Depurar el HTML
Escribir HTML es fácil, pero ¿qué pasa si algo va mal y desconocemos dónde está el error de codificación? En este artículo veremos varias herramientas que nos ayudarán a arreglar errores en HTML.
| Prerrequisitos: | Estar familiarizado con los principios básicos de HTML, como los vistos en el apartado Empezar con el HTML, Conocimientos básicos de aplicación de formato a textos con HTML y Creación de hiperenlaces. |
|---|---|
| Objetivo: | Aprender el funcionamiento básico de las herramientas de depuración de problemas de código en HTML. |
Depurar no debe asustarnos
Cuando escribimos cualquier tipo de código, normalmente todo va bien, hasta ese fatídico momento en el que ocurre un error, hemos hecho algo mal y el código no funciona, o no funciona del todo, no lo suficientemente bien. Por ejemplo, el dibujo siguiente muestra un error de compilación de un programa sencillo escrito en lenguaje Rust.
 En el ejemplo, el mensaje de error es fácilmente comprensible: "unterminated double quote string" (comillas sin cerrar en el texto). Si analizamos el listado de código, observamos que en
En el ejemplo, el mensaje de error es fácilmente comprensible: "unterminated double quote string" (comillas sin cerrar en el texto). Si analizamos el listado de código, observamos que en println!(Hello, world!"); faltan una comillas. Pero, los mensajes de error pueden complicarse con facilidad y su interpretación ser menos sencilla a medida que los programas aumentan en tamaño, e incluso casos sencillo pueden llegar a intimidar a alguien que no sabe nada de Rust.
Sin embargo, la depuración no nos debe asustar; la clave para sentirnos cómodos con la escritura y la depuración de cualquier lenguaje o código es la familiaridad, tanto con el lenguaje como con las herramientas.
HTML y depuración
HTML no es tan complicado de entender como Rust; HTML no se compila por separado antes de que el navegador lo analice (se interpreta, no se compila). Y la sintaxis de los elementos de HTML es mucho más sencilla de entender que la de cualquier lenguaje de programación real como Rust, JavaScript o Python. La forma en que los navegadores ejecutan HTML es más permisiva que la de los otros lenguajes, cosa que es buena y mala a la vez.
Código permisivo
¿Qué queremos decir con permisivo? Bien, normalmente cuando hacemos algo mal al codificar, suele haber dos tipos de error:
- Errores sintácticos: Son errores de escritura en el código que impiden que el programa funcione, como el error en Rust de arriba. Suelen ser fáciles de arreglar si estamos familiarizados con las herramientas adecuadas y sabemos el significado de los mensajes de error.
- Errores lógicos: En estos errores la sintaxis es correcta, pero el código no hace lo que debería, por lo que el programa funciona de forma incorrecta. Estos errores son, por lo general, más difíciles de solucionar que los sintácticos, porque no hay mensajes de error que nos avisen de ellos.
HTML en sí mismo no suele producir errores sintácticos porque los navegadores son permisivos con ellos; o sea, el código se sigue ejecutando ¡aun si hay errores! Los navegadores disponen de reglas internas para saber cómo interpretar los errores de marcado incorrecto que encuentran, y seguirán funcionando aunque no produzcan el resultado esperado. Esto puede también ser un problema, por supuesto.
Nota: La ejecución de HTML es permisiva porque cuando se creó la web por primera vez, se decidió que el hecho de permitir que la gente publicara su contenido era más importante que el hecho de que la sintaxis fuera totalmente correcta. La web no sería tan popular como lo es hoy en día si se hubiera sido más estricto desde el primer momento.
Aprendizaje activo: Estudio del código permisivo
Es hora de estudiar la naturaleza permisiva del código HTML por nosotros mismos.
-
En primer lugar, hagamos una copia de nuestro ejemplo-demo a depurar y guardémoslo de forma local. Está escrito para generar diversos errores que deberemos descubrir (se dice que el marcado de HTML está mal formado, en contraposición a un marcado bien formado).
-
A continuación, abrámoslo en un navegador; veremos lo siguiente:

-
No parece que esté bien; veamos el código fuente para ver qué podemos hacer (solo mostramos el contenido del <body>):
html<h1>Ejemplos de depuración de HTML</h1> <p>¿Qué causa los errores en HTML? <ul> <li>Elementos no cerrados: Si un elemento <strong>no está cerrado correctamente, su efecto puede extenderse a áreas que no pretendía <li>Elementos mal anidados: anidar elementos correctamente también es muy importante para que el código se comporte correctamente. <strong>negritas <em>negritas enfatizadas?</strong> ¿qué es esto?</em> <li>Atributos no cerrados: otra fuente común de problemas de HTML. Veamos un ejemplo: <a href="https://www.mozilla.org/>enlace a la página de inicio de Mozilla</a> </ul> -
Veamos qué problemas podemos descubrir:
- El elemento
<p>y el<li>no tienen etiquetas de cierre. Si comprobamos el resultado, no parece que haya generado un efecto grave en la representación del lenguaje de marcado, porque es fácil deducir que donde un elemento acaba, debería comenzar otro. - El primer elemento
<strong>no tiene etiqueta de cierre. Este resulta ser un poco más problemático porque no es fácil deducir dónde se supone que termina el elemento. De hecho, el énfasis fuerte se ha aplicado al resto del texto. - Esta sección está mal anidada:
<strong>negritas <em>negritas enfatizadas?</strong> ¿qué es esto?</em>. No es fácil de explicar la forma en que ha sido interpretado, debido al problema anterior. - Al valor del atributo
hrefle faltan las comillas de cierre. Esto parece haber causado el problema más grave: el enlace ha desaparecido totalmente.
- El elemento
-
Ahora veamos lo que el navegador ha mostrado en contraposición al código fuente. Para ello podemos usar las herramientas de desarrollo del navegador. Si no estamos familiarizados con el uso de estas herramientas, echemos un vistazo rápido a Descubrir las herramientas de desarrollo del navegador, y luego continuaremos.
-
En el inspector de objetos (DOM), puedes comprobar la apariencia de cada elemento:

-
Vamos a explorar nuestro código en detalle con el inspector de objetos DOM para ver cómo el navegador ha arreglado nuestros errores de código HTML (lo hemos hecho con Firefox; otros navegadores modernos deberían conducir al mismo resultado):
-
Se han añadido etiquetas de cierre a los párrafos y las líneas de las listas.
-
Al no estar claro el final del elemento
<strong>, el navegador lo ha aplicado individualmente a todos los bloques de texto siguientes, a cada uno le ha añadido su etiquetastrongpropia, desde donde está ¡hasta el final del documento! -
El navegador ha arreglado el anidamiento incorrecto del modo siguiente:
html<strong >negritas <em>negritas enfatizadas</em> </strong> <em>¿qué es esto?</em> -
El enlace a cuyo atributo le faltan las comillas del final ha sido ignorado. La última lista la ha dejado como sigue:
html<li> <strong >Atributos no cerrados: otra fuente común de problemas de HTML. Veamos un ejemplo: </strong> </li>
-
Validación HTML
Con el ejemplo anterior podemos asegurarnos de que nuestro HTML está bien formado, pero ¿cómo? En el ejemplo siguiente podemos comprobar que es bastante fácil buscar entre las líneas y encontrar los errores en documentos pequeños; pero, ¿qué pasa cuando trabajamos con documentos HTML grandes y complejos?
La mejor estrategia es comenzar por pasar tu página HTML por el servicio de validación de etiquetas; fue creado y está mantenido por el W3C, organización que se encarga de definir las especificaciones de HTML, CSS y otras tecnologías web. Esta página web toma un documento HTML como entrada, lo procesa, y genera un informe de dónde están los errores en el documento.

Para validar el HTML, podemos proporcionar al validador una dirección web a la que apuntar, subirle un archivo HTML, o directamente introducirle el código HTML que queremos que revise.
Aprendizaje activo: Validación de un documento HTML
Vamos a probar de validar nuestro documento ejemplo.
- Primero, cargamos el servicio de validación en una pestaña del navegador, si no lo tenemos ya.
- Hacemos clic en la subpestaña Validate by Direct Input.
- Copiamos el código del documento ejemplo (no solo el
body) y lo pegamos en el cuadro de texto grande. - Hacemos clic en el botón Check.
Esto debería proporcionar una lista de errores y otras informaciones:
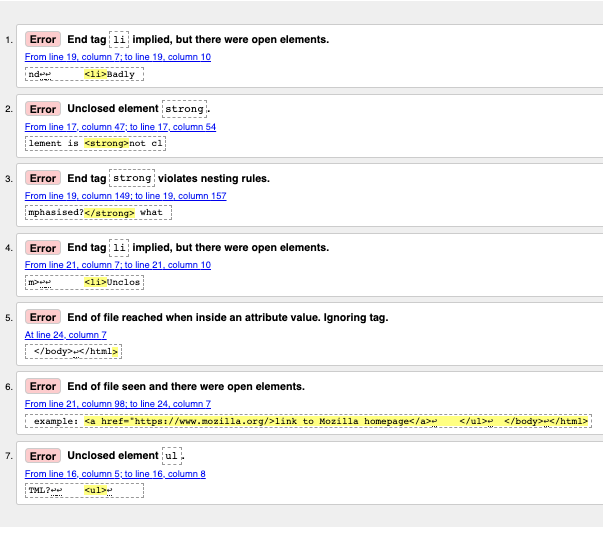
Interpretación de los mensajes de error
La lista de mensajes de error que nos presenta el validador suele ayudar, pero a veces, no resultan muy útiles; con un poco de práctica aprenderemos a interpretar la lista para arreglar nuestro código. Veamos los mensajes de error y su significado. Observamos que cada mensaje se presenta con un número de línea y de columna, para ayudar a localizar el error más fácilmente.
-
"Consider adding a
langattribute to thehtmlstart tag to declare the language of this document.": No se trata de un error, sino de una advertencia (warning). La recomendación es definir siempre un idioma, y este "warning" explica cómo hacerlo.. -
"End tag
liimplied, but there were open elements" (2 instancias): Estos mensajes indican que un elemento que ha sido abierto debe ser cerrado. La etiqueta de cierre se supone, pero no está ahí. La información de la línea/columna apunta a la primera línea después de donde debería estar la etiqueta de cierre; es una buena pista para ver qué pasa. -
"Unclosed element
strong": Un elemento<strong>no ha sido cerrado, y la línea/columna apunta directamente al lugar del error. -
"End tag
strongviolates nesting rules": Este apunta a elementos que están incorrectamente anidados, y la línea/columna nos indica donde están. -
"End of file reached when inside an attribute value. Ignoring tag": Esta es bastante enigmática; se refiere al hecho de que el valor de un atributo no ha sido bien construido, posiblemente cerca del final del archivo porque el final aparece dentro del valor del atributo. El hecho de que el navegador no muestre el enlace nos debería dar una buena pista de qué elemento es el erróneo.
-
"End of file seen and there were open elements": Este es un poco ambiguo, pero básicamente se refiere al hecho de que hay elementos abiertos que necesitan ser cerrados adecuadamente. Los números de línea apuntan a las últimas líneas del archivo, y este mensaje de error viene con una línea de código que indica un ejemplo de un elemento abierto:
ejemplo:
<a href="https://www.mozilla.org/>enlace a la página de inicio de Mozilla</a> ↩ </ul>↩ </body>↩</html>Nota: Un atributo al que le falten las comillas de cierre puede ser un elemento abierto, porque el resto del documento será interpretado como si fuera parte de este atributo.
-
Unclosed element
ul: Este no ayuda mucho, porque el elemento<ul>está cerrado correctamente. Este error se debe a que el elemento<a>no ha sido cerrado, ya que faltan las comillas de cierre.
No debemos preocuparnos si no podemos corregir todos los mensajes de error; es práctico tratar de arreglar unos pocos errores cada vez y volver a pasar el validador para ver los que quedan. A veces, al arreglar unos cuantos se arreglan automáticamente otros muchos; con frecuencia muchos errores los causa uno solo en un efecto dominó.
Sabremos que todos los errores están arreglados cuando veamos el mensaje siguiente:

Resumen
Pues hasta aquí una introducción al depurado de HTML, que nos proporcionará habilidades para cuando comencemos a depurar CSS, JavaScript y otros lenguajes más adelante en nuestros trabajos. Este apartado también constituye el final de la introducción al módulo de artículos de aprendizaje de HTML; ahora podemos hacer los test de prueba: el primero de los cuales está en el enlace siguiente.