Déboguer de l'HTML
Écrire du code HTML, c'est bien, mais si quelque chose se passe mal, que faire pour trouver où est l'erreur dans le code ? Cet article vous indique divers outils pour vous aider à trouver et corriger les erreurs en HTML.
| Prérequis : | Connaissances de base en HTML, comme abordé dans Syntaxe HTML de base. Sémantique au niveau du texte comme les titres et paragraphes et les listes. HTML structurel. |
|---|---|
| Objectifs d'apprentissage : |
|
Déboguer n'est pas un problème
Quand on écrit du code , tout va généralement bien, jusqu'au moment redouté où une erreur se produit — vous avez fait quelque chose d'incorrect, donc votre code ne fonctionne pas — soit pas du tout, soit pas tout à fait comme vous l'aviez souhaité. Par exemple, ce qui suit montre une erreur signalée lors d'une tentative de compilation d'un programme simple écrit en Rust (angl.).

Ici, le message d'erreur est relativement facile à comprendre — « unterminated double quote string » : il manque un guillemet double ouvrant ou fermant pour envelopper la chaîne de caractères. Si vous regardez le listage, vous pouvez voir println!(Salut, Ô Monde!"); il manque un guillemet double. Cependant, des messages d'erreur peuvent devenir plus complexes et plus abscons au fur et à mesure que le programme grossit et, même dans des cas simples devenir intimidants à quelqu'un qui ne connaît rien du Rust.
Déboguer ne doit toutefois pas devenir un problème — la clé pour être à l'aise lors de l'écriture et du débogage d'un programme réside dans une bonne connaissance à la fois du langage et des outils.
HTML et le débogage
HTML n'est pas aussi compliqué à comprendre que le Rust. HTML n'est pas compilé sous une forme différente avant que le navigateur n'ait fait son analyse et affiche le résultat (il est interprété, pas compilé). Et la syntaxe des éléments HTML est sans doute beaucoup plus facile à comprendre qu'un « vrai langage de programmation » tel le Rust, le JavaScript ou le Python.
La façon dont les navigateurs analysent le HTML est beaucoup plus permissive que celle des langages de programmation, ce qui est à la fois une bonne et une mauvaise chose.
Que voulons‑nous dire par permissif ? Et bien, quand vous faites une erreur dans du code, vous allez rencontrer deux types principaux d'erreurs :
- Erreurs de syntaxe : ce sont des « fautes d'orthographe » dans le code qui font que le programme ne fonctionne vraiment pas, comme l'erreur du Rust ci‑dessus. Elles sont généralement faciles à corriger pour autant que vous soyez à l'aise avec la syntaxe du langage et que vous sachiez ce que signifie le message d'erreur.
- Erreurs de logique : ce sont des erreurs dans lesquelles la syntaxe est réellement correcte, mais pour lesquelles le code ne correspond pas à vos souhaits, ce qui veut dire que le programme ne s'exécute pas correctement. Elles sont généralement plus difficiles à corriger que les erreurs de syntaxe, car il n'y a pas de message d'erreur pour vous guider à la source de l'erreur.
Le HTML lui-même ne souffre pas d'erreurs de syntaxe, car les navigateurs l'analysent de manière permissive, ce qui signifie que la page s'affiche même s'il y a des erreurs de syntaxe dans le code source. Les navigateurs possèdent des règles intégrées pour indiquer comment interpréter un balisage HTML mal écrit (souvent appelé balisage invalide ou mal formé), le transformant automatiquement en un balisage valide.
Par exemple, l'extrait HTML suivant contient des éléments mal imbriqués :
<p>
Je ne m'attendais pas à trouver le <em>chat du voisin
<strong>d'à côté</em></strong> ici !
</p>
La balise de fermeture </strong> doit se trouver avant la balise de fermeture </em>, mais ce n'est pas le cas — elle est placée après.
Si vous chargez ce HTML dans un navigateur puis regardez le rendu DOM, vous allez voir que l'imbrication a été corrigée par le navigateur :
<p>
Je ne m'attendais pas à trouver le
<em>chat du voisin <strong>d'à côté</strong></em> ici !
</p>
Alors pourquoi est-ce à la fois une bonne et une mauvaise chose ? Eh bien, dans ce cas, le navigateur a produit le résultat attendu, mais comme vous allez le voir plus loin, ce n'est pas toujours le cas. Vous allez toujours obtenir quelque chose qui fonctionne, mais le navigateur ne fait pas toujours ce qu'il faut, ce qui peut causer des problèmes. Il vaut mieux écrire un balisage correct dès le départ.
Note : HTML est analysé de façon permissive parce que, lorsque le Web a été créé pour la première fois, on a décidé qu'il était plus important de permettre aux gens de publier leur contenu que de s'assurer d'une syntaxe absolument correcte. Le web n'est probablement pas aussi populaire qu'il l'est aujourd'hui, s'il avait été plus strict dans ses débuts.
Alors, comment trouver les erreurs de balisage ? Plus loin, nous vous montrons comment trouver des erreurs dans le HTML à l'aide d'un outil appelé le validateur HTML, mais d'abord nous vous montrons comment inspecter manuellement votre HTML à l'aide d'un inspecteur DOM, puis nous explorons les types d'erreurs de balisage que vous pouvez rechercher, et comment le navigateur peut les interpréter.
Utiliser l'inspecteur DOM
Tous les navigateurs modernes disposent d'un ensemble d'outils de développement (devtools) intégrés, qui fournissent des fonctionnalités pour examiner la page web chargée dans l'onglet courant. Ceux-ci peuvent vous montrer quel HTML est rendu dans la page, quel CSS est appliqué à chaque nœud du DOM, quel JavaScript s'exécute dans la page, et plus encore. Ils vous permettent également de modifier le code en cours d'exécution et d'en voir l'effet en direct sur la page.
Vous pouvez ouvrir les outils de développement de façon similaire dans chaque navigateur — consultez Comment ouvrir les outils de développement dans votre navigateur pour savoir comment faire.
Pour cet article, la seule fonctionnalité pertinente des outils de développement est l'inspecteur DOM, qui affiche le DOM HTML actuellement rendu et vous permet de le modifier. Voyons cela maintenant :
- Ouvrez les outils de développement dans votre navigateur.
- Ouvrez l'inspecteur DOM. Il se trouve au même endroit dans chaque navigateur — le premier onglet des outils de développement, au début de la rangée. Dans Firefox, il est intitulé Inspecteur, tandis que dans Safari, Edge et Chrome, il est intitulé Éléments. Il s'agit généralement de l'onglet sélectionné par défaut lorsque vous ouvrez les outils de développement, mais sélectionnez-le si ce n'est pas le cas.
- Examinez la structure de l'arbre DOM affichée dans l'onglet, et notez que vous pouvez cliquer sur les petites flèches d'expansion au début de chaque nœud DOM pour les développer et les réduire, et révéler leurs nœuds descendants. Vous pouvez également utiliser les touches fléchées haut et bas pour monter et descendre dans les nœuds, et les touches fléchées droite et gauche pour développer et réduire les nœuds.
- Essayez également de survoler les nœuds (ou de les sélectionner avec les touches fléchées) et notez comment l'élément actuellement survolé (ou sélectionné) est mis en surbrillance dans la zone d'affichage.
- Vous pouvez aussi modifier le DOM rendu. Nous n'utilisons pas la fonctionnalité d'édition dans cet article, mais prenez le temps de chercher comment faire si cela vous intéresse.
À votre tour : Étudier le HTML avec l'inspecteur DOM
Voici le moment venu d'étudier le caractère permissif du code HTML.
-
Tout d'abord, enregistrez le fichier HTML suivant sous le nom
debug-example.html, quelque part sur votre machine locale. Cette démonstration est délibérément écrite avec quelques erreurs intégrées pour que nous puissions les explorer.html<!doctype html> <html lang="fr"> <head> <meta charset="utf-8"> <title>Exemple de HTML à déboguer</title> </head> <body> <h1>Exemple de HTML à déboguer</h1> <p>Quelles sont les causes d'erreur en HTML ? <ul> <li>>Éléments non fermés : si un élément n'est <strong>pas fermé proprement, ses effets peuvent déborder sur des zones que vous ne souhaitiez pas. <li>Éléments incorrectement imbriqués : imbriquer des éléments proprement est également très important pour que le code se comporte correctement. <strong>caractères gras <em>ou gras et italiques ?</strong> qu'est‑ce ?</em> <li>Attributs non fermés : autre source courante de problèmes en HTML. Voici un exemple: <a href="https://www.mozilla.org"> lien à la page d'accueil de Mozilla</a> </ul> </body> </html> -
Ensuite, ouvrez‑le dans un navigateur. Vous pouvez voir quelque chose comme ceci :

-
Constatons que ce n'est pas terrible ; examinons le code source pour voir ce que nous pouvons en faire (seul le contenu de l'élément
bodyest affiché) :html<h1>Exemple de HTML à déboguer</h1> <p>Quelles sont les causes d'erreur en HTML ? <ul> <li>Éléments non fermés : si un élément n'est <strong>pas fermé proprement, ses effets peuvent déborder sur des zones que vous ne souhaitiez pas. <li>Éléments incorrectement imbriqués : imbriquer des éléments proprement est également très important pour que le code se comporte correctement. <strong>caractères gras <em>ou gras et italiques ?</strong> qu'est‑ce ?</em> <li>Attributs non fermés : autre source courante de problèmes en HTML. Voici un exemple: <a href="https://www.mozilla.org"> lien à la page d'accueil de Mozilla</a> </ul> -
Revoyons les problèmes :
- Les élements de paragraphes et d'éléments de liste n'ont pas de balise de fermeture. En voyant l'image ci‑dessus, cela ne semble pas avoir trop sévèrement affecté le rendu, car on voit bien où un élément se termine et où le suivant commence.
- Le premier élément
<strong>n'a pas de balise de fermeture. C'est un peu plus problématique, car il n'est pas possible de dire où l'élément est supposé se terminer. En fait, tout le reste du texte est en gras. - Cette partie est mal imbriquée :
<strong>caractères gras <em>ou gras et italiques ?</strong> qu'est ce ?</em>. Pas facile de dire comment il faut interpréter cela en raison du problème précédent. - La valeur de l'attribut
hrefn'a pas de guillemet double fermant. C'est ce qui semble avoir posé le plus gros problème — le lien n'a pas été mentionné du tout.
-
Revoyons maintenant comment le navigateur a vu le balisage, par comparaison au balisage du code source. Pour ce faire, utilisons les outils de développement du navigateur. Dans « l'Inspecteur », vous pouvez voir ce à quoi le balisage du rendu ressemble :

-
Regardez comment le navigateur a tenté de corriger nos erreurs HTML (nous avons fait la revue dans Firefox ; les autres navigateurs modernes devraient donner le même résultat) :
-
Les paragraphes et les éléments de liste ont été pourvus de balises fermantes.
-
L'endroit où le premier élément
<strong>doit être fermé n'est pas clair, donc le navigateur a enveloppé séparément chaque bloc de texte avec ses propres balisesstrong, jusqu'à la fin du document ! -
L'imbrication incorrecte a été corrigée ainsi :
html<strong> caractères gras <em>ou caractères gras et italiques ?</em> </strong> <em> qu'est ce ?</em> -
Le lien avec les guillemets manquants a été illico détruit. Le dernier élément
liressemble à ceci :html<li> <strong> Attributs non fermés : autre source courante de problèmes en HTML. Voici un exemple : </strong> </li>
-
Validation d'un HTML
Vous pouvez voir d'après l'exemple ci-dessus qu'il est vraiment important de s'assurer que votre HTML est bien formé ! Mais comment faire ? Dans un petit exemple comme celui vu ci-dessus, il est facile de parcourir les lignes et de trouver les erreurs, mais qu'en est-il d'un document HTML énorme et complexe ?
L'outil adapté à cette tâche est le Markup Validation Service (angl.) (ou validateur HTML), qui est créé et maintenu par le W3C (dont vous avez entendu parler dans Le modèle des standards du web). Le validateur prend un document HTML en entrée, le parcourt et vous fournit un rapport pour vous indiquer ce qui ne va pas dans votre HTML.

Pour indiquer le HTML à valider, vous pouvez fournir une adresse web, téléverser un fichier HTML ou saisir directement du code HTML.
Valider un document HTML
Dans cette tâche, nous allons vous faire essayer le validateur HTML. Vous allez valider notre document d'exemple (angl.) et voir quels résultats sont retournés. Cet exemple contient le même HTML que vous avez étudié précédemment avec l'inspecteur DOM.
- D'abord, chargez le Markup Validation Service (angl.) dans un nouvel onglet du navigateur, si ce n'est pas déjà fait.
- Passez à l'onglet Validate by Direct Input (angl.).
- Copiez tout le code du document d'exemple (pas seulement le
body) et collez-le dans la grande zone de texte affichée dans le Markup Validation Service. - Appuyez sur le bouton Check.
Cela doit vous donner une liste d'erreurs et d'autres informations.
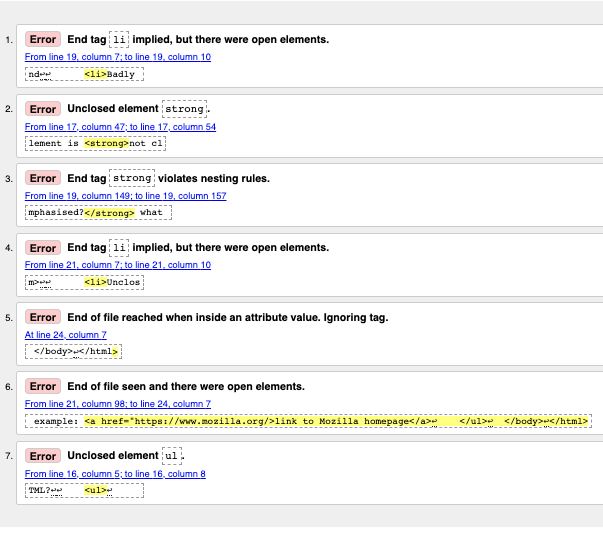
Interprétation des messages d'erreur
Les messages d'erreur sont généralement utiles, mais parfois non ; avec un peu de pratique, vous pouvez trouver comment les interpréter pour corriger votre code. Passons en revue les messages d'erreur et voyons leur signification. Chaque message est accompagné d'un numéro de ligne et de colonne pour faciliter la localisation de l'erreur.
-
« End tag
liimplied, but there were open elements » (2 instances) : ces messages indiquent qu'un élément ouvert doit être fermé. La balise de fermeture est implicite, mais pas réellement mise. L'information ligne/colonne pointe sur la première ligne après laquelle la balise de fermeture doit réellement se situer, mais c'est un bon indice pour voir ce qui ne va pas. -
« Unclosed element
strong» : C'est facile à comprendre — un élément<strong>n'est pas fermé ; l'information ligne/colonne pointe directement dessus. -
« End tag
strongviolates nesting rules » : signale des éléments incorrectement imbriqués et l'information ligne/colonne signale là où cela se trouve. -
« End of file reached when inside an attribute value. Ignoring tag » : c'est peu clair ; la remarque se rapporte au fait qu'il y a une valeur d'attribut improprement formée quelque part, peut-être près de la fin du fichier, car la fin du fichier apparaît dans la valeur de l'attribut. Le fait que le navigateur ne rende pas le lien est un bon indice pour dire que cet élément est en faute.
-
« End of file seen and there were open elements » : c'est un peu ambigu, mais se réfère au fait qu'à la base des éléments ouverts n'ont pas été proprement fermés. Les numéros de ligne pointent sur les dernières lignes du fichier et ce message d'erreur vient avec une ligne de code qui désigne un exemple d'élément ouvert :
exemple : <a href="https://www.mozilla.org/>lien à la page d'accueil de Mozilla</a> ↩ </ul>↩ </body>↩</html>
Note : Un attribut sans guillemet fermant peut entraîner un élément ouvert, car le reste du document est interprété comme le contenu de l'attribut.
-
« Unclosed element
ul» : n'est pas vraiment utile, car l'élément<ul>est correctement fermé. Cette erreur ressort, car l'élément<a>n'est pas fermé en raison de l'absence de guillemet fermant.
Si vous ne comprenez pas ce que signifie chaque message d'erreur, ne vous inquiétez pas — une bonne idée consiste à corriger quelques erreurs à la fois. Puis essayez de revalider le HTML pour voir les erreurs restantes. Parfois, la correction d'une erreur en amont permet aussi d'éliminer d'autres messages d'erreur — plusieurs erreurs sont souvent causées par un même problème, avec une sorte d'effet domino.
Vous savez que toutes vos erreurs sont corrigées lorsque vous voyez une petite bannière verte indiquant qu'il n'y a aucune erreur à signaler. Au moment de la rédaction, elle affichait « Vérification du document terminée. Aucune erreur ou avertissement à afficher. »
Résumé
Voilà, une introduction au débogage HTML, qui doit vous donner des compétences utiles sur lesquelles vous appuyer lors du débogage HTML, mais aussi du code CSS et JavaScript plus tard dans le cours. Cela marque également la fin du module Structurer le contenu avec HTML.
Votre prochaine étape consiste à commencer à apprendre à styliser le web dans notre module de mise en forme simple en CSS.