URL とは何か
この記事では URL (Uniform Resource Locator) について説明し、その内容と構造を説明します。
| 前提知識: | インターネットはどのように動くのか、ウェブサーバーとは、ウェブ上のリンクの背後にある概念を知っておく必要があります。 |
|---|---|
| 目標: | URL とは何か、ウェブ上でどう働くのかについて学習します。 |
概要
URL (Uniform Resource Locator) とは、インターネット上の固有のリソースのアドレスのことです。これはブラウザーが HTML ページや CSS 文書、画像などの公開すべきリソースを取得するために用いる重要な仕組みの一つです。
理論的には、それぞれ有効な URL は一意のリソースを指しています。実際には一部例外もあります。最も一般的なものは、もはや存在しないリソースや移動したリソースを指す URL です。 URL で表されるリソースと URL 自体はウェブサーバーによって処理されるため、ウェブサーバーの所有者がそのリソースとその関連 URL を慎重に管理する必要があります。
基本: URL の解剖
URL の例を次に示します
https://developer.mozilla.org https://developer.mozilla.org/ja/docs/Learn_web_development/ https://developer.mozilla.org/ja/search?q=URL
これらの URL のいずれかをブラウザーのアドレスバーに入力することで、関連するリソースを読み込むように指示することができ、これら 3 つの場合はすべてウェブページです。
URL はさまざまな部分で構成されていますが、必須のものと任意のものもあります。次の URL を使用して最も重要な部分を見てみましょう(下記の節で詳細を提供しています)。

メモ: URL を通常の郵便の住所として考えることもできます。スキーム (scheme) は利用したい郵便サービス、ドメイン名 (domain name) は市町村、ポート番号 (port) は郵便番号のようなもの、パス (path) は郵便物を届けるべき建物、引数 (parameters) はその建物の部屋番号など追加情報、アンカー (anchor) は実際の宛先人物を表します。
メモ: URL に関してはいくつかの追加の部分と追加のルールがありますが、これらは普通のユーザーとウェブ開発者には関係ありません。気にしないでください。これを知る必要はありませんし、 URL のすべての機能を使用する必要もありません。
スキーム

URL の最初の部分はスキームで、ブラウザーがリソースをリクエストするために使用するプロトコルを示します(プロトコルとは、コンピューターネットワーク上でデータを交換または転送するための一連の手順です)。通常、ウェブサイトのプロトコルは、 HTTPS または HTTP (保護なしバージョン)です。しかし、ブラウザーは mailto: (メールクライアントを開く)のような他のスキームを処理する方法も知っているので、他のプロトコルを見かけても驚かないでください。
オーソリティ

次にオーソリティが続きます。これはスキームから :// の文字パターンで区切られます。オーソリティがある場合は、ドメイン(例えば www.example.com)とポート番号 (80) がコロン区切りで含まれます。
- ドメインは、どのウェブサーバーを要求しているのかを示します。通常はドメイン名ですが、 IP アドレスを使うこともあります(ただし、これは利便性に欠けるので稀です)。
- ポートは、ウェブサーバー上のリソースにアクセスするために使用される技術的な「門」 を示します。ウェブサーバーが HTTP プロトコルの標準ポート(HTTP は 80、 HTTPS は 443)を使用してリソースへのアクセスを許可している場合は、通常、この項目は省略されます。それ以外の場合は必須です。
メモ:
スキームとオーソリティの間の区切り文字は :// です。コロンはスキームと URL の次の部分を分離し、 // は URL の次の部分がオーソリティであることを示します。
オーソリティを使用しない URL の一例として、メールクライアント (mailto:foobar) があります。これはスキームを含んでいますが、オーソリティ部分を使用していません。したがって、コロンの後には 2 つのスラッシュがなく、スキームとメールアドレスの間の区切り文字としてのみ機能します。
リソースへのパス

/path/to/myfile.html は、ウェブサーバー上のリソースへのパスです。初期のウェブでは、このようなパスはウェブサーバー上の物理的なファイルの場所を表していました。今日ではほとんどの場合、物理的なものではなくウェブサーバーによって処理される抽象的なものです。
引数
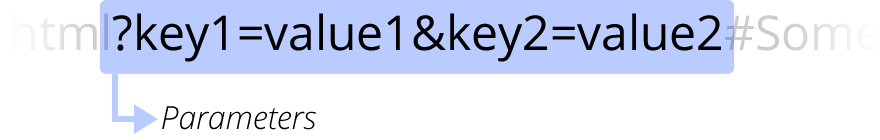
?key1=value1&key2=value2 は、ウェブサーバーに提供される追加の引数です。これらの引数は & 記号で区切られたキー/値の組のリストです。ウェブサーバーは、リソースを返す前にこれらの引数を使用して追加の処理を行うことができます。各ウェブサーバーには引数に関する独自のルールがありますので、特定のウェブサーバーが引数を処理するかどうかを確認する確実な方法は、ウェブサーバーの所有者に問い合わせることだけです。
アンカー

#SomewhereInTheDocument は、リソース自体の別の部分へのアンカーです。アンカーはリソース内の一種の「ブックマーク」を表し、ブラウザーにそのブックマークされた場所にあるコンテンツを表示するための指示を与えます。たとえば、 HTML 文書では、ブラウザーはアンカーが定義されている位置までスクロールします。ビデオやオーディオ文書では、ブラウザーはアンカーが表す時刻に移動しようとします。 # の後の部分はフラグメント識別子とも呼ばれ、リクエストとともにサーバーに送信されることはありません。
URL の使い方
ブラウザーのアドレスバーの中に正しく URL を入力すれば、それに対応するリソースを得ることができます。しかし、これは氷山の一角にすぎません。
HTML 言語では — 後述しますが — URL を幅広く使用しています。
<a>要素により、他の文書へのリンクを生成する<link>や<script>のような様々な要素を介して、文書を関連するリソースと結びつける- 画像(
<img>要素による)、動画(<video>要素による)、音声と音楽(<audio>要素による)などのメディアを表示する <iframe>要素により、他の HTML 文書を表示する
メモ:
URL を指定してページの一部としてリソースを読み込む際(<script>, <audio>, <img>, <video> を使用する場合など)は、 HTTP と HTTPS の URL のみを使用してください。いくつかの例外はあります(注目すべきは data: です。data URL を参照してください)。たとえば FTP を使用しても、安全になることはなく、多くのブラウザーでは対応していません。
CSS や JavaScript などの他の技術は、URL を広範囲に使用し、真にウェブの中核です。
絶対 URL と相対 URL
上記で見たものは絶対 URL と呼ばれていますが、相対 URL と呼ばれるものもあります。 URL 標準では両方が定義されています。 — ここでは絶対 URL 文字列および相対 URL 文字列という言葉が使われています。これは URL オブジェクト(URL のメモリー内の表現)と区別するためです。
URL のコンテキストで「絶対」と「相対」の意味の違いを確認してみましょう。
URL の必須部分は、その URL が使用されているコンテキストによって大きく異なります。ブラウザーのアドレスバーでは、 URL にはコンテキストがありません。そのため、上で見たように、完全(または絶対) URL を指定する必要があります。プロトコル(ブラウザーは既定で HTTP を使用します)やポート番号(対象となるウェブサーバーが通常以外のポートを使用している場合にのみ必要)を含める必要はありませんが、 URL の他の部分はすべて必要です。
HTML ページなどの文書内で URL が使用される場合、状況は少し異なります。ブラウザーはすでに文書自身の URL を持っているので、この情報を文書内で利用される URL の欠けている部分を補うために利用することができます。絶対 URL と相対 URL は、 URL のパスの部分を見るだけで区別することができます。 URL のパスの部分が / の文字で始まっていれば、ブラウザーは現在の文書で指定されているコンテキストを参照せずに、サーバーの最上位のルートからそのリソースを取得します。
これをより明確にするために、いくつかの例を見てみましょう。URL は、 https://developer.mozilla.org/ja/docs/Learn_web_development の URL にある文書内で定義されていると想定しましょう。
https://developer.mozilla.org/ja/docs/Learn_web_development 自体は絶対 URL です。この URL には、それが指すリソースを見つけるために必要なすべての部分が含まれています。
次の URL はすべて相対 URL です。
- スキーム相対 URL:
//developer.mozilla.org/ja/docs/Learn_web_development— プロトコルのみがありません。ブラウザーは、その URL をホスティングする文書を読み込む際に使用したプロトコルと同じプロトコルを使用します。 - ドメイン相対 URL:
/ja/docs/Learn_web_development— プロトコルとドメイン名の両方がありません。ブラウザーは、その URL をホスティングする文書を読み込むために使用されているものと同じプロトコルおよびドメイン名を使用します。 - サブリソース:
Howto/Web_mechanics/What_is_a_URL— プロトコルとドメイン名がなく、パスが/で始まっていません。ブラウザーは、現在のリソースを含むサブディレクトリ内で文書を探します。この場合、実際に到達したい URL はhttps://developer.mozilla.org/ja/docs/Learn_web_development/Howto/Web_mechanics/What_is_a_URLです。 - ディレクトリーツリーを戻る:
../CSS/display— プロトコルとドメイン名がなく、パスは..で始まっています。これは UNIX ファイルシステムの世界から継承されたもので、1 レベル上に移動することをブラウザーに指示します。ここでは、https://developer.mozilla.org/ja/docs/Learn_web_development/../Web/CSS/displayの URL に到達したいとしますが、これはhttps://developer.mozilla.org/ja/docs/Web/CSS/displayのように簡略化できます。 - アンカーのみ:
#semantic_urls- アンカー以外の部分がすべてありません。ブラウザーは、現在の文書の URL を使用し、アンカー部分を置き換えたり追加したりします。これは、現在の文書の特定の部分にリンクしたい場合に便利です。
URL のユーザー名とパスワード
上記で説明した URL の部分よりもあまり一般的ではありませんが、URL にユーザー名とパスワードが含まれている場合があります。
例を示します。
https://username:password@www.example.com:80/
含める場合、ユーザー名とパスワードは :// 文字で囲み、その間に権限を記載し、その間にコロン、最後にアットマーク (@) を付けます。
HTTP 認証セキュリティ機構を使用しているウェブサイトにアクセスする際に、ユーザー名とパスワードを URL に含めることができます。これにより、ウェブサイトに即座にログインし、資格情報を入力するためのユーザー名/パスワードダイアログボックスをバイパスすることができます。
このメカニズムは、まだ実際に使用されているものを見かけるかもしれませんが、セキュリティ上の観点から非推奨とされており、現行のウェブサイトでは、認証には他のメカニズムが使用される傾向があります。詳細については、URL 内の資格情報を使用してアクセスするをご覧ください。
セマンティック URL
URL はとても技術的な香りがするにもかかわらず、人間が読めるウェブサイトの入口を表します。覚えやすく、誰でもブラウザーのアドレスバーに入力することができます。人々はウェブの中核にいるので、セマンティック URL と呼ばれるものを構築することがベストプラクティスと考えられています。セマンティック URL は、技術的な知識に関係なく、誰でも理解できる固有の意味を持つ単語を使用します。
言語的セマンティックはもちろんコンピューターとは無関係です。おそらくランダムな文字を組み合わせたように見える URL を見たことがあるでしょう。しかし、人間が読める URL を作成することには多くの利点があります。
- より操作しやすくなります。
- ウェブ上のどこにいるのか、何をしているのか、何を読んでいるのか、何と対話しているかといった観点のことが、ユーザーにとって明確になります。
- 検索エンジンによっては、関連するページを分類するためにこれらのセマンティックを使用することがあります。
関連情報
data URL — data URL とは、 URL の前にdata:スキームを付けたもので、コンテンツ制作者が小さなファイルを文書内にインラインで埋め込むことを可能にします。