Отладка HTML
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
| Что нужно знать: | Базовые знания HTML на уровне Начало работы с HTML, Основы редактирования текста в HTML, и Создание гиперссылок. |
|---|---|
| Чему вы научитесь: | Искать проблемы в HTML с помощью инструментов отладки. |
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
 В данном случае, сообщение об ошибке понять относительно просто — "unterminated double quote string". Если вы внимательно посмотрите на
В данном случае, сообщение об ошибке понять относительно просто — "unterminated double quote string". Если вы внимательно посмотрите на println!(Hello, world!"); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. HTML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у "настоящих языков программирования", таких как Rust, JavaScript, или Python. Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
- Синтаксические ошибки (Syntax errors): Это ошибки в правильности написания, как это было выше, в примере с Rust. Такие обычно легко исправлять, в той мере, в какой вы знакомы с синтаксисом языка и знаете, что означают сообщения об ошибках.
- Логические ошибки (Logic errors): Это ошибки, появляющиеся в том случае, если синтаксис корректен, но код не выполняет своего предназначения, то есть программа выполняется неверно. Такие исправлять сложнее, чем синтаксические, поскольку не выводится сообщений, указывающих место, где вы ошиблись.
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: HTML разбирается браузером толерантно. Когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Активное обучение: Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
-
Для начала, скачайте наш пример отладки и сохраните локально. Эта демонстрация намеренно написана с ошибками, которые нам предстоит обнаружить.
-
Далее, откройте её в браузере. Вы увидите нечто вроде этого :

-
Сейчас документ выглядит не особо хорошо; Давайте посмотрим в код и выясним почему (Показано только тело документа):
html<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> -
Рассмотрим проблемы:
- У параграфа и элемента списка не закрыты теги. На изображении выше видно, что разметка не пострадала, так как браузеру легко сделать вывод о том, где заканчивается один элемент и начинается другой.
- Первый
<strong>элемент также не имеет закрывающего тега. Это уже более проблематично, так как сложно сказать, где элемент должен заканчиваться. На деле, весь оставшийся текст был выделен жирным. - Следующая часть нарушает правила вложенности:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. В этом случае код тоже сложно проинтерпретировать по причине, описанной выше. - В атрибуте
hrefотсутствует закрывающая двойная кавычка. Это послужило причиной крупной проблемы — ссылка не воспроизвелась вовсе.
-
Сейчас же посмотрим, как браузер сгенерировал собственную разметку, в противовес исходной разметке документа. Чтобы сделать это, воспользуемся инструментами разработчика. Если вы не знакомы с инструментами разработчика, потратьте несколько минут на Обзор инструментов разработки в браузерах.
-
В DOM инспекторе вы можете увидеть как сгенерировалась новая разметка:

-
Используя DOM инспектор, давайте рассмотрим детали нашего кода, чтобы увидеть, как браузер пытается исправить наши ошибки в HTML (мы обозреваем в Firefox; другой современный браузер должен выдать те же результаты):
-
Параграфы и элементы списка получены с закрывающими тегами.
-
Было неочевидно, где элемент
<strong>должен был закрыться, так что браузер обернул каждый отдельный блок текста своими собственными тегами strong, причём до самого низа документа! -
Некорректная вложенность была исправлена браузером следующим образом:
html<strong >strong <em>strong emphasised?</em> </strong> <em> what is this?</em> -
Ссылка с отсутствующими двойными кавычками была удалена насовсем. Последний элемент списка будет выглядеть так:
html<li> <strong >Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
-
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.

HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Активное обучение: Валидируем HTML-документ
Попробуем проверить документ-пример.
- Откройте сервис валидации разметки в браузере.
- Перейдите в режим Validate by Direct Input.
- Скопируйте весь код документа (не только body) и вставьте в место для ввода.
- Нажмите на Check (проверить).
Вы увидите список ошибок и другую информацию.
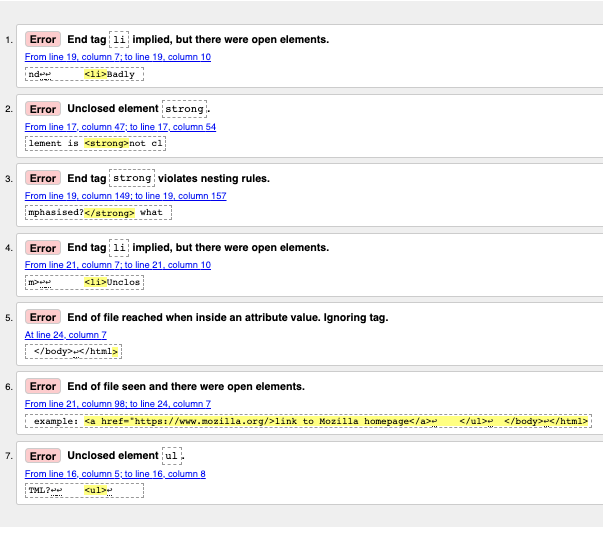
Работа с сообщениями об ошибках
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
-
"End tag
liimplied, but there were open elements" (2 instances): Нет явного закрывающего тега, хотя браузер догадывается, где он должен быть. Сообщение указывает на строку после той, на которой ожидался закрывающий тег, но вы найдёте нужное место. -
"Unclosed element
strong": Это очень простая ошибка — элемент<strong>не закрыт, и сообщение указывает прямо на открывающий тег. -
"End tag
strongviolates nesting rules": Элемент неправильно вложен — на этом уровне нет парного открывающего тега. -
"End of file reached when inside an attribute value. Ignoring tag": Загадочное сообщение. Дело в том, что где-то (скорее всего, в конце документа) неправильно прописано свойство элемента, и конец файла оказался внутри этого свойства. В браузере не видно ссылки — скорее всего, проблема рядом с ней.
-
"End of file seen and there were open elements": Файл закончился, но некоторые элементы не закрыты. Сообщение указывает на конец файла, в данном случае не закрыт элемент
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Примечание: Свойство без закрывающей кавычки может проглотить закрывающий тег — браузер считает его частью значения этого свойства.
-
"Unclosed element
ul": Странно, ведь элемент<ul>закрыт. Настоящая проблема всё там же — элемент<a>не закрыт из-за недостающей кавычки в свойстве.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:

Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.