
inline-blockによる解決法よりもフレックスボックスを使用します。これは、あなたに代わってすべてを処理するもので、間違いなく望ましい解決策です。cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
inline-blockに頼る必要があるのであれば、そのリストのfont-sizeを0にしてください。これは、ブロックのサイズがemで設定されていない場合のみ有効です(ブロックのサイズもfont-sizeに基づいているので、結局0になってしまいます)。ここではremを使用するといいでしょう。cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
または、リストアイテムに負のマージンを設定する方法もあります。
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
この問題は、リストアイテムをすべてソースの同じ行に配置し、空白のノードが最初に作成されないようにすることで解決することもできます。
html<li> ... </li><li> ... </li>
DOM でのホワイトスペースの処理
前述のように、ホワイトスペースはレンダリング時に統合されてトリミングされますが、DOM では保持されます。 DOM を JavaScript で操作しようとするとき、ホワイトスペースのノードに起因する問題に遭遇する可能性があります。例えば、親ノードへの参照を持っていて Node.firstChild を使用して先頭の子要素を走査しようとした場合、親要素の開始タグの直後に不正なホワイトスペースがあると、予期しない結果になります。このテキストノードが走査したい要素の代わりに選択されてしまうからです。
別の例として、ある要素のサブセットがあり、それらが空であるかどうか(子ノードがないかどうか)を判断して何かをしたい場合、 Node.hasChildNodes() などを使用してそれぞれの要素が空であるかを確認することができますが、やはり対象の要素がテキストノードを含んでいれば、誤った結果になってしまう可能性があります。
以下の JavaScript のコードでは、 DOM 内の空白を簡単に処理するためのいくつかの関数を定義しています。
/**
* スクリプト全体で、ホワイトスペースを以下のいずれかの文字として定義しています。
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* JavaScript の \s は非改行空白 (および他のいくつかの文字) を含んでいる為
* このスクリプトでは使用しません。
*/
/**
* ノードのテキスト内容が完全に空白であるか判断
*
* @param nod `CharacterData` インターフェイスを実装したノード
* (すなわち `Text`, `Comment`, `CDATASection` ノード)
* @return `nod` のテキスト内容がすべてホワイトスペースであれば `true`
* それ以外は `false`
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* 反復処理関数がノードを無視するべきかどうか判断
*
* @param nod DOM1 の `Node` インターフェイスを実装したノード
* @return ノードが次のいずれかであれば `true`
* 1) すべてホワイトスペースである `Text` ノード
* 2) `Comment` ノード
* それ以外は `false`
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // コメントノード
(nod.nodeType === 3 && isAllWs(nod))
); // 全てホワイトスペースのテキストノード
}
/**
* 完全に空白あるいはコメントのノードを無視するようにした `previousSibling`
* (通常 `previousSibling` はすべての DOM ノードが持つプロパティのことで、親が
* 同じで参照ノードの直前にある兄弟ノードを表します)
*
* @param sib 参照ノード
* @return `sib` に最も近い前の兄弟ノードで、
* `isIgnorable` 検査で無視できないと判断されたもの、
* または該当するノードがなければ `null`
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* 完全に空白あるいはコメントのノードを無視するようにした `nextSibling`
*
* @param sib 参照ノード
* @return `sib` に最も近い次の兄弟ノードで、
* `isIgnorable` 検査で無視できないと判断されたもの、
* または該当するノードがなければ `null`
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* 完全に空白あるいはコメントのノードを無視するようにした lastChild
* (通常 lastChild はすべての DOM ノードが持つプロパティのことで、参照ノードに
* 直接含まれる最後のノードを表します)
*
* @param sib 参照ノード
* @return `sib` の最後の子ノードで、
* `isIgnorable` 検査で無視できないと判断されたもの、
* または該当するノードがなければ `null`
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* 完全に空白あるいはコメントのノードを無視するようにした `firstChild`
*
* @param sib 参照ノード
* @return `sib` の最初の子ノードで、
* `isIgnorable` 検査で無視できないと判断されたもの、
* または該当するノードがなければ `null`
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* 先頭と末尾に空白を含まず、すべての空白を単一の空白に正規化した
* `data` のバージョン。(通常、`data` は、ノードのテキストを付与する
* テキストノードのプロパティです。)
*
* @param txt data が返されるべきテキストノード
* @return 当該テキストノードの内容が与えるホワイトスペースを纏めた文字列
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
次のコードは、上記の関数の使い方を示したものです。これは、ある要素の子(その子はすべて要素)を繰り返し、テキストが "これは 3 番目の段落です。" であるものを見つけ、 class 属性とその段落の内容を変更するものです。
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "これは 3 番目の段落です。") {
cur.className = "magic";
cur.firstChild.textContent = "これは magic の段落です。";
}
cur = nodeAfter(cur);
}