Negociação de conteúdo
No HTTP, negociação de conteúdo é o mecanismo que é usado para servir diferentesrepresentações de um recurso no mesmo URI, de forma que o agente do usuáriopossa especificar qual é a melhor representação adequada ao usuário(por exemplo, qual idioma de um documento, qual formato de imagem ouqual codificação de conteúdo)
Princípios da negociação do conteúdo
Um documento específico é denominado recurso. Quando um cliente quer obtê-lo, ele o requisita usando sua URL. O servidor usa esta URL para escolherum das variantes que ele provê - cada variante sendo chamada de representação - e retorna essa representação específica para o cliente. O recurso de forma geral, bem como suas representações, têm uma URL específica. Como uma representação específica é escolhida quando um recurso é chamado é determinado pela negociação de conteúdo e existem algumas maneiras de negociar entre entre o cliente e o servidor.
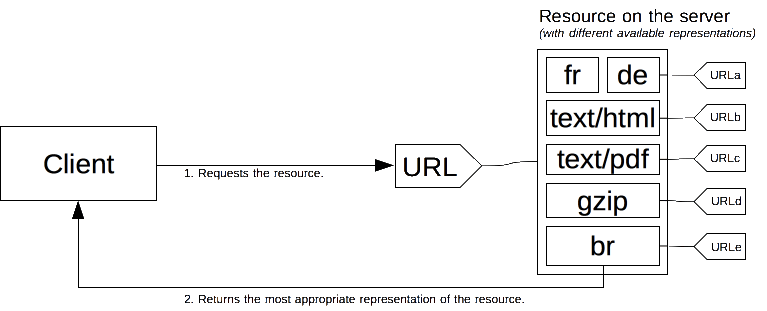
A determinação da representação mais adequada é feita através de um dos dois mecanismos:
- Cabeçalhos HTTP específicos pelo cliente (negociação com base no servidor ou negociação pró-ativa)
- Os códigos de resposta do servidor {HTTPStatus("300")}} (Múltiplas escolhas) or
406(Não aceitável) (negociação baseada no agente ou negociação reativa), que são usados como mecanimos de reserva (fallback).
Ao longo dos anos, outras propostas de negociação de conteúdo, como negociação de conteúdo transparente e o cabeçalho Alternates foram propostas. Elas falharam em ganhar apoio e foram abandonadas.
Negociação baseada no servidor
Na negociação baseada no servidor, ou negociação proativa, o navegador (ou outro tipo de agente do usuário) envia diversos cabeçalhos HTTP junto com a URL. Estes cabeçalhos descrevem a escolha preferida do usuário. O servidor usa-os como sugestões e um algoritmo intero escolhe o melhor conteúdo para ser servido ao usuário. O algoritmo é específico para cada servidor e não é definido no padrão. Veja, por-exemplo, o algoritmo de negociação do Apache 2.2.
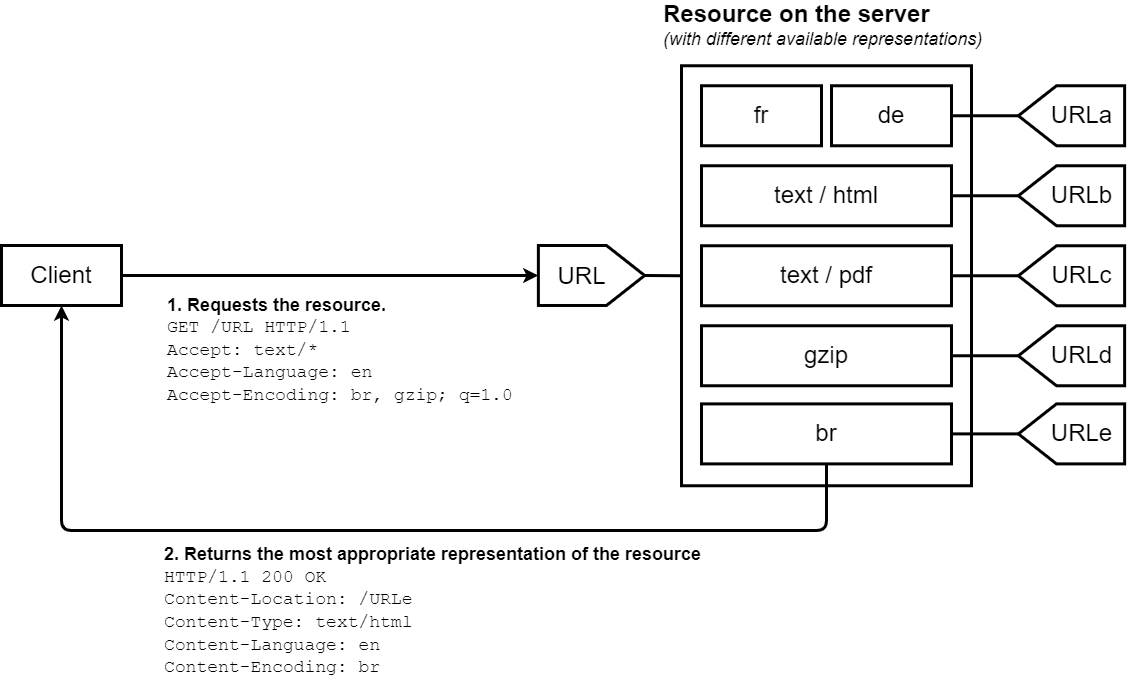
O padrão HTTP/1.1 define uma lista de cabeçalhos-padrão que iniciam a negociação baseada no servidor (Accept, Accept-Charset, Accept-Encoding, Accept-Language). Apesar do User-Agent não estar formalmente na lista, ele é, às vezes, também usado para enviar uma representação específica do recurso requisitado, apesar disso não ser considerado uma boa prática. O servidor usa o cabeçalho Vary para indicar quais cebeçalhos de fato foram usados na negociação do conteúdo (ou, mais precisamente, nos cabeçahos de resposta associados), de forma que caches possam funcionar de forma otimizada.
Além desses, existe uma proposta experimental para adicionar mais cabeçalhos à lista dos disponíveis, as chamadas sugestões do cliente. Sugestões do cliente indicam qual é o tipo do dispositivo em que o agente do usuário roda (por-exemplo, se é um computador de mesa ou um dispositivo móvel).
Mesmo sendo a negociação com base no servidor a forma mais comum de concordar com uma representação específica de um recurso, ela ainda assim tem algumas desvantagens:
- O servidor não tem conhecimento total sobre o navegador. Mesmo com a extensão das Sugestões do cliente, o servidor continua sem saber completamente quais são as capacidades do navegador. Diferente da negociação de conteúdo reativa, onde o cliente faz uma escolha, a escolha do servidor é, até certo ponto, arbitrária.
- A informação do cliente é bastante verbosa (a compressão de cabeçalhos do HTTP/2 mitiga este problema) e um risco à privacidade (impressão digital HTTP).
- Como diversas representações de um recurso são enviadas, caches compartilhados são menos eficiantes e, implementações de servidor, mais complexas.
The Accept header
The Accept header lists the MIME types of media resources that the agent is willing to process. It is comma-separated lists of MIME types, each combined with a quality factor, a parameter indicating the relative degree of preference between the different MIME types.
The Accept header is defined by the browser, or any other user-agent, and can vary according to the context, like fetching an HTML page or an image, a video, or a script: It is different when fetching a document entered in the address bar or an element linked via an <img>, <video> or <audio> element. Browsers are free to use the value of the header that they think is the most adequate; an exhaustive list of default values for common browsers is available.
The Accept-CH header
Nota: This is part of an experimental technology called Client Hints. Initial support is in Chrome 46 or later. The Device-Memory value is in Chrome 61 or later.
The experimental Accept-CH lists configuration data that can be used by the server to select an appropriate response. Valid values are:
| Value | Meaning |
|---|---|
Device-Memory |
Indicates the approximate amount of device RAM. This value is an approximation given by rounding to the nearest power of 2 and dividing that number by 1024. For example, 512 megabytes will be reported as 0.5. |
DPR |
Indicates the client's device pixel ratio. |
Viewport-Width |
Indicates the layout viewport width in CSS pixels. |
Width |
Indicates the resource width in physical pixels (in other words the intrinsic size of an image). |
The Accept-Charset header
The Accept-Charset header indicates to the server what kinds of character encodings are understood by the user-agent. Traditionally, it was set to a different value for each locale for the browser, like ISO-8859-1,utf-8;q=0.7,*;q=0.7 for a Western European locale.
With UTF-8 now being well-supported, being the preferred way of encoding characters, and to guarantee better privacy through less configuration-based entropy, browsers omit the Accept-Charset header: Internet Explorer 8, Safari 5, Opera 11, Firefox 10 and Chrome 27 have abandoned this header.
The Accept-CH-Lifetime header
Nota: This is part of an experimental technology called Client Hints and is only available in Chrome 61 or later.
The Accept-CH-Lifetime header is used with the Device-Memory value of the Accept-CH header and indicates the amount of time the device should opt-in to sharing the amount of device memory with the server. The value is given in miliseconds and it's use is optional.
The Accept-Encoding header
The Accept-Encoding header defines the acceptable content-encoding (supported compressions). The value is a q-factor list (e.g.: br, gzip;q=0.8) that indicates the priority of the encoding values. The default value identity is at the lowest priority (unless otherwise declared).
Compressing HTTP messages is one of the most important ways to improve the performance of a Web site, it shrinks the size of the data transmitted and makes better use of the available bandwidth; browsers always send this header and the server should be configured to abide to it and to use compression.
The Accept-Language header
The Accept-Language header is used to indicate the language preference of the user. It is a list of values with quality factors (like: "de, en;q=0.7"). A default value is often set according the language of the graphical interface of the user agent, but most browsers allow to set different language preferences.
Due to the configuration-based entropy increase, a modified value can be used to fingerprint the user, it is not recommended to change it and a Web site cannot trust this value to reflect the actual wish of the user. Site designers must not be over-zealous by using language detection via this header as it can lead to a poor user experience:
- They should always provide a way to overcome the server-chosen language, e.g., by providing a language menu on the site. Most user-agents provide a default value for the
Accept-Languageheader, adapted to the user interface language and end users often do not modify it, either by not knowing how, or by not being able to do it, as in an Internet café for instance. - Once a user has overridden the server-chosen language, a site should no longer use language detection and should stick with the explicitly-chosen language. In other words, only entry pages of a site should select the proper language using this header.
The User-Agent header
Nota: Though there are legitimate uses of this header for selecting content, it is considered bad practice to rely on it to define what features are supported by the user agent.
The User-Agent header identifies the browser sending the request. This string may contain a space-separated list of product tokens and comments.
A product token is a name followed by a '/' and a version number, like Firefox/4.0.1. There may be as many of them as the user-agent wants. A comment is a free string delimited by parentheses. Obviously parentheses cannot be used in that string. The inner format of a comment is not defined by the standard, though several browser put several tokens in it, separated by ';'.
The Vary response header
In opposition to the previous Accept-* headers which are sent by the client, the Vary HTTP header is sent by the web server in its response. It indicates the list of headers used by the server during the server-driven content negotiation phase. The header is needed in order to inform the cache of the decision criteria so that it can reproduce it, allowing the cache to be functional while preventing serving erroneous content to the user.
The special value of '*' means that the server-driven content negotiation also uses information not conveyed in a header to choose the appropriate content.
The Vary header was added in the version 1.1 of HTTP and is necessary in order to allow caches to work appropriately. A cache, in order to work with server-driven content negotiation, needs to know which criteria was used by the server to select the transmitted content. That way, the cache can replay the algorithm and will be able to serve acceptable content directly, without more request to the server. Obviously, the wildcard '*' prevents caching from occurring, as the cache cannot know what element is behind it.
Agent-driven negotiation
Server-driven negotiation suffers from a few downsides: it doesn't scale well. There is one header per feature used in the negotiation. If you want to use screen size, resolution or other dimensions, a new HTTP header must be created. Sending of the headers must be done on every request. This is not too problematic with few headers, but with the eventual multiplications of them, the message size would lead to a decrease in performance. The more precise headers are sent, the more entropy is sent, allowing for more HTTP fingerprinting and corresponding privacy concern.
From the beginnings of HTTP, the protocol allowed another negotiation type: agent-driven negotiation or reactive negotiation. In this negotiation, when facing an ambiguous request, the server sends back a page containing links to the available alternative resources. The user is presented the resources and choose the one to use.
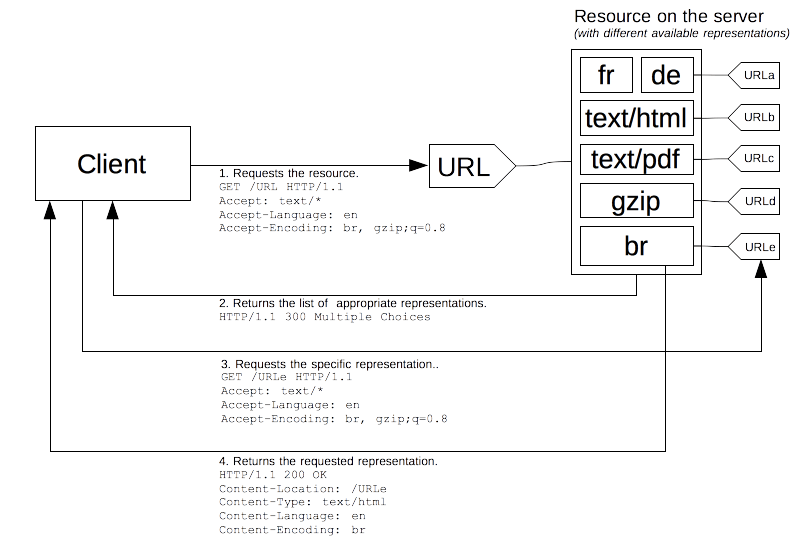
Unfortunately, the HTTP standard does not specify the format of the page allowing to choose between the available resource, which prevents to easily automatize the process. Besides falling back to the server-driven negotiation, this method is almost always used in conjunction with scripting, especially with JavaScript redirection: after having checked for the negotiation criteria, the script performs the redirection. A second problem is that one more request is needed in order to fetch the real resource, slowing the availability of the resource to the user.