JavaScript debugging and error handling
In this lesson, we will return to the subject of debugging JavaScript (which we first looked at in What went wrong?). Here we will delve deeper into techniques for tracking down errors and explain how to code defensively and handle errors in your code, avoiding problems in the first place.
| Prerequisites: | An understanding of HTML and the fundamentals of CSS, familiarity with JavaScript basics as covered in previous lessons. |
|---|---|
| Learning outcomes: |
|
Recap on types of JavaScript error
Earlier in the module, in What went wrong?, we looked broadly at the kinds of error that can occur in JavaScript programs, and said that they can be roughly broken down into two types — syntax errors and logic errors. We also helped you to make sense of some common types of JavaScript error message, and showed you how to do some simple debugging using console.log() statements.
In this article, we will look more deeply at the tools available for tracking down errors, and also look at ways to prevent errors in the first place.
Linting your code
You should validate your code first before trying to track down specific errors. Make use of the W3C's Markup validation service, CSS validation service, and a JavaScript linter such as ESLint to make sure your code is valid. This will likely reveal some errors, which you can then fix, allowing you to concentrate on the remaining errors.
Code editor plugins
It is not very convenient to have to copy and paste your code into a web page to check its validity over and over again. We'd recommend installing a linter plugin in your code editor, to report errors as you write your code. Try searching for ESLint in your code editor's plugins or extensions list and installing it.
Common JavaScript problems
There are several common JavaScript problems that you will want to be mindful of, such as:
- Basic syntax and logic problems (again, check out Troubleshooting JavaScript).
- Making sure variables, etc. are defined in the correct scope, and you are not running into conflicts between items declared in different places (see Function scope and conflicts).
- Confusion about
this, in terms of what scope it applies to, and therefore if its value is what you intended. You can read What is "this"? for a light introduction; you should also study examples like this one, which shows a typical pattern of saving athisscope to a separate variable, then using that variable in nested functions so you can be sure you are applying functionality to the correctthisscope. - Incorrectly using functions inside loops that iterate with a global variable (more generally, "getting the scope wrong").
For example, in bad-for-loop.html (see source code), we loop through 10 iterations using a variable defined with var, each time creating a paragraph and adding an onclick event handler to it. When clicked, we want each one to display an alert message containing its number (the value of i at the time it was created). Instead, they all report i as 11 — because the for loop does all its iterating before nested functions are invoked.
The easiest solution is to declare the iteration variable with let instead of var—the value of i associated with the function is then unique to each iteration. See good-for-loop.html (see the source code also) for a version that works.
- Making sure asynchronous operations have completed before trying to use the values they return. This usually means understanding how to use promises: using
awaitappropriately or running the code to handle the result of an asynchronous call in the promise'sthen()handler. See How to use promises for an introduction to this topic.
Note: Buggy JavaScript Code: The 10 Most Common Mistakes JavaScript Developers Make has some nice discussions of these common mistakes and more.
The Browser JavaScript console
Browser developer tools have many useful features for debugging JavaScript. For a start, the JavaScript console will report errors in your code.
Make a local copy of our fetch-broken example (see the source code also).
If you look at the console, you'll see an error message. The exact wording is browser-dependent, but it will be something like: "Uncaught TypeError: heroes is not iterable", and the referenced line number is 25. If we look at the source code, the relevant code section is this:
function showHeroes(jsonObj) {
const heroes = jsonObj["members"];
for (const hero of heroes) {
// …
}
}
So the code falls over as soon as we try to use jsonObj (which, as you might expect, is supposed to be a JSON object). This is supposed to be fetched from an external .json file using the following fetch() call:
const requestURL =
"https://mdn.github.io/learning-area/javascript/oojs/json/superheroes.json";
const response = fetch(requestURL);
populateHeader(response);
showHeroes(response);
However, this fails.
The Console API
You may already know what is wrong with this code, but let's look at how you could investigate it. We'll start with the Console API, which allows JavaScript code to interact with the browser's JavaScript console. It has several features available; you've already encountered console.log(), which prints a custom message to the console.
Try adding a console.log() call to log the return value of fetch(), like this:
const requestURL =
"https://mdn.github.io/learning-area/javascript/oojs/json/superheroes.json";
const response = fetch(requestURL);
console.log(`Response value: ${response}`);
populateHeader(response);
showHeroes(response);
Refresh the page in the browser. This time, before the error message, you'll see a new message logged to the console:
Response value: [object Promise]
The console.log() output shows that the return value of fetch() is not the JSON data, it's a Promise. The fetch() function is asynchronous: it returns a Promise that is fulfilled only when the actual response has been received from the network. Before we can use the response, we have to wait for the Promise to be fulfilled.
console.error() and call stacks
As a brief digression, let's try using a different console method to report the error — console.error(). In your code, replace
console.log(`Response value: ${response}`);
with
console.error(`Response value: ${response}`);
Save your code and refresh the browser; you'll now see the message reported as an error, with the same color and icon as the uncaught error below it. In addition, you'll see an expand/collapse arrow next to the message. If you press this, you'll see a single line indicating the line in the JavaScript file in which the error originated. In fact, the uncaught error line also has this, but it has two lines:
showHeroes http://localhost:7800/js-debug-test/index.js:25 <anonymous> http://localhost:7800/js-debug-test/index.js:10
This means that the error is caused by the showHeroes() function, line 25, as we noted earlier. If you look at your code, you'll see that the anonymous call on line 10 is calling showHeroes(). These lines are referred to as a call stack, and can be really useful when trying to track down the source of an error involving several different locations in your code.
The console.error() call isn't particularly useful in this case, but it can be useful for generating a call stack if one is not already available.
Fixing the error
Anyway, let's get back to trying to fix our error. We can access the response from the fulfilled Promise by chaining the then() method onto the end of the fetch() call. We can then pass the resulting response value into the functions that accept it, like this:
fetch(requestURL).then((response) => {
populateHeader(response);
showHeroes(response);
});
Save and refresh, and see if your code is working. Spoiler alert — the above change has not fixed the problem. Unfortunately, we still have the same error!
Note:
To summarize, any time something is not working and a value does not appear to be what it is meant to be at some point in your code, you can use console.log(), console.error(), or another similar function to print out the value and see what is happening.
Using the JavaScript debugger
Let's investigate this problem further using a more sophisticated feature of browser developer tools: the JavaScript debugger, as it is called in Firefox.
Note: Similar tools are available in other browsers; the Sources tab in Chrome, Debugger in Safari (see Safari Web Development Tools), etc.
In Firefox, the Debugger tab looks like this:

- On the left, you can select the script you want to debug (in this case we have only one).
- The center panel shows the code in the selected script.
- The right-hand panel shows useful details about the current environment — Breakpoints, Callstack, and currently active Scopes.
The main feature of such tools is the ability to add breakpoints to code — these are points where the execution of the code stops, and at that point you can examine the environment in its current state and see what is going on.
Let's explore using breakpoints:
- The error is being thrown at the same line as before —
for (const hero of heroes) {— line 26 in the screenshot below. Click on the line number in the center panel to add a breakpoint to it (you'll see a blue arrow appear over the top of it). - Now refresh the page (Cmd/Ctrl + R) — the browser will pause execution of the code on that line. At this point, the right-hand side will update to show the following:
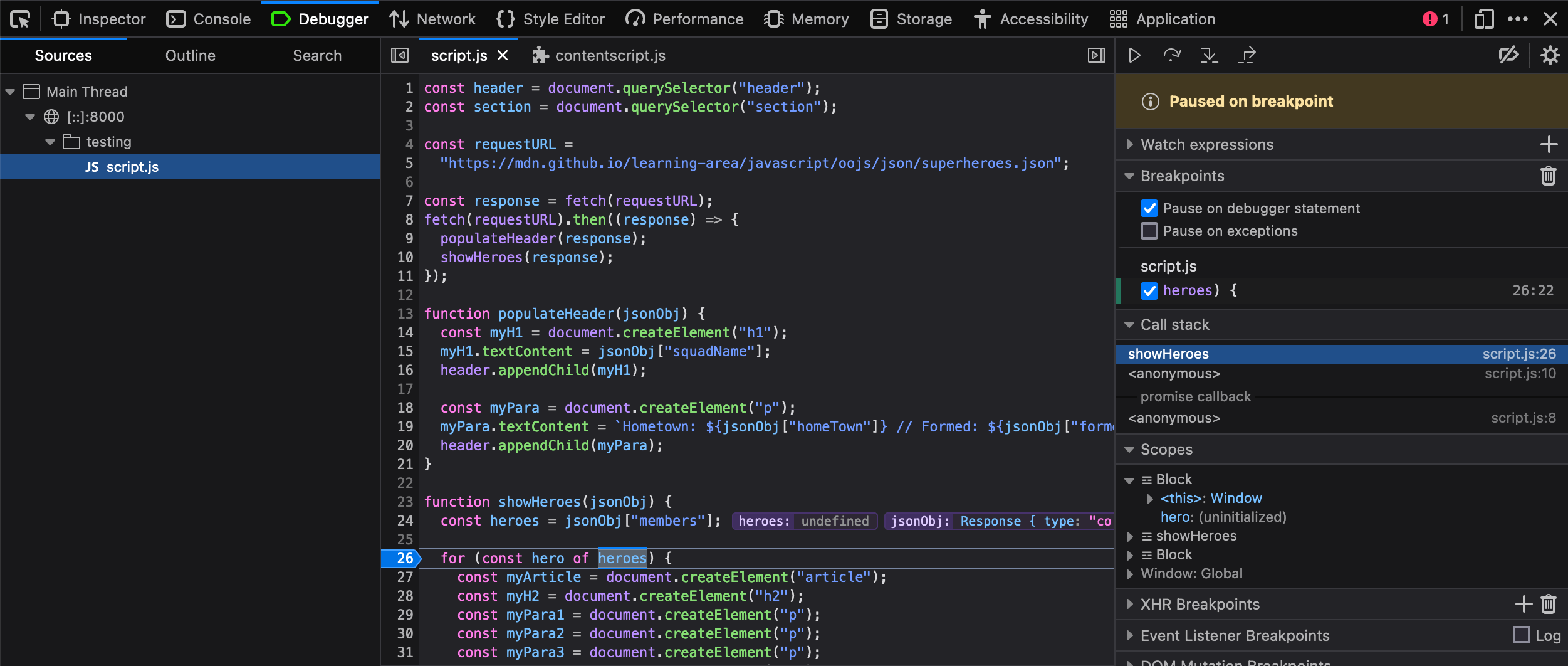
- Under Breakpoints, you'll see the details of the breakpoint you have set.
- Under Call Stack, you'll see a few entries — this is basically the same as the callstack we looked at earlier in the
console.error()section. Call Stack shows a list of the functions that were invoked to cause the current function to be invoked. At the top, we haveshowHeroes(), the function we are currently in, and second we haveonload, which stores the event handler function containing the call toshowHeroes(). - Under Scopes, you'll see the currently active scope for the function we are looking at. We only have three —
showHeroes,block, andWindow(the global scope). Each scope can be expanded to show the values of variables inside the scope when execution is stopped.
We can find out some very useful information in here:
- Expand the
showHeroesscope — you can see from this that the heroes variable isundefined, indicating that accessing themembersproperty ofjsonObj(first line of the function) didn't work. - You can also see that the
jsonObjvariable is storing aResponseobject, not a JSON object.
The argument to showHeroes() is the value the fetch() promise was fulfilled with. This promise is not in JSON format: it is a Response object. An extra step is needed to retrieve the response's content as a JSON object.
We'd like you to try fixing this problem yourself. To get you started, see the documentation for the Response object. If you get stuck, you can find the fixed source code at https://github.com/mdn/learning-area/tree/main/tools-testing/cross-browser-testing/javascript/fetch-fixed.
Note: The debugger tab has many other useful features that are not discussed here. For example, conditional breakpoints and watch expressions. For a lot more information, see the Debugger page.
Handling JavaScript errors in your code
HTML and CSS are permissive — errors and unrecognized features can often be handled due to the nature of the languages. For example, CSS will ignore unrecognized properties, and the rest of the code will often just work. JavaScript, however, is not as permissive as HTML and CSS; if the JavaScript engine encounters mistakes or unrecognized syntax, it will often throw errors.
Let's explore a common strategy for handling JavaScript errors in your code. The following sections are designed to be followed by making a copy of the template file shown below as handling-errors.html on your local machine, adding the code snippets in between the opening and closing <script> and </script> tags, then opening the file in a browser and looking at the output in the devtools JavaScript console.
<!doctype html>
<html lang="en-US">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<title>Handling JS errors</title>
</head>
<body>
<script>
// Code goes below this line
</script>
</body>
</html>
Conditionals
A common use of JavaScript conditionals is to handle errors. Conditionals allow you to run different code depending on the value of a variable. Often, you will want to use this defensively to avoid throwing an error if the value does not exist or is of the wrong type, or to capture an error if the value would cause an incorrect result to be returned, which could cause problems later on.
Let's look at an example. Say we have a function that takes the user's height in inches as an argument and returns their height in meters, to 2 decimal places. This could look like so:
function inchesToMeters(num) {
const mVal = (num * 2.54) / 100;
const m2dp = mVal.toFixed(2);
return m2dp;
}
-
In your example file's
<script>element, declare aconstcalledheightand assign it a value of70:jsconst height = 70; -
Copy the above function below the previous line.
-
Call the function, passing it the
heightconstant as its argument, and log the return value to the console:jsconsole.log(inchesToMeters(height)); -
Load the example in a browser and look at the devtools JavaScript console. You should see a value of
1.78logged to it. -
So this works fine in isolation. But what happens if the provided data is missing or incorrect? Try out these scenarios:
- If you change the
heightvalue to"70"(that is,70expressed as a string), the example should ... still work fine. This is because the calculation on the first line of the string coerces the value into a number data type. This is OK in a simple case like this, but in more complex code, the wrong data can lead to all kinds of bugs, some of them subtle and hard to detect! - If you change
heightto a value that can't be coerced to a number, like"70 inches"or["Bob", 70], orNaN, the example should return the result asNaN. This could cause all kinds of problems, for example, if you want to include the user's height somewhere in the website user interface. - If you remove the
heightvalue altogether (comment it out by adding//at the start of the line), the console will show an error along the lines of "Uncaught ReferenceError: height is not defined", the likes of which could bring your application grinding to a halt.
Obviously, none of these outcomes are great. How do we defend against bad data?
- If you change the
-
Let's add a conditional inside our function to test whether the data is good before we try to do the calculation. Try replacing your current function with the following:
jsfunction inchesToMeters(num) { if (typeof num !== "number" || Number.isNaN(num)) { console.log("A number was not provided. Please correct the input."); return undefined; } const mVal = (num * 2.54) / 100; const m2dp = mVal.toFixed(2); return m2dp; } -
Now, if you try the first two scenarios again, you'll see our slightly more useful message returned, to give you an idea of what needs to be done to fix the problem. You could put anything in there that you like, including trying to run code to correct the value of
num, but this is not advised — this function has one simple purpose, and you should handle correcting the value somewhere else in the system.Note: In the
if()statement, we first test whether the data type ofnumis"number"using thetypeofoperator, then test whetherNumber.isNaN(num)returnsfalse. We have to do this to defend against the specific case ofnumbeing set toNaN, becausetypeof NaNstill returns"number"! -
However, if you try the third scenario again, you will still get the "Uncaught ReferenceError: height is not defined" error thrown at you. You can't fix the fact that a value is not available from inside a function that is trying to use the value.
How do we handle this? It's better to get our function to return a custom error when it doesn't receive the correct data. We'll look at how to do that first, then we'll handle all the errors together.
Throwing custom errors
You can throw a custom error at any point in your code using the throw statement, coupled with the Error() constructor. Let's see this in action.
-
In your function, replace the
console.log()line inside theelseblock of your function with the following line:jsthrow new Error("A number was not provided. Please correct the input."); -
Run your example again, but make sure
numis set to a bad (that is, non-number) value. This time, you should see your custom error thrown, along with a useful call stack to help you locate the source of the error (although note that the message still tells us that the error is "uncaught" or "unhandled"). OK, so errors are annoying, but this is way more useful than running the function successfully and returning a non-number value that could cause problems later on.
So, how do we handle all those errors then?
try...catch
The try...catch statement is specially designed to handle errors. It has the following structure:
try {
// Run some code
} catch (error) {
// Handle any errors
}
Inside the try block, you try running some code. If this code runs without an error being thrown, all is well, and the catch block is ignored. However, if an error is thrown, the catch block is run, which provides access to the Error object representing the error, and allows you to run code to handle it.
Let's use try...catch in our code.
-
Replace the
console.log()line that calls theinchesToMeters()function at the end of your script with the following block. We are now running ourconsole.log()line inside atryblock, and handling any errors that it returns inside a correspondingcatchblock.jstry { console.log(inchesToMeters(height)); } catch (error) { console.error(error); console.log("Insert code to handle the error"); } -
Save and refresh, and you should now see two things:
- The error message and call stack are as before, but this time, without a label of "uncaught" or "unhandled".
- The logged message "Insert code to handle the error".
-
Now try updating
numto a good (number) value, and you'll see the result of the calculation logged, with no error message.
This is significant — any thrown errors are now handled, so they won't cause the application to crash. You can run whatever code you like to handle the error. Above, we are logging a basic message, but for example, you could call the function that asks the user to enter their height again, but this time ask them to correct the input error. You could even use an if...else statement to run different error handling code depending on what type of error is returned.
Feature detection
Feature detection is useful when you're planning to use new JavaScript features that might not be supported in all browsers. You can test for the feature, then conditionally run code to provide an acceptable experience in browsers that support the feature, and those that don't. As a quick example, the Geolocation API (which exposes available location data for the device the web browser is running on) has a main entry point for its use — a geolocation property available on the global Navigator object. Therefore, you can detect whether the browser supports geolocation or not by using a similar if() structure to what we saw earlier:
if ("geolocation" in navigator) {
navigator.geolocation.getCurrentPosition((position) => {
// show the location on a map, perhaps using the Google Maps API
});
} else {
// Give the user a choice of static maps instead
}
You can find some more feature detection examples in Alternatives to UA sniffing.
Finding help
There are many other issues you'll encounter with JavaScript (and HTML and CSS!), making knowledge of how to find answers online invaluable.
Among the best sources of support information are MDN, stackoverflow.com, and caniuse.com.
- To use MDN, most people do a search engine search of the technology they are trying to find information on, plus the term "mdn", for example, "mdn HTML video".
- caniuse.com provides support information, along with a few useful external resource links. For example, see https://caniuse.com/#search=video (you have to enter the feature you are searching for into the text box).
- stackoverflow.com (SO) is a forum site where you can ask questions and have fellow developers share their solutions, look up previous posts, and help other developers. Search for an answer to your question to see if one exists already, before posting a new question. For example, we searched for "disabling autofocus on HTML dialog" on SO, and very quickly came up with Disable showModal auto-focusing using HTML attributes.
Aside from that, try searching your favorite search engine for an answer to your problem. It is often useful to search for specific error messages if you have them — other developers will be likely to have had the same problems as you.
Summary
So that's JavaScript debugging and error handling. Simple huh? Maybe not so simple, but this article should at least give you a start and some ideas on how to tackle the JavaScript-related problems you will come across.
That's it for the Dynamic scripting with JavaScript module; congratulations on reaching the end! In the next module, we'll help you explore JavaScript frameworks and libraries.