什么是空白字符?
空白字符在不同编程语言环境中具有不同含义。对文档空白字符而言,仅包含空格(U+0020)、制表符(U+0009)、换行符(LF,U+000A)和回车符(CR,U+000D),其中回车符在所有方面都等同于空格。这些字符可用于格式化代码以提升可读性。我们的源代码中充斥着大量此类空白字符,通常仅在生产构建阶段为缩减文件大小而将其移除。
请注意,此列表不包含不可分割空格(U+00A0,HTML 中的 )。因此这些字符不会触发任何折叠,这也是它们常被用于在 HTML 中创建更长空格的原因。
CSS 还定义了分段符的概念,在 HTML 语境中其功能等同于换行符。
HTML 如何处理空白字符?
“HTML 会忽略空白字符”是一个普遍存在的误解,事实并非如此:HTML 会完整保留源代码中所有空白文本内容。作为标记语言,HTML 会生成一个 DOM,其中文本内容的所有空白字符均被完整保留,可通过 DOM API(如 Node.textContent)进行检索和操作。若 HTML 从 DOM 中移除空白字符,那么作为基于 DOM 工作的下游渲染引擎,CSS 将无法通过 white-space 属性保留这些空白。
备注:需要明确的是,我们讨论的是 HTML 标签之间的空白字符,这些空白字符在 DOM 中会转化为文本节点。而任何位于标签内部的空白字符(即位于尖括号之间但不属于属性值的空白)仅是 HTML 语法的一部分,不会出现在 DOM 中。
备注:由于 HTML 解析的特殊性(引自 DOM 规范),确实存在某些位置会忽略空白字符。例如,<html> 与 <head> 起始标签之间,或 </body> 与 </html> 结束标签之间的空白字符会被忽略且不会出现在 DOM 中。此外,解析 <pre> 元素的文本内容时,开头的单个换行符会被移除。我们忽略这些边界情况。
此外,HTML 解析器会规范化某些空白字符:它将 CR 和 CRLF 序列替换为单个 LF。然而,CR 字符也可通过字符引用或 JavaScript 插入 DOM,因此 CSS 空白字符处理规则仍需定义其处理方式。
以下列文档为例:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
其 DOM 树类似于这样:

注意到:
- 会有一些文本节点只包含空白字符,而且
- 有些文本节点会在开头或结尾有空白字符。
备注:Firefox 开发者工具支持高亮显示文本节点,便于准确识别包含空白字符的节点。纯空白节点会标注为“空白”标签。
在 DOM 中保留空白字符在很多方面都是有用的,但在某些地方,这使得某些布局更难实现,并给那些想在 DOM 中迭代节点的开发者带来了问题。我们将在后续章节的解决空白字符节点常见问题部分探讨这些问题及相关解决方案。
CSS 如何处理空白字符?
当 DOM 被传递给 CSS 进行渲染时,默认情况下空白字符会被大量移除。这意味着代码的格式化方式对最终用户不可见——在元素周围和内部创建空间是 CSS 的职责。
<!doctype html>
<h1> Hello World! </h1>
该源代码在 doctype 标签后包含若干换行符,并在 <h1> 标签前后及内部存在大量空格字符。但浏览器会忽略这些空白字符,仅显示“Hello World!”字样,仿佛这些字符根本不存在:
CSS 会忽略大部分(但并非全部)空白字符。在此示例中,当页面在浏览器中渲染时,“Hello”与“World!”之间的一个空格仍然存在。CSS 采用特定算法来判定哪些空白字符对用户无关紧要,并决定如何移除或转换这些字符。我们将在接下来的章节中详细说明该处理机制的工作原理。
折叠与转换
让我们看一个例子。为了使空白字符更突出,我们还添加了注释,将所有空格显示为◦,所有制表符显示为⇥,所有换行符显示为⏎:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
会在浏览器中像这样渲染:
<h1> 元素包含:
- 一个文本节点(包含一些空格、单词“Hello”、一个换行符和一些制表符)。
- 一个行内元素(
<span>,包含一个空格和单词“World!”)。 - 另外一个文本节点(只包含制表符和空格)。
由于 <h1> 只包含行级元素,它建立了行内格式化上下文。这是浏览器引擎可能使用的布局渲染上下文之一。
在这个上下文中,空白字符的处理可以总结如下:
备注:该算法可通过 white-space-collapse 属性(或其简写属性 white-space)进行配置。我们将首先假设其默认值(white-space-collapse: collapse),然后探讨不同属性值如何影响该算法。
-
首先,换行符前后紧邻的所有空格和制表符都会被忽略。因此,如果我们参考之前的示例标记:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>应用这条规则,会得到:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
然后,连续的换行符被折叠为单个换行符。此示例中不存在。
-
接下来,源代码中的行通过移除所有剩余换行符合并为单行。具体处理方式取决于换行符前后的上下文:换行符要么转换为空格(U+0020),要么直接删除。具体采用哪种方式取决于浏览器和语言环境。在本例的英文文本中(单词间以空格分隔),所有换行符都将被“转换”为空格。最终结果如下:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1>值得注意的是,在没有词间分隔符的语言(如中文)中,行与行之间不留空格。因此:
html<div>你好 世界</div>根据浏览器的启发式算法,可能会渲染为“你好世界”,中间不带空格。
-
然后,所有的制表符都会转换为空格字符,所以示例将变为:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> -
之后,任何紧接在另一个空格之后的空格(即使跨越两个独立的行级元素)都会被忽略,因此最终结果为:
html<h1>◦Hello◦<span>World!</span>◦</h1>
这就是为什么人们在访问网页时,会看到“Hello World!”这句话很好地写在页面的顶部,而不是一个奇怪的缩进的“Hello”,但在下面一行有一个更奇怪的缩进的“World!”。
完成上述步骤后,浏览器会处理换行和双向文本,此处我们不予考虑。请注意,在 <h1> 标签开头与 </h1> 标签闭合之间仍存在空白字符,但这些空白字符不会在浏览器中显示。接下来我们将处理此问题,具体将在每行布局时进行。
不同的 white-space-collapse 值会跳过此算法的不同部分:
preserve和break-spaces:跳过整个算法,不发生任何空白字符折叠或转换。preserve-breaks:跳过第二步和第三步,保留换行符。preserve-spaces:跳过整个算法,算法变为仅将制表符和换行符转换为空格。
简而言之,不同类型的空白字符将按以下方式进行折叠和转换:
- 制表符通常转换为空格。
- 若需折叠分段符:
- 连续的分段符序列将折叠为单个分段符。
- 在使用空白字符分隔单词的语言(如英语)中,它们将转换为空白字符;而在不使用空白字符分隔单词的语言(如中文)中,则完全移除。
- 若需折叠空白字符:
- 断行符前后空白字符或制表符将被移除。
- 连续空白字符序列折叠为单个空白字符。
- 保留空白字符时,连续空白字符视为不可断行,但会在每组空白字符末尾进行软换行——即下一行始终从下一个非空白字符开始。但当采用
break-spaces值时,每个空白字符后都可能发生软换行,因此下一行可能以一个或多个空白字符开头。
修剪与定位
在行内和区块格式化上下文中,元素均按行进行排版。行内格式化上下文中,行通过文本换行生成。而在块级格式化上下文中,每个块级元素各自形成独立行。每行布局时,空白字符会继续被处理。让我们通过示例说明其工作原理。
本例中,我们仍像之前那样在注释中标记了空白字符。共有三个仅含空白字符的文本节点:第一个位于首个 <div> 之前,第二个位于两个 <div> 之间,第三个位于第二个 <div> 之后。
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
它会像这样渲染:
示例中的空白字符处理方式总结如下:
备注:该算法可通过 white-space-collapse 属性(或其简写属性 white-space)进行配置。我们将首先假设其默认值(white-space-collapse: collapse),然后探讨不同属性值如何影响该算法。
-
首先,空白字符会像上一节所示那样被折叠,将以下内容:
html<body>⏎ ⇥<div>◦◦Hello◦◦</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>转换为:
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>随后,行布局将根据
<body>建立的块级格式化上下文进行排版。在此示例中,<body>的五个子节点各自作为独立行进行布局。(此代码块中的每行代表渲染布局中的独立行,而非原始 HTML 代码中的行):html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>请注意,如果行过长,每行可能会换行并生成更多行。实际上,浏览器在布局过程中会确定每行的内容。关于文本换行机制的具体原理,我们在此不作赘述。
-
行首的空白字符序列将被移除,因此示例变为:
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
此时保留的每个制表符均按
tab-size进行渲染。这仅当white-space-collapse设置为preserve或break-spaces时生效,因为其他所有设置都会将制表符转换为空格符。 -
行尾的空白字符序列将被移除,因此上文变为:
html<body> <div>Hello</div> <div>World!</div> </body>当前存在的三个空行在最终布局中不会占用任何空间,因为它们不包含任何可见内容。因此页面最终仅有两行会占据空间。浏览网页的用户会看到“Hello”和“World!”分别显示在两行上,这完全符合预期中两个
<div>元素的布局效果。浏览器本质上会忽略 HTML 代码中包含的所有空白字符。
不同的 white-space-collapse 值会跳过此算法的不同部分:
preserve和break-spaces:跳过整个算法(除了第三步),不发生任何空白字符折叠或转换。preserve-breaks:跳过整个算法,因此行首行尾的空白字符得以保留。preserve-spaces:应用与collapse值相同的算法。
DOM API 如何处理空白字符
如前所述,DOM 会保留空白字符。这意味着当你获取 Node.textContent 时,将得到 HTML 源代码中原始书写的文本内容;而获取 Node.childNodes 时,则会获取所有文本节点——包括仅包含空白字符的节点。
并非所有 DOM API 都会保留空白字符;某些 API 设计上处理的是渲染后的文本。例如,HTMLElement.innerText 返回的文本完全与渲染效果一致,所有空白字符均被折叠并修剪。Selection.toString() 返回的是粘贴时的文本形式,通常意味着空白字符会被折叠。然而在 Firefox 中(如上文折叠与转换章节所述,该浏览器会折叠汉字间的空白字符),折叠后的空白字符在 toString() 返回的字符串和粘贴文本中均得以保留。
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
解决空白字符节点常见问题
由于 CSS 处理规则,空白字符节点对网站访问者不可见,但它们可能干扰某些依赖 DOM 精确结构的布局和 DOM 操作。下面我们来看看一些常见问题及其解决方法。
行内和行内块元素之间的空白字符处理
让我们来看看空白节点的一个布局问题:行内元素与行内块元素之间的空白字符。正如我们之前在行内元素和块元素中看到的,大多数空白字符会被忽略,但空格等分隔单词的字符会保留。这些最终进入布局的额外空白有助于分隔句子中的单词。
inline-block 元素的表现则更具趣味性:其外部行为类似行内元素,内部则表现为块级元素(常用于并排展示同一行内更复杂的 UI 组件,如导航菜单项)。相邻内联元素或内联块元素间的任何空白字符,都会在布局中生成间距——如同文本中词语间的空格。(这常令开发者意外,因为它们属于块级元素,而块级元素通常不显示额外空白字符。)
请看这个示例(与之前相同,我们在 HTML 代码中添加了注释以显示空白字符):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
渲染如下所示:
你可能不希望块之间存在间隙。根据具体使用场景(例如头像列表或水平导航按钮行),通常希望元素紧密排列,并能自行控制间距。
Firefox 开发者工具的 HTML 检查器能高亮文本节点,并精确显示元素实际占用的区域。当怀疑额外边距或意外空白字符导致间隙时,此功能可帮助排查问题。
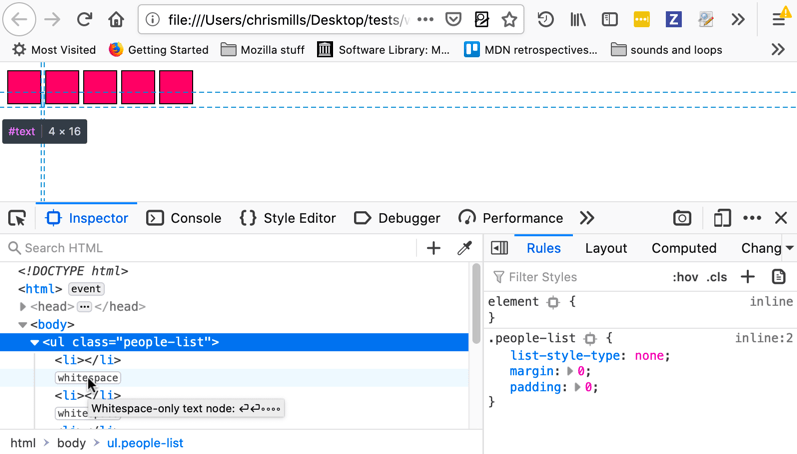
有一些解决问题的方法:
-
使用弹性盒来创建水平项目列表,而非尝试
inline-block方案。弹性盒能自动处理间距和对齐问题,无疑是更优的选择:cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
若需依赖
inline-block,可将列表的font-size设为0。此方法仅适用于未采用em单位定义区块尺寸的情况(因em基于font-size计算,区块尺寸最终也会被设为0)。在此场景下采用rem单位是更优选择:cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
或者,你可以在列表项中设置负外边距:
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
你也可以通过避免在
<li>项中使用空白字符来解决问题:html<li> ... </li><li> ... </li>
在 DOM 中使用空白字符
如前所述,在渲染时空白字符会被折叠和修剪,但在 DOM 中得以保留。这在使用 JavaScript 进行 DOM 操作时可能带来一些陷阱。例如,当你持有父节点引用并试图通过 Node.firstChild 操作其首个子元素时,若父节点起始标签后存在异常空白字符节点,将导致错误结果——文本节点会被选中而非目标元素。
另一个例子是:若需根据元素是否为空(无子节点)对子集进行操作,可使用 Node.hasChildNodes() 方法。但若目标元素中存在文本节点,则可能导致错误结果。
以下 JavaScript 代码展示了若干便于处理 DOM 中空白字符的函数:
/**
* 以下所谓的“空白字符”代表:
* "\t" TAB \u0009(制表符)
* "\n" LF \u000A(换行符)
* "\r" CR \u000D(回车符)
* " " SPC \u0020(真正的空格符)
*
* 不使用 JavaScript 的“\s”,因为它包含非断行空白字符等其他字符。
*/
/**
* 决定某节点的文本内容是否全为空白字符。
*
* @param nod 实现了 `CharacterData` 接口的节点(即 `Text`、`Comment` 或 `CDATASection` 节点)。
* @return 若 `nod` 的文本内容全为空白字符则返回 `true`,否则返回 `false`。
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* 决定是否应在遍历时略过某节点。
*
* @param nod 实现了 `Node` 接口的对象
* @return 如果节点符合以下条件,则返回 `true`:
* 1. 全部为空白字符的 `Text` 节点
* 2. 为 `Comment` 节点
* 否则返回 `false`。
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // 注释节点
(nod.nodeType === 3 && is_all_ws(nod))
); // 所有字符都是空白字符的文本节点
}
/**
* 跳过完全由空白字符或注释组成的节点的 `previousSibling` 版本。
*(通常 `previousSibling` 是所有 DOM 节点的属性,用于返回紧邻在引用节点之前的兄弟节点——即同父子节点中位于其前面的子节点。)
*
* @param sib 节点引用。
* @return 根据 `isIgnorable` 判断,`sib` 最近的前一个非可忽略兄弟节点;若不存在此类节点,则返回 `null`。
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* 此为会跳过空白字符节点及注释节点的 `nextSibling` 函数
*
* @param sib 节点引用。
* @return 根据 `isIgnorable` 判断,`sib` 最近的下一个非可忽略兄弟节点;若不存在此类节点,则返回 `null`。
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* 跳过完全由空白字符或注释组成的节点的 `lastChild` 版本。
*(通常 `lastChild` 是所有 DOM 节点的属性,用于获取引用节点直接包含的最后一个子节点。)
*
* @param par 节点引用。
* @return 根据 `isIgnoreable` 判断,`sib` 的最后一个子节点;若不存在此类节点,则返回 `null`。
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* 此为会跳过空白字符节点及注释节点的 `firstChild` 函数
*
* @param par 节点引用。
* @return 根据 `isIgnoreable` 判断,`sib` 的第一个子节点;若不存在此类节点,则返回 `null`。
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* 去除了开头和结尾的空白字符,并将所有空白字符规范化为单个空白字符的 `data` 版本。
*(通常,`data` 是文本节点的属性,用于提供该节点的文本内容。)
*
* @param txt 欲返回其中数据的文本节点
* @return 文本节点的内容,其中空白字符已经折叠。
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
下面的代码演示了上面这些工具函数的使用方法。具体操作是,遍历一个子节点全部为元素节点的元素,找到所包含的第一个节点为一个文本内容为 "这是第三自然段" 的文本节点的那个子元素,并修改该子元素的 class 属性及其第一个文本节点的文字内容。
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "这是第三自然段") {
cur.className = "magic";
cur.firstChild.textContent = "这是修改后的自然段";
}
cur = nodeAfter(cur);
}