Express 教學 3:使用資料庫(Mongoose)
本文簡短介紹數據庫,以及如何搭配 Node / Express 應用,使用數據庫。接下來會演示我們如何使用 Mongoose,為本地圖書館提供數據庫存取。本文說明物件要求與模型如何宣告,主要的欄位型態,以及基本驗證。本文也簡短演示一些存取模型數據的主要方法。
| 前置條件: | Express 教學 2: 創建一個骨架網站 |
|---|---|
| 目標: | 能夠使用Mongoose設計並創造自己的模型。 |
概覽
圖書館職員會使用本地圖書館網站,存放書本和借書者訊息。圖書館使用者會用網站瀏覽與尋找書本,看看是否有可以藉閱的書本複本,然後預約或者藉閱。為了有效率地存放與取用訊息,我們將把它存放到數據庫。
Express 應用可以使用許多不同的數據庫,並且有好幾種方法可以執行創建 Create、讀取 Read、更新 Update 和刪除 Delete (CRUD) 操作。本教程為一些可用的選項,提供簡短的概覽,然後接著詳細演示該選項的特定運行機制。
我可以使用什麼數據庫?
Express 應用程序可以使用 Node 支持的任何數據庫(Express 本身不會為數據庫管理,定義任何特定的附加行為/要求)。有許多流行的選項,包括 PostgreSQL,MySQL,Redis,SQLite 和 MongoDB。
在選擇數據庫時,你應該考慮時間 - 生產力/學習曲線,性能,易複製/備份,成本,社區支持等等。雖然沒有單一的 「最佳」 數據庫,但幾乎任何流行的解決方案,我們的本地圖書館這樣的中小型網站,應該都可以接受。
有關選項的更多訊息,請參閱:數據庫集成(Express docs)。
與數據庫互動的最好方式是什麼?
有兩種與數據庫互動的方法:
- 使用數據庫的原生查詢語言(例如 SQL)
- 使用對像數據模型(「ODM」)/對象關係模型(「ORM」)。 ODM / ORM 將網站的數據表示為 JavaScript 對象,然後將其映射到底層數據庫。一些 ORM 綁定到特定的數據庫,而另一些則提供了一個不特定數據庫的後端。
通過使用 SQL 或數據庫支持的任何查詢語言,都可以獲得最佳性能。 ODM 通常比較慢,因為它們使用翻譯代碼,在對象和數據庫格式之間進行映射,這可能不會使用最有效的數據庫查詢(尤其是如果 ODM 支持不同的數據庫後端,並且必須在各個數據庫所支持的功能方面,做出更大的折衷)。
使用 ORM 的好處是,程序員可以繼續用 JavaScript 對象而不是數據庫語義來思考 — 如果你需要使用不同數據庫(在相同或不同的網站上),那麼尤其如此。他們還提供了一個明顯的地方來執行數據驗證和檢查。
備註:使用 ODM / ORM 通常可以降低開發和維護成本!除非你非常熟悉本地查詢語言,或者性能對你至關重要,否則你應該強烈考慮使用 ODM。
我應該使用哪個 ORM/ODM ?
NPM 套件管理器站點上,有許多 ODM / ORM 解決方案(查看 odm 和 orm 標籤的子集合!)。
在撰寫本文時,受歡迎的幾種解決方案是:
- Mongoose: Mongoose 是一個 MongoDB對象建模工具,用於在異步環境中工作。
- Waterline: 它是從基於 Express 的 Sails web 框架中提取的 ORM。它提供了一個統一的 API,來訪問眾多不同的數據庫,包括 Redis,mySQL,LDAP,MongoDB 和 Postgres。
- Bookshelf: 提供基於 promise 和傳統回調的接口,提供事務支持,eager/嵌套 eager 關係加載,多態關聯以及對一對一,一對多和多對多關係的支持。適用於 PostgreSQL,MySQL 和 SQLite3。
- Objection: 以盡可能簡單的方式,使用 SQL 的全部功能,和底層數據庫引擎(支持 SQLite3,Postgres 和 MySQL)。
- Sequelize 是 Node.js 和 io.js 基於 promise 的 ORM。它支持以下數據庫方言,PostgreSQL,MySQL,MariaDB,SQLite 和 MSSQL,並具有可靠的事務支持,關係,唯讀複本等功能。
一般來說,在選擇解決方案時,你應該考慮提供的功能和 「社區活動」 (下載,貢獻,錯誤報告,文檔質量等)。在撰寫本文時,Mongoose 是迄今為止最受歡迎的 ODM,如果你將 MongoDB 用於你的數據庫,那麼它是一個合理的選擇。
在本地圖書館使用 Mongoose 和 MongoDb
對於本地圖書館示例(以及本主題的其餘部分),我們將使用 Mongoose ODM 來訪問我們的圖書館數據。 Mongoose 是 MongoDB 的前端,MongoDB 是一個使用面向文檔數據模型的開源 NoSQL 數據庫。在 MongoDB 數據庫中,「文檔」 的 「集合」 ,類似於關係數據庫中 「行」 的 「表」。
這種 ODM 和數據庫的結合在 Node 社區中非常流行,部分原因是文檔存儲和查詢系統,看起來非常像 JSON,因此對 JavaScript 開發人員來說很熟悉。
備註:使用 Mongoose 時,你不需要事先了解 MongoDB,但是如果你已經熟悉 MongoDB,Mongoose documentation文檔的一部分會更易於使用和理解。
本教程的其餘部分,將介紹如何為 本地圖書館網站示例,定義和訪問 Mongoose 模式和模型。
設計本地圖書館的模型
在你開始編寫模型之前,花幾分鐘的時間思考,我們需要儲存的數據以及不同對象之間的關係。
我們知道,我們需要儲存有關書籍的訊息(標題,摘要,作者,種類,國際標準書號),以及我們可能有多個副本可用(具有全域唯一 ID,可用狀態等)。我們可能需要存儲有關作者的更多訊息,而不僅僅是他們的名字,並且可能有多個作者,具有相同或相似的名稱。我們希望能夠根據書名,作者,種類和類別對訊息進行分類。
在設計模型時,對於每個「對象」(相關訊息組)都有獨立的模型,是有意義的。在這種情況下,明顯的對像是書籍,書籍實例和作者。
你可能還希望,使用模型來表示選擇列表選項(例如,選擇的下拉列表),而不是將選項硬編碼到網站本身— 在無法預先知道所有選項,或者可能更改時,更建議使用模型來表示。很明顯的,書本類型是這種模型的可能人選(例如科幻小說,法國詩歌等)。
一旦我們決定了我們的模型和字段,我們就需要考慮它們之間的關係。
考慮到這一點,下面的 UML 關聯圖,顯示了我們在這種情況下定義的模型(一個框對應一個模型)。如上所述,我們創建了以下模型,圖書(本書的通用細節),書本實例(系統中可用圖書的特定實際副本的狀態)和作者。我們還決定建立一個種類模型,以便可以動態創建它的值,而不是將下拉選項硬編碼。我們已經決定不為書本實例:狀態BookInstance:status建立模型—我們將硬編碼可接受的值,因為我們不希望這些值發生變化。在下圖每個框中,你可以看到模型名稱,字段名稱和類型,以及方法及其返回類型。
下圖還顯示了模型之間的關係,包括它們的多重性。多重性是圖中顯示可能存在於關係中的每個模型的數量(最大值和最小值)的數字。例如,框之間的連接線,顯示書本Book和種類Genre是相關的。靠近書本Book模型的數字,表明一本書必須有零個或多個種類(你想要多少都可以),而種類Genre旁邊一行的數字,表明它可以有零個或多個相關書籍。
備註:正如我們在下面的Mongoose 入門中所討論的那樣,通常只需要在一個模型中定義文檔/模型之間關係的字段(通過在另一個模型中搜索相關的_id仍然可以找到反向關係)。下面我們選擇在書本綱要(Book schema)中定義 Book/Genre 和 Book/Author 之間的關係,以及書本實例綱要(BookInstance Schema)中 Book/BookInstance 之間的關係。這種選擇有點武斷—我們同樣可以在其他綱要中擁有該字段。

備註:下一節提供了一個基本的入門知識,解釋如何定義和使用模型。在你閱讀它時,請想想我們將如何構建上圖中的每個模型。
Mongoose 入門
本節概述如何將 Mongoose 連接到 MongoDB 數據庫,如何定義模型綱要和模型,以及如何進行基本查詢。
備註:本入門受到 npm 上的Mongoose 快速入門和Mongoose 官方文檔的「深度影響」。
安裝 Mongoose 和 MongoDB
Mongoose 像任何其他依賴項一樣,安裝在你的項目(package.json)中—使用 NPM。要安裝它,請在項目文件夾中,使用以下命令:
npm install mongoose
安裝 Mongoose 會添加所有依賴項,包括 MongoDB 數據庫驅動程序,但它不會安裝 MongoDB 。如果你想安裝一個 MongoDB 服務器,那麼你可以從這裡下載各種操作系統的安裝程序,並在本地安裝。你還可以使用基於雲端的 MongoDB 實例。
備註:對於本教程,我們將使用基於 mLab 雲的數據庫,作為服務沙箱層來提供數據庫。這適用於開發,也對於本教程很有意義,因為它使「安裝」與操作系統無關(數據庫即服務,也是你可能會用於生產環境數據庫的一種方法)。
連接到 MongoDB
Mongoose 需要連接到 MongoDB 數據庫。你可以require()並使用mongoose.connect(),以連接到本地託管的數據庫,如下所示。
//Import the mongoose module
var mongoose = require("mongoose");
//Set up default mongoose connection
var mongoDB = "mongodb://127.0.0.1/my_database";
mongoose.connect(mongoDB);
// Get Mongoose to use the global promise library
mongoose.Promise = global.Promise;
//Get the default connection
var db = mongoose.connection;
//Bind connection to error event (to get notification of connection errors)
db.on("error", console.error.bind(console, "MongoDB connection error:"));
你可以使用mongoose.connection獲取默認的Connection對象。一旦連接,在Connection實例上,將觸發打開事件。
備註:如果需要創建其他連接,可以使用mongoose.createConnection()。這與connect()採用相同形式的數據庫 URI(包含主機,數據庫,端口,選項等),並返回Connection對象。
定義並創建模型
模型使用Schema接口進行定義。Schema 允許你定義存儲在每個文檔中的字段,及其驗證要求和默認值。此外,你可以定義靜態和實例助手方法,以更輕鬆地處理數據類型,以及可以像其他任何字段一樣使用的虛擬屬性,但實際上並不存儲在數據庫中(我們稍後將討論)。
然後,綱要 Schemas 被mongoose.model()方法「編譯」為模型。擁有模型後,你可以使用它來查找,創建,更新和刪除給定類型的對象。
備註:每個模型都映射到 MongoDB 數據庫中的文檔集合。這些文檔將包含模型綱要Schema中定義的字段/綱要型態。
定義綱要 Schemas
下面的代碼片段,顯示了你可以如何定義一個簡單的綱要。首先require()mongoose,然後使用 Schema 構造函數,創建一個新的 Schema 實例,在構造函數的對象參數中,定義其中的各個字段。
//Require Mongoose
var mongoose = require("mongoose");
//Define a schema
var Schema = mongoose.Schema;
var SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
在上面的例子中,我們只有兩個字段,一個字符串和一個日期。在接下來的部分中,我們將展示一些其他的字段類型,驗證和其他方法。
創建模型
使用mongoose.model()方法從綱要創建模型:
// Define schema
var Schema = mongoose.Schema;
var SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
// Compile model from schema
var SomeModel = mongoose.model("SomeModel", SomeModelSchema);
第一個參數,是將為模型創建的集合的單數名稱(Mongoose 將為上面的 SomeModel 模型,創建數據庫集合),第二個參數,是你要在創建模型時使用的綱要 Shema。
備註:定義模型類後,可以使用它們來創建,更新或刪除記錄,並運行查詢,以獲取記錄的所有記錄,或特定子集。我們將在以下「使用模型」部分,向你展示如何執行上述操作,以及當創建視圖時,如何執行此操作。
綱要型態(字段)
綱要 schema 可以有任意數量的字段 — 每個字段代表存儲在 MongoDB 文檔中的字段。如下的示例綱要,顯示許多常見字段類型及其聲明方式。
var schema = new Schema({
name: String,
binary: Buffer,
living: Boolean,
updated: { type: Date, default: Date.now },
age: { type: Number, min: 18, max: 65, required: true },
mixed: Schema.Types.Mixed,
_someId: Schema.Types.ObjectId,
array: [],
ofString: [String], // You can also have an array of each of the other types too.
nested: { stuff: { type: String, lowercase: true, trim: true } },
});
大多數綱要型態SchemaTypes(「type:」之後或字段名稱之後的描述符)都是自解釋的。例外情況是:
ObjectId:表示數據庫中模型的特定實例。例如,一本書可能會使用它來表示其作者對象。這實際上將包含指定對象的唯一 ID (_id) 。我們可以使用populate()方法,在需要時提取相關訊息。- Mixed :任意綱要型態。
- []:一個數組的項目。你可以在這些模型上執行 JavaScript 數組操作(push、pop、unshift 等)。上面的例子,顯示了一個沒有指定類型的對像數組,和一個 String 對像數組,但是你可以有任何類型的對像數組。
該代碼還顯示了聲明一個字段的兩種方式:
- 字段名稱和類型作為鍵值對(即是,像上面的
name,binaryandliving)。 - 字段名稱後跟一個定義類型
type的對象,以及該字段的任何其他選項。選項包括如下內容:- 默認值。
- 內置驗證器(例如最大/最小值)和自定義驗證功能。
- 該字段是否為必要
- 是否應將字符串
String字段自動設置為小寫,大寫或修剪(例如){ type:String, lowercase: true, trim: true }
有關選項的更多訊息,請參閱SchemaTypes(Mongoose docs)。
驗證
Mongoose 提供內置和自定義驗證器,以及同步和異步驗證器。它允許你在所有情況下,指定可接受的範圍或值,以及驗證失敗的錯誤消息。
內置的驗證器包括:
下面的示例(從 Mongoose 文檔稍微修改)顯示瞭如何指定一些驗證器類型和錯誤消息:
var breakfastSchema = new Schema({
eggs: {
type: Number,
min: [6, 'Too few eggs'],
max: 12
required: [true, 'Why no eggs?']
},
drink: {
type: String,
enum: ['Coffee', 'Tea', 'Water',]
}
});
有關字段驗證的完整訊息,請參閱驗證(Mongoose docs)。
虛擬屬性
虛擬屬性是你可以獲取和設置的文檔屬性,但不會持久保存到 MongoDB。getter 對格式化或組合字段非常有用,而 setter 可用於將單個值分解為多個值,以進行存儲。
文檔中的示例,從名字和姓氏字段構造(並解構)一個全名虛擬屬性,這比每次在模板中使用全名更簡單,更清晰。
備註:我們將使用庫中的虛擬屬性,來為每個使用路徑和記錄的_id值的模型記錄,定義唯一的 URL。
欲了解更多訊息,請參閱虛擬(Mongoose 文檔)。
方法和查詢幫助
綱要 schema 也可以有實例方法,靜態方法和查詢助手。實例和靜態方法很相似,但有明顯的區別,即實例方法與特定記錄相關聯,並且可以訪問當前對象。查詢助手允許你擴展 mongoose 的鍊式查詢構建器 API(例如,除了find(), findOne()和findById()方法外,還允許你添加一個「byName」查詢。
使用模型
一旦創建了綱要,就可以使用它來創建模型。該模型代表數據庫中可以搜索的文檔集合,而模型的實例代表你可以保存和檢索的單個文檔。
我們在下面簡要介紹一下。有關更多訊息,請參閱:模型(Mongoose docs)。
創建和修改文檔
要創建記錄,你可以定義模型的實例,然後調用save()。下面的例子假設,SomeModel 是我們從綱要創建的模型(帶有單一字段「name」 )。
// Create an instance of model SomeModel
var awesome_instance = new SomeModel({ name: "awesome" });
// Save the new model instance, passing a callback
awesome_instance.save(function (err) {
if (err) return handleError(err);
// saved!
});
創建記錄(以及更新,刪除和查詢)是異步操作— 你提供在操作完成時調用的回調。API 使用錯誤優先參數約定,因此回調的第一個參數將始終為錯誤值(或 null)。如果 API 返回一些結果,則將作為第二個參數提供。
你還可以使用create(),同時定義模型實例,並保存模型實例。回調將為第一個參數返回錯誤,為第二個參數返回新創建的模型實例。
SomeModel.create({ name: "also_awesome" }, function (err, awesome_instance) {
if (err) return handleError(err);
// saved!
});
每個模型都有一個關聯的連接(當你使用mongoose.model()時,這將成為默認連接)。你創建一個新連接並調用.model(),以在另一個數據庫上創建文檔。
你可以使用點語法訪問此新記錄中的字段,並更改值。你必須調用save()或update(),將修改的值存回數據庫。
// Access model field values using dot notation
console.log(awesome_instance.name); //should log 'also_awesome'
// Change record by modifying the fields, then calling save().
awesome_instance.name = "New cool name";
awesome_instance.save(function (err) {
if (err) return handleError(err); // saved!
});
尋找紀錄
可以使用查詢方法搜索記錄,將查詢條件指定為 JSON 文檔。下面的代碼片段,顯示瞭如何在數據庫中,找到所有參加網球運動的運動員,只返回運動員姓名和年齡的字段。這裡我們只指定一個匹配的字段(運動 sport),但你可以添加更多條件,指定正則表達式標準,或完全刪除條件以返回所有運動員。
var Athlete = mongoose.model("Athlete", yourSchema);
// find all athletes who play tennis, selecting the 'name' and 'age' fields
Athlete.find({ sport: "Tennis" }, "name age", function (err, athletes) {
if (err) return handleError(err);
// 'athletes' contains the list of athletes that match the criteria.
});
如果你指定回調,如上所示,查詢將立即執行。搜索完成後將調用回調。
備註:Mongoose 中的所有回調,都使用此回調模式callback(error, result)。如果執行查詢時發生錯誤,錯誤參數error將包含錯誤文檔,並且結果result將為 null。如果查詢成功,則error參數將為 null,並且結果result 將被填充到查詢結果。
如果你未指定回調,則 API 將返回Query類型的變量。你可以使用此查詢對象來構建查詢,然後稍後使用exec()方法執行(使用回調)。
// find all athletes that play tennis
var query = Athlete.find({ sport: "Tennis" });
// selecting the 'name' and 'age' fields
query.select("name age");
// limit our results to 5 items
query.limit(5);
// sort by age
query.sort({ age: -1 });
// execute the query at a later time
query.exec(function (err, athletes) {
if (err) return handleError(err);
// athletes contains an ordered list of 5 athletes who play Tennis
});
上面我們在find()方法中,定義了查詢條件。我們也可以使用where()函數來執行此操作,並且我們可以使用點運算符( . )將查詢的所有部分鏈接在一起,而不是分別添加它們。
下面的代碼片段,與我們上面的查詢相同,並有年齡的附加條件。
Athlete.
find().
where('sport').equals('Tennis').
where('age').gt(17).lt(50). //Additional where query
limit(5).
sort({ age: -1 }).
select('name age').
exec(callback); // where callback is the name of our callback function.
find() 方法獲取所有匹配的記錄,但通常你只想獲得一個匹配。以下方法可以查詢單個記錄:
findById():用指定的id查找文檔(每個文檔都有一個唯一的id)。findOne(): 查找與指定條件匹配的單個文檔。findByIdAndRemove(),findByIdAndUpdate(),findOneAndRemove(),findOneAndUpdate():通過id或條件查找單個文檔,並更新或刪除它。這些是用於更新和刪除記錄的有用便利功能。
備註:還有一個count()方法,你可以使用它來獲取與條件匹配的項目數。如果你想要在不實際提取記錄的情況下執行計數,這非常有用。
查詢可以做更多的事情。有關更多訊息,請參閱:查詢(Mongoose 文檔)。
運用相關文檔— population 方法
你可以使用ObjectId綱要字段,從一個文檔/模型實例,創建一對一引用,或者使用ObjectIds數組,從一個文檔創建一對多的引用。該字段存儲相關模型的 ID。如果需要關聯文檔的實際內容,可以在查詢中使用populate()方法,將 id 替換為實際數據。
例如,以下綱要定義作者和故事。每個作者可以有多個故事,我們將其表示為一個ObjectId數組。每個故事可以有一個作者。綱要從「ref」(以粗體突出顯示)得知,可以分配給該字段的模型。
var mongoose = require("mongoose"),
Schema = mongoose.Schema;
var authorSchema = Schema({
name: String,
stories: [{ type: Schema.Types.ObjectId, ref: "Story" }],
});
var storySchema = Schema({
author: { type: Schema.Types.ObjectId, ref: "Author" },
title: String,
});
var Story = mongoose.model("Story", storySchema);
var Author = mongoose.model("Author", authorSchema);
我們可以通過分配_id值,來保存對相關文檔的引用。下面我們創建一個作者,然後創建一個故事,並將作者 ID 分配給我們的故事作者字段。
var bob = new Author({ name: "Bob Smith" });
bob.save(function (err) {
if (err) return handleError(err);
//Bob now exists, so lets create a story
var story = new Story({
title: "Bob goes sledding",
author: bob._id, // assign the _id from the our author Bob. This ID is created by default!
});
story.save(function (err) {
if (err) return handleError(err);
// Bob now has his story
});
});
我們的故事文檔,現在有作者文檔 ID 引用的作者。為了在我們的故事結果中,獲取作者訊息,我們使用populate(),如下所示。
Story.findOne({ title: "Bob goes sledding" })
.populate("author") //This populates the author id with actual author information!
.exec(function (err, story) {
if (err) return handleError(err);
console.log("The author is %s", story.author.name);
// prints "The author is Bob Smith"
});
備註:敏銳的讀者會注意到,我們在故事中添加了作者,但我們沒有做任何事情,來將我們的故事添加到作者的故事stories數組中。那麼我們怎樣才能得到特定作者的所有故事?
一種方法,是將作者添加到故事數組中,但這會導致我們需要在兩個地方,維護與作者和故事有關的訊息。更好的方法是獲取作者的_id,然後使用find(),在所有故事的作者字段中搜索此內容。
Story.find({ author: bob._id }).exec(function (err, stories) {
if (err) return handleError(err);
// returns all stories that have Bob's id as their author.
});
這幾乎是你在本教程中,使用相關項目時,需要了解的所有內容。有關更多詳細訊息,請參閱Population(Mongoose docs)。
一個檔案對應一個綱要/模型
雖然你可以使用任何喜歡的文件結構創建綱要和模型,但我們強烈建議在每個模型模塊(文件)中,定義每個模型綱要,導出方法以創建模型。如下所示:
// File: ./models/somemodel.js
//Require Mongoose
var mongoose = require("mongoose");
//Define a schema
var Schema = mongoose.Schema;
var SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
//Export function to create "SomeModel" model class
module.exports = mongoose.model("SomeModel", SomeModelSchema);
然後,你可以在其他文件中,立即要求並使用該模型。下面我們展示如何使用它,來獲取模型的所有實例。
//Create a SomeModel model just by requiring the module
var SomeModel = require("../models/somemodel");
// Use the SomeModel object (model) to find all SomeModel records
SomeModel.find(callback_function);
架設 MongoDB 數據庫
現在我們了解了 Mongoose 能做什麼,以及我們想如何設計我們的模型,現在該開始在 LocalLibrary 網站上工作了。我們想要做的第一件事,就是設置一個 MongoDb 數據庫,我們可以使用它來儲存我們的圖書館數據。
本教程,我們將使用mLab免費的雲託管的「 沙盒 」數據庫。這個數據庫層不適合生產環境的網站,因為它沒有冗餘設計,但它對於開發和原型設計來說非常有用。我們在這裡使用它,是因為它免費且易於設置,並且因為作為數據庫服務供應商來說,mLab 是流行的數據庫選擇之一,你可能會合理選擇你的生產環境數據庫(撰寫本文時,其他流行的選擇包括Compose、ScaleGrid和MongoDB Atlas)。
備註:如果你願意,可以下載並安裝與系統相對應的二進製文件,在本地設置 MongoDb 數據庫。除了你在連接時指定的數據庫 URL 之外,本文中的其餘指令將很類似。
你首先需要使用 mLab 創建一個賬戶(這是免費的,只需要輸入基本聯繫訊息,並確認其服務條款)。
登錄後,你將進入mLab 主畫面:
-
單擊 MongoDB Deployments 部分中的 Create New。
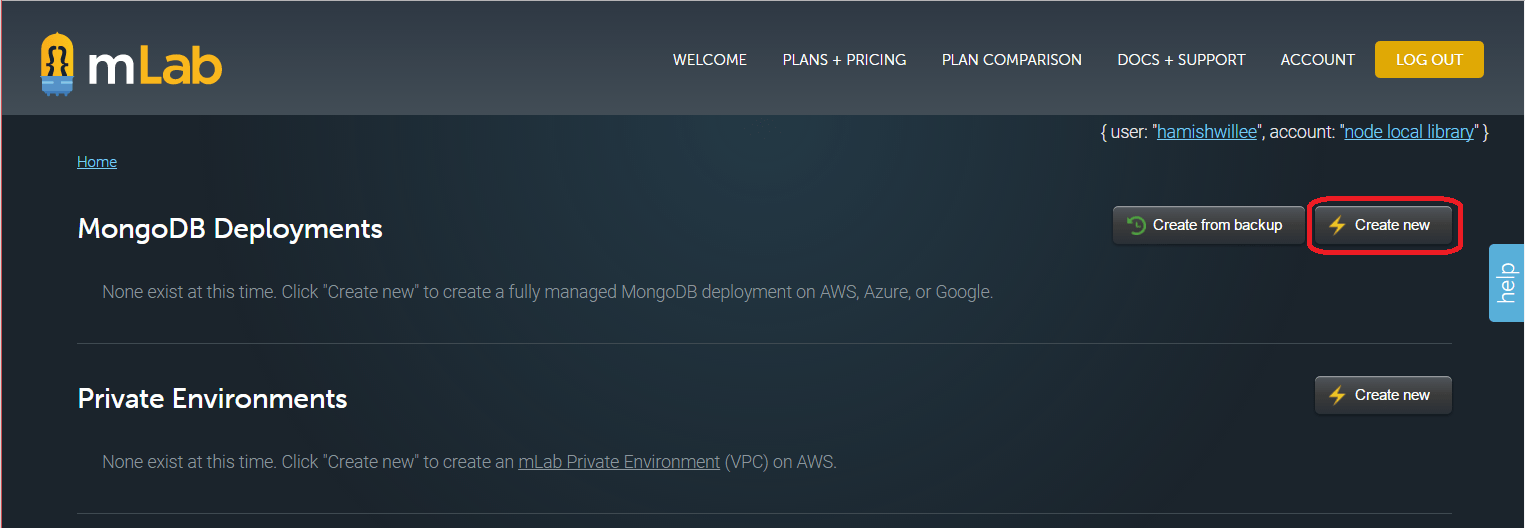
-
這將打開「雲提供商」Cloud Provider 選擇畫面。

- 從「計劃類型」Plan Type 部分中,選擇「SANDBOX(免費)」計劃。
- 從「雲提供商」Cloud Provider 部分,選擇任意提供商。不同的提供商,提供不同的地區(顯示在選定的計劃類型下面)。
- 單擊「繼續」Continue 按鈕。
-
這將打開「選擇區域」Select Region 畫面。

- 選擇離你最近的地區,然後選擇繼續 Continue。
-
這將打開 Final Details 畫面。

- 輸入新數據庫的名稱
local_library,然後選擇繼續 Continue。
- 輸入新數據庫的名稱
-
這將打開訂單確認畫面。

- 單擊「提交訂單」Submit Order 以創建數據庫。
-
你將返回到主畫面。單擊剛剛創建的新數據庫,以打開其詳細訊息畫面。正如你所看到的,數據庫沒有集合(數據)。
 你需要用來訪問數據庫的 URL,顯示在上面的表單中(如上圖所示)。為了使用它,你需要創建一個可以在 URL 中指定的數據庫用戶。
你需要用來訪問數據庫的 URL,顯示在上面的表單中(如上圖所示)。為了使用它,你需要創建一個可以在 URL 中指定的數據庫用戶。 -
單擊用戶Users選項卡,並選擇添加數據庫用戶按鈕Add database user。
-
輸入用戶名和密碼(兩次),然後按創建Create。不要選擇只讀read-only。

你現在已經創建了數據庫,並且有一個可以用來訪問它的 URL(帶有用戶名和密碼)。這看起來像是這樣的:mongodb://your_user_namer:your_password@ds119748.mlab.com:19748/local_library.
安裝 Mongoose
打開命令提示符,並到你創建本地圖書館骨架網站的目錄。輸入以下命令,安裝 Mongoose(及其依賴項),並將其添加到你的package.json文件中,除非你在閱讀上述Mongoose 入門時,已經這樣做了。
npm install mongoose
連接到 MongoDB
打開**/app.js**(位於項目的根目錄),並在宣告 Express 應用程序對象的位置(在var app = express();之後)複製以下文本。將數據庫 url 字符串('insert_your_database_url_here')替換為表示你自己的數據庫的位置 URL(即是使用來自上面 mLab的訊息)。
//Set up mongoose connection
var mongoose = require("mongoose");
var mongoDB = "insert_your_database_url_here";
mongoose.connect(mongoDB);
mongoose.Promise = global.Promise;
var db = mongoose.connection;
db.on("error", console.error.bind(console, "MongoDB connection error:"));
正如上面的Mongoose 入門中所討論的,此代碼創建了與數據庫的默認連接,並綁定到錯誤事件(以便將錯誤打印到控制台)。
定義本地圖書館綱要
如上所述,我們將為每個模型定義一個單獨的模塊。首先在項目根目錄(/models)中,為我們的模型創建一個文件夾,然後為每個模型創建單獨的文件:
/express-locallibrary-tutorial //the project root
/models
author.js
book.js
bookinstance.js
genre.js
作者模型
複製下面顯示的Author作者綱要代碼,並將其粘貼到**./models/author.js**文件中。該綱要定義了一個作者,具有StringSchemaTypes 的第一個名稱和家族名稱,這是必需的,最多有 100 個字符,Date字段為出生和死亡日期。
var mongoose = require("mongoose");
var Schema = mongoose.Schema;
var AuthorSchema = new Schema({
first_name: { type: String, required: true, max: 100 },
family_name: { type: String, required: true, max: 100 },
date_of_birth: { type: Date },
date_of_death: { type: Date },
});
// Virtual for author's full name
AuthorSchema.virtual("name").get(function () {
return this.family_name + ", " + this.first_name;
});
// Virtual for author's URL
AuthorSchema.virtual("url").get(function () {
return "/catalog/author/" + this._id;
});
//Export model
module.exports = mongoose.model("Author", AuthorSchema);
我們還為 AuthorSchema,聲明了一個名為「url」的虛擬屬性,它返回獲取模型的特定實例所需的絕對 URL — 每當我們需要獲取指向特定作者的鏈接時,我們將在模板中使用該屬性。
備註:在綱要中聲明我們的 URL 是虛擬的,這是一個好主意,因為一個項目的 URL 只需要在一個地方更改。此時,使用此 URL 的鏈接將不起作用,因為我們還沒有任何路由,可以處理個別模型實例的代碼。我們將在後面的文章中介紹這些內容!
在模塊的最後,我們導出了模型。
書本模型
複製下面顯示的Book綱要代碼,並將其粘貼到**./models/book.js**文件中。其中大部分與作者模型相似—我們已經聲明了一個具有多個字符串字段的綱要,以及一個虛擬屬性,用於獲取特定書籍記錄的 URL,並且我們已經導出了模型。
var mongoose = require("mongoose");
var Schema = mongoose.Schema;
var BookSchema = new Schema({
title: { type: String, required: true },
author: { type: Schema.Types.ObjectId, ref: "Author", required: true },
summary: { type: String, required: true },
isbn: { type: String, required: true },
genre: [{ type: Schema.Types.ObjectId, ref: "Genre" }],
});
// Virtual for book's URL
BookSchema.virtual("url").get(function () {
return "/catalog/book/" + this._id;
});
//Export model
module.exports = mongoose.model("Book", BookSchema);
這裡的主要區別,是我們已經創建了兩個對其他模型的引用:
- 作者是對單個
Author作者模型對象的引用,並且是必要的。 - 種類是對
Genre種類模型對像數組的引用。我們還沒有宣告這個對象!
書本實例模型
最後,複製下面顯示的BookInstance綱要代碼,並將其粘貼到**./models/bookinstance.js**文件中。BookInstance表示某人可能藉閱的書籍的特定副本,並包含有關該副本是否可用,或預期返回日期的訊息,「印記」或版本詳細訊息。
var mongoose = require("mongoose");
var Schema = mongoose.Schema;
var BookInstanceSchema = new Schema({
book: { type: Schema.Types.ObjectId, ref: "Book", required: true }, //reference to the associated book
imprint: { type: String, required: true },
status: {
type: String,
required: true,
enum: ["Available", "Maintenance", "Loaned", "Reserved"],
default: "Maintenance",
},
due_back: { type: Date, default: Date.now },
});
// Virtual for bookinstance's URL
BookInstanceSchema.virtual("url").get(function () {
return "/catalog/bookinstance/" + this._id;
});
//Export model
module.exports = mongoose.model("BookInstance", BookInstanceSchema);
我們在這裡展示的新東西,是字段選項:
- 枚舉
enum:這允許我們設置字符串的允許值。在這種情況下,我們用它來指定我們書籍的可用性狀態(使用枚舉,意味著我們可以防止錯誤拼寫和任意值,成為我們的狀態) - 默認值
default:我們使用默認值,將新創 建的書本實例的默認狀態,設置為維護,並將默認的due_back日期,設置為現在now(請注意在設置日期時,如何調用 Date 函數!)
其他所有內容,大夥應該在前面教程裡邊已經熟悉了。
種類模型-自我挑戰!
打開你的**./models/genre.js**文件,並創建一個存儲類型的綱要(書本的類別,例如它是小說還是非小說,浪漫史或軍事歷史等)。
該定義將與其他模型非常相似:
- 該模型應該有一個名為
name的StringSchemaType ,來描述種類。 - 這個
name字段應該是必要的,並且有 3 到 100 個字符。 - 為類型的 URL 聲明虛擬,名為
url。 - 導出模型。
測試—創建一些項目
就是這樣。我們現在已經為該網站建立了所有模型!
為了測試這些模型(並創建一些示例書籍,和其他項目以便於我們在後面文章使用),現在我們將運行一個獨立的腳本來創建每種類型的項目:
-
在 express-locallibrary-tutorial 目錄下(與
package.json處於同一級別),下載(或以其他方式創建)文件populatedb.js。備註:你不需要知道populatedb.js的工作原理;它只是將示例數據添加到數據庫中。
-
在項目根目錄中,輸入以下命令,以安裝腳本所需的異步模塊(我們將在後面的教程中討論這一點)
bashnpm install async -
在命令提示符下,使用 node 運行此腳本,傳遞 MongoDB 數據庫的 URL(與之前在
app.js中替換 insert_your_database_url_here 佔位符的那個相同):bashnode populatedb <your mongodb url> -
該腳本應一路運行至完成,並在終端中創建它們時顯示各項目。
備註:至mLab上的數據庫。你現在應該可以深入到書本籍,作者,種類和書本實例的各個集合中,並查看單個文檔。
總結
本文中我們學到了一點數據庫和 Node/Express 的 ORMs,更多的是關於如何定義 Mongoose 綱要與模型。然後我們使用這些知識,為本地圖書館網站設計並實作出書本Book,書本實例BookInstance,作者Author和種類Genre模型。
最後,我們創建一些實例,以測試模型(使用獨立運作的命令稿)。下一篇文章,我們將關注於如何創建一些網頁,以呈現這些物件。
參見
- Database integration (Express docs)
- Mongoose website (Mongoose docs)
- Mongoose Guide (Mongoose docs)
- Validation (Mongoose docs)
- Schema Types (Mongoose docs)
- Models (Mongoose docs)
- Queries (Mongoose docs)
- Population (Mongoose docs)