Qu'est-ce qu'une URL ?
Cet article aborde les Uniform Resource Locators (URL) (qu'on peut traduire en français par « localisateurs uniformes de ressources »), et explique leur rôle et leur structure.
| Prérequis : | Comprendre le fonctionnement général d'Internet, ce qu'est un serveur web, et les concepts derrière les liens sur le Web. |
|---|---|
| Objectifs : | Apprendre ce qu'est une URL et comprendre son fonctionnement sur le Web. |
Résumé
Une URL (Uniform Resource Locator) correspond à l'adresse d'une ressource unique sur Internet. Il s'agit d'un des mécanismes principaux utilisés par les navigateurs pour récupérer des informations publiées, telles que des pages HTML, des documents CSS, des images, etc.
En théorie, chaque URL valide pointe vers une ressource unique. En pratique, il existe certaines exceptions, notamment quand une URL pointe vers une ressource qui n'existe plus ou qui a été déplacée. Comme une ressource représentée par une URL et l'URL même sont gérées par le serveur web, c'est au gestionnaire du serveur web de gérer correctement la ressource et l'URL correspondante.
Fondamentaux : anatomie d'une URL
Voici quelques exemples d'URL :
https://developer.mozilla.org https://developer.mozilla.org/fr/docs/Learn/ https://developer.mozilla.org/fr/search?q=URL
Chacune de ces URL peut être saisie dans la barre d'adresse d'un navigateur pour lui indiquer de charger la ressource associée. Dans ces trois exemples, il s'agit d'une page web.
Une URL se compose de différentes parties, certaines sont obligatoires tandis que d'autres sont optionnelles. Les parties les plus importantes sont mises en évidence dans l'illustration suivante et les sections ci-après décrivent en détails ces composantes :

Note : On peut voir une analogie entre une URL et une adresse postale classique : le schéma s'apparente le type de service postal à utiliser, le nom de domaine s'apparente la ville, le port s'apparente le code postal, et le chemin le bâtiment où on souhaite envoyer le courrier. Les paramètres représentent des informations complémentaires, comme le numéro d'appartement dans le bâtiment. Enfin, l'ancre s'apparente à la personne à laquelle le courrier s'adresse.
Note : Il existe d'autres règles et composantes pour les URL, mais qui ne concernent pas le Web. Ne vous en souciez pas pour le moment, vous n'en aurez pas besoin pour savoir comment construire et utiliser des URL fonctionnelles.
Schéma

Le schéma est la première partie d'une URL et indique le protocole que le navigateur doit utiliser afin de demander la ressource (un protocole est un ensemble de méthodes pour échanger ou transférer des données au sein d'un réseau d'ordinateurs. Pour les sites web, on utilise généralement le protocole HTTPS ou HTTP (une version non sécurisée). Pour accéder à une page web, il faut utiliser l'un de ces protocoles. Toutefois, les navigateurs gèrent également d'autres schémas comme mailto: (pour ouvrir un client de courrier électronique), ne soyez donc pas surpris de croiser d'autres protocoles.
Autorité

Ensuite, on trouve l'autorité, séparée du schéma par les caractères ://. Si elle est présente, l'autorité inclut le domaine (par exemple www.example.com) et le port (80), séparés par un double-point :
- Le domaine indique le serveur web auquel s'adresse la requête. Il s'agit généralement d'un nom de domaine, mais on peut aussi trouver une adresse IP (ce qui est plus rare, car moins pratique).
- Le port indique la « porte » technique utilisée pour accéder aux ressources sur le serveur web. Cette information est généralement omise si le serveur web utilise les ports standard du protocole HTTP (80 pour HTTP, et 443 pour HTTPS) pour permettre l'accès aux ressources. Si le port utilisé n'est pas standard, il doit nécessairement être précisé.
Note :
Le séparateur entre le schéma et l'autorité est ://. Le double-point sépare le schéma de la partie suivante de l'URL, tandis que // indique que ce qui suit est l'autorité.
Voici un exemple d'URL qui n'utilise pas d'autorité : mailto:tototruc@example.com pour le courrier électronique. Elle contient un schéma, mais pas d'autorité. Aussi, les deux-points ne sont pas suivis de deux barres obliques et servent uniquement de délimiteur entre le schéma et l'adresse électronique.
Le chemin vers la ressource

/chemin/vers/le/fichier.html est le chemin de la ressource vers le serveur web. Aux débuts du Web, un tel chemin correspondait généralement à l'emplacement physique du fichier sur le serveur web. De nos jours, il s'agit plutôt d'une abstraction gérée par les serveurs web et qui ne correspond pas nécessairement à un emplacement physique sur le système de fichiers du serveur.
Les paramètres
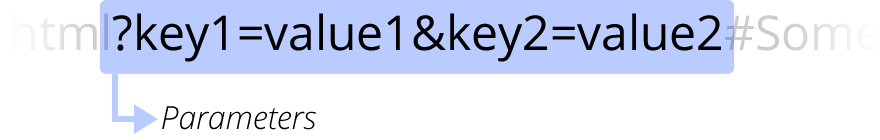
?clef1=valeur1&clef2=valeur2 sont des paramètres supplémentaires fournis au serveur web. Ces paramètres prennent la forme d'une liste de paires de clef/valeur, chacune séparée par une esperluette (&). Le serveur web peut utiliser ces paramètres pour effectuer des traitements supplémentaires avant de renvoyer la ressource. Chaque serveur web applique ses propres règles pour la gestion des paramètres, et la seule façon fiable de déterminer si un serveur web donné gère des paramètres consiste à demander au propriétaire du serveur.
L'ancre

#QuelquePartDansLeDocument est une ancre vers un emplacement au sein de la ressource. Une ancre représente en quelque sorte un marque-page au sein de la ressource, et qui indique au navigateur d'afficher le contenu de la ressource situé au niveau de ce marque-page. Pour un document HTML, par exemple, le navigateur fera défiler le document jusqu'à l'ancre. Pour un document vidéo ou audio, le navigateur tentera d'aller au moment précisé par l'ancre. Il faut noter que la partie située après le croisillon #, également appelée identificateur de fragment, n'est jamais envoyée au serveur avec la requête.
Comment utiliser les URL
N'importe quelle URL peut être saisie dans la barre d'adresse du navigateur pour récupérer la ressource correspondante, mais ce n'est que la partie visible de l'iceberg !
Le langage HTML que nous aborderons plus tard utilise énormément les URL :
- Pour créer des liens vers d'autres documents grâce aux éléments
<a>; - Pour rattacher un document aux ressources qui lui sont liées, par exemple grâce aux éléments
<link>ou<script>; - Pour afficher des médias comme des images (avec l'élément
<img>), des vidéos (grâce à l'élément<video>), des sons et de la musique (avec l'élément<audio>), etc. ; - Pour afficher d'autres documents HTML à l'aide de l'élément
<iframe>.
Note :
Lorsqu'on fournit une URL pour charger des ressources au sein d'une page (par exemple en utilisant les éléments <script>, <audio>, <img>, <video> ou autre), on utilise généralement uniquement des URL HTTP et HTTPS, sauf exception (notamment pour les URL de données qui utilisent le protocole data:). Ainsi, le protocole FTP, par exemple, n'est pas sécurisé et n'est plus pris en charge par les navigateurs récents.
D'autres technologies comme CSS ou JavaScript utilisent également fréquemment les URL et constituent les briques de base du Web.
URL absolues et URL relatives
L'exemple que nous avons étudié plus haut est une URL absolue. Il existe également des URL relatives. Le standard qui spécifie les URL définit les deux types en utilisant respectivement les termes chaîne de caractères d'URL absolue et chaîne de caractères d'URL relative, pour les distinguer des objets URL (qui correspondent à la représentation en mémoire des URL).
Voyons la distinction entre absolue et relative dans le contexte des URL.
Les composantes obligatoires d'une URL dépendent grandement du contexte dans lequel l'URL est utilisée. Dans la barre d'adresse du navigateur, une URL n'a pas de contexte particulier et il faut fournir une URL complète, une URL absolue, comme celle que nous avons vu précédemment. Il n'est pas strictement nécessaire d'inclure le protocole (le navigateur utilisera HTTP par défaut) ou le port (uniquement nécessaire si le serveur web cible utilise un port inhabituel), mais toutes les autres parties de l'URL sont nécessaires.
Lorsqu'on utilise une URL au sein d'un document, comme dans une page HTML, la situation est différente. En effet, le navigateur dispose déjà de l'URL du document et peut utiliser cette information pour déduire les parties manquantes des URL utilisées dans le document. On peut distinguer une URL absolue d'une URL relative en examinant le chemin. Si le chemin de l'URL commence par une barre oblique (/), le navigateur récupèrera la ressource à la racine du serveur, sans faire référence au contexte fourni par le document courant.
Prenons quelques exemples pour illustrer cela. Dans ces exemples, nous considèrerons que les URL sont écrites dans un document lui-même situé à l'URL : https://developer.mozilla.org/fr/docs/Learn_web_development.
https://developer.mozilla.org/fr/docs/Learn_web_development est une URL absolue. Elle contient toutes les composantes nécessaires à la localisation de la ressource.
Toutes les URL suivantes sont des URL relatives :
- URL relative par rapport au schéma :
//developer.mozilla.org/fr/docs/Learn_web_development -
Ici, seul le protocole manque. Le navigateur utilisera alors le même protocole que celui utilisé pour charger le document contenant cette URL.
- URL relative par rapport au domaine :
/fr/docs/Learn_web_development -
Le protocole et le nom de domaine sont manquants. Le navigateur utiliser le même protocole et le même nom de domaine que ceux utilisés pour charger le document contenant cette URL.
- Sous-ressources :
Howto/Web_mechanics/What_is_a_URL -
Le protocole et le nom de domaine sont manquants, et le chemin ne commence pas par
/. Le navigateur tentera de trouver le document dans un sous-répertoire de celui contenant la ressource courante. Dans ce cas, cette URL relative correspond à l'URL absoluehttps://developer.mozilla.org/fr/docs/Learn_web_development/Howto/Web_mechanics/What_is_a_URL. - Remonter dans l'arborescence :
../CSS/display -
Le protocole et le nom de domaine sont manquants, et le chemin commence par
... Cette écriture suit celle du monde des systèmes de fichier UNIX qui indique de remonter d'un niveau dans l'arborescence. L'URL absolue correspondant à cet exemple esthttps://developer.mozilla.org/fr/docs/Learn_web_development/../CSS/display, qu'on peut simplifier enhttps://developer.mozilla.org/fr/docs/CSS/display. - Ancre uniquement :
#url_sémantiques -
Toutes les composantes sont absentes exceptée l'ancre. Le navigateur utilisera l'URL du document courant et remplacera ou ajoutera l'ancre à celle-ci. Cela s'avère utile quand on veut faire pointer un lien vers une partie spécifique du document courant.
URL sémantiques
Malgré leur aspect technique, les URL représentent des points d'entrées censées être compréhensibles par les humains. On peut les mémoriser, et les saisir manuellement dans la barre d'adresse du navigateur. Le Web est au service des personnes, et c'est une bonne pratique que de construire ce qu'on appelle des URL sémantiques. Les URL sémantiques utilisent des mots clairs, pouvant être compris par chacune ou chacun, quel que soit son niveau de connaissance technique.
Les ordinateurs et serveurs se fichent bien des sémantiques linguistiques et vous avez sûrement déjà vu des URL qui ressemblent à du charabia de caractères. Toutefois, il y a de nombreux avantages à créer des URL compréhensibles par les humains :
- Il est plus facile de les manipuler.
- Cela clarifie les choses pour les utilisatrices et utilisateurs pour comprendre leur situation et leurs actions sur le Web.
- Certains moteurs de recherche peuvent utiliser cette sémantique afin d'améliorer la classification des pages correspondantes.
Voir aussi
Les URL de données sont des URL préfixées par le schéma data: qui permettent d'embarquer de petits fichiers à même le document.