Debugging HTML
Escrever HTML é legal, mas e se algo der errado, e você não conseguir descobrir onde está o erro no código? Este artigo apresentará algumas ferramentas que podem ajudá-lo a encontrar e corrigir erros no HTML.
| Pré-requisitos: | Familiaridade com HTML, conforme abordado, por exemplo, em Introdução ao HTML, Fundamentos de texto em HTML e Criação de Hiperlinks. |
|---|---|
| Objetivo: | Aprender o básico sobre o uso de ferramentas de depuração (debugging) para encontrar problemas em HTML. |
Depurar não é assustador
Ao escrever algum tipo de código, tudo costuma ir bem, até o temido momento quando ocorre um erro — você fez algo errado, então seu código não funciona - talvez não funcione mais nada ou não funciona exatamente como você queria. Por exemplo, a seguir é mostrado um erro relatado ao tentar Compile um programa simples escrito na linguagem Rust.
 Aqui, a mensagem de erro é relativamente fácil de entender — "string de aspas duplas sem terminação". Se você olhar a listagem, provavelmente verá como
Aqui, a mensagem de erro é relativamente fácil de entender — "string de aspas duplas sem terminação". Se você olhar a listagem, provavelmente verá como println!(Hello, world!"); pode estar faltando logicamente uma aspa dupla. No entanto, as mensagens de erro podem ficar mais complicadas e menos fáceis de interpretar à medida que os programas se tornam maiores, e até mesmo casos simples podem parecer um pouco intimidadores para alguém que não sabe nada sobre o Rust.
Depurar um código não tem que ser assustador, porém — a chave para se sentir confortável em escrever e depurar qualquer linguagem ou código de programação é a familiaridade com a linguagem e as ferramentas.
HTML e depuração
HTML não é tão complicado de entender quanto o Rust. O HTML não é compilado em um formato diferente antes do navegador analisá-lo e mostrar o resultado (ele é interpretado, não compilado). E a sintaxe do Element HTML é muito mais fácil de entender do que uma "linguagem de programação real" como Rust, JavaScript, ou Python. A forma como os navegadores analisam o HTML é muito mais permissiva do que a forma como as linguagens de programação são executadas, o que é bom e ruim.
Código permissivo
Então, o que queremos dizer com permissivo? Bem, geralmente quando você faz algo errado no código, existem dois tipos principais de erros que você encontrará:
- Erros de sintaxe: São os erros de ortografia no seu código que realmente fazem com que o programa não seja executado, como o erro do Rust mostrado acima. Estes geralmente são fáceis de corrigir, desde que você esteja familiarizado com a sintaxe (forma de escrever) da linguagem e saiba o que significam as mensagens de erro.
- Erros lógicos: São erros onde a sintaxe está correta, mas o código não é o que você pretendia, o que significa que o programa é executado incorretamente. Geralmente, eles são mais difíceis de corrigir do que erros de sintaxe, pois não há uma mensagem de erro para direcioná-lo para a origem deste erro.
O próprio HTML não sofre de erros de sintaxe porque os navegadores o analisam permissivamente, o que significa que a página ainda é exibida mesmo se houver erros de sintaxe. Os navegadores têm regras internas para indicar como interpretar a marcação escrita incorretamente, para que você obtenha algo em execução, mesmo que não seja o esperado. Isso, claro, ainda pode ser um problema!
Nota: O HTML é analisado permissivamente porque, quando a web foi criada, foi decidido que permitir que as pessoas publicassem seus conteúdos era mais importante do que garantir que a sintaxe estivesse absolutamente correta. A web provavelmente não seria tão popular quanto é hoje, se tivesse sido mais rigorosa desde o início.
Aprendizado Ativo: Estudando código permissivo
É hora de estudar a natureza permissiva do código HTML.
-
Primeiramente, faça o download do debug-example demo e o salve localmente. Esse exemplo contém erros propositais para que possamos explorá-los (tal código HTML é dito badly-formed, em contraponto ao HTML well-formed).
-
Em seguida, abra o arquivo em um navegador. Você verá algo como:

-
Isso claramente não parece bom; vamos dar uma olhada no código fonte para tentar achar os erros (somente o conteúdo de body é mostrado):
html<h1>Exemplo de debugação HTML</h1> <p>O quê causa erros em HTML? <ul> <li>Elementos não fechados: Se um elemento não for <strong>fechado corretamente, pode se espalhar e afetar áreas que você não imaginava <li>Elementos desagrupados: Agrupar elementos corretamente é importante para o comportamento do código. <strong>negrito <em>negrito sublinhado?</strong> O que é isso?</em> <li>Atributos não fechados: Outra fonte comum de problemas HTML. Vamos dar uma olhada: <a href="https://www.mozilla.org/>Link para página da Mozilla</a> </ul> -
Vamos analisar os erros:
- Os elementos parágrafo e item da lista não possuem tags de fechamento. Olhando a imagem acima, isso não parece ter afetado muito a renderização do HTML já que é fácil deduzir onde um elemento deveria terminar e outro, começar.
- O primeiro elemento
<strong>não possui tag de fechamento. Isto é um pouco mais problemático porque não é necessariamente fácil determinar onde um elemento deveria terminar. Assim, todo o resto do texto foi fortemente enfatizado. - Essa seção foi aninhada incorretamente:
<strong>negrito <em>negrito sublinhado?</strong> O que é isso?</em>. Não é fácil dizer como esse trecho foi interpretado por causa do problema anterior. - O valor do atributo
hrefnão tem as aspas de fechamento. Isso parece ter causado o maior problema — o link não foi renderizado.
-
Agora vamos dar uma olhada no HTML que o navegador renderizou, comparando-o com o nosso código fonte. Para fazer isso, usaremos as ferramentas de desenvolvimento oferecidas pelo navegador. Se você não está familiarizado com estas ferramentas, dê uma olhadinha nesse tutorial: O que são as ferramentas de desenvolvimento do navegador.
-
No inspetor DOM, você pode ver como o HTML renderizado fica:

-
Utilizando o inspetor DOM, vamos explorar nosso código detalhadamente para ver como o navegador tentou consertar os erros do código HTML (nós fizemos a análise com o Firefox, mas outros navegadores modernos devem apresentar o mesmo resultado):
-
As tags de fechamento foram colocadas nos parágrafos e itens da lista.
-
Não está claro onde o primeiro elemento
<strong>deveria terminar, portanto o navegador envolveu cada bloco subsequente em uma tag strong própria até o fim do documento! -
O aninhamento incorreto foi corrigido pelo navegador da seguinte maneira:
html<strong >strong <em>strong emphasised?</em> </strong> <em> what is this?</em> -
O link cujas aspas de fechamento não estavam presentes foi totalmente excluído da renderização. Então o último item ficou assim:
html<li> <strong >Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
-
Validação HTML
Então, você pode ver pelo exemplo acima que você realmente quer ter certeza de que o seu HTML foi bem construido! Mas Como? Em um pequeno exemplo como o que foi visto acima, é facil analisar as linhas e achar os erros, mas e se fosse um gigante e complexo documento HTML?
A melhor estratégia é começar rodando a sua página HTML através do Markup Validation Service — criado e mantido pelo W3C, uma organização que cuida das especificações que define o HTML, CSS, e outras tecnologias WEB. Esta página considera um documento HTML como uma entrada, fazendo a leitura dela e retornando o que há de errado com o seu HTML.

Para especificar o HTML a ser validado, você pode dar um endereço web, fazer o upload de um arquivo HTML, ou diretamente inserir o código HTML.
Aprendizado Ativo: Validando um documento HTML
Vamos tentar fazer isto com o nosso sample document.
- Primero, carregue o Markup Validation Service em uma aba no seu navegador, caso já não esteja carregada.
- Troque para a aba Validate by Direct Input.
- Copie todo o código do documento de exemplo (não apenas o body) e cole dentro da grande área de texto mostrada no Markup Validation Service.
- Pressione o botão Check.
Você deverá receber uma lista de erros e outras informações.
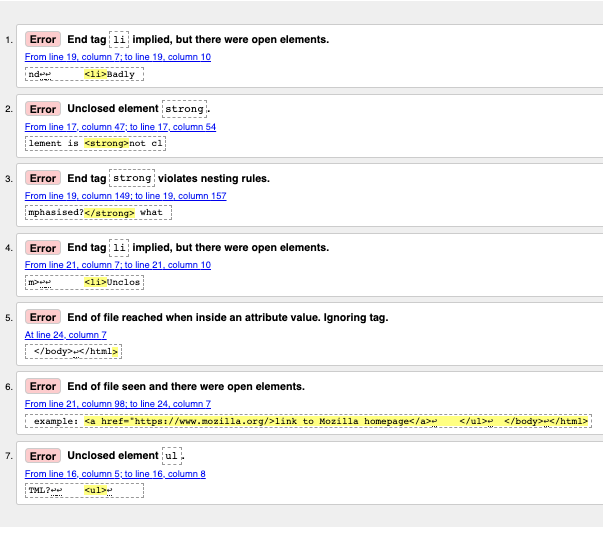
Interpretando as mensagens de erros
As mensagens de erros geralmente são úteis, mas algumas vezes elas não ajudam tanto; com um pouco de prática você pode descobrir como interpretar-lás para arrumar o seu código. Vamos dar uma olhada nas mensagens de erros e ver o que elas significam. Você verá que cada mensagem vem com um número para a linha e um para a coluna afim de ajudar você a localizar o erro facilmente.
-
"End tag
liimplied, but there were open elements" (2 instances): Estas mensagens indicam que um elemento que esta aberto deveria estar fechado. O final da tag esta implicito, mas não esta realmente lá. A informação de linha/coluna indica para a primeira linha depois de onde a tag de fechamento realmente deveria estar, mas isto é uma pista boa o suficiente para ver o que há de errado. -
"Unclosed element
strong": Este é muito fácil de entender — um<strong>elemento esta aberto, e uma informação de linha/coluna indica diretamente para onde esta. -
"End tag
strongviolates nesting rules": Este aponta os elementos incorretamente aninhados, e a informação de linha/coluna aponta onde o erro está. -
"End of file reached when inside an attribute value. Ignoring tag": Essa é mais enigmática; se refere ao fato de que há um valor do atributo formado indevidamente em algum lugar, possivelmente próximo ao fim do arquivo porquê o fim do arquivo aparece dentro do valor do atributo. O fato de o navegador não renderizar o link deveria nos dar uma boa pista de qual elemento está em falta.
-
"End of file seen and there were open elements": Essa é um pouco ambígua, mas basicamente se refere ao fato de que há elementos em aberto que devem ser fechados devidamente. A linha de números aponta para as últimas linhas do arquivo, e esta mensagem de erro vem com uma linha do código que aponta um exemplo de um elemento em aberto:
Exemplo: <a href="https://www.mozilla.org/>link para página da Mozilla</a> ↩ </ul>↩ </body>↩</html>
Nota: Um atributo faltando uma aspas pode resultar em um elemento aberto porque o resto do documento é interpretado como conteúdo do atributo.
-
"Unclosed element
ul": Esta não ajuda em nada, já que o elemento<ul>está fechado corretamente. Este erro aparece porque o elemento<a>não foi fechado, devido a falta de aspas de fechamento.
Se você não descobrir o significado de todas mensagens de erro, não se preocupe — uma boa ideia é tentar resolver alguns erros por vez. Então tente revalidar seu HTML para ver o que restou. Às vezes resolver erros anteriores pode te livrar de outras mensagens de erro — vários erros podem ser causados na maioria das vezes por um só, tipo um efeito dominó.
Você vai saber quando todos os seus erros forem resolvidos quando ver a seguinte bandeira no output:

Sumário
Então é isso, uma introdução a debugação de HTML, na qual deve te dar dicas úteis quando você começar a debugar CSS, JavaScript, e outros tipos de códigos mais tarde na sua carreira. Isso também significa o fim dos artigos de aprendizado do Módulo de Introdução ao HTML — agora você pode testar a si mesmo com nossa avaliação: a primeira está no link abaixo.