Conceitos da API Stream
A Streams API adiciona conjunto muito útil de ferramentas à plataforma web, provendo objetos que permitem ao JavaScript acessar via programação dados de stream recebidos pela rede e processá-los conforme desejado pelo desenvolvedor. Alguns conceitos e terminologias associadas a streams podem ser novos pra você - este artigo explicará tudo o que você precisa saber.
Readable streams
Um readable stream pode ser representado em JavaScript por um objeto ReadableStream que flui de uma underlying source - é um recurso em algum lugar na rede ou outro lugar no domínio do qual deseja obter dados..
Há dois tipos de fontes subjacentes:
- Push sources constatemente envia dados enquanto os acessa, e você decide quando iniciar, pausar ou cancelar o acesso ao stream. Exemplos deste tipo incluem stream de vídeo e sockets TCP/Web sockets.
- Pull sources requer que você requisite os dados explicitamente uma conectado. Exemplos deste tipo incluem operações de acesso a arquivos via chamada Fetch ou XHR.
O dado é lido sequencialmente em pequenos blocos de informação chamado chunks. Um chunk por ser um simples byte, ou, pode ser algo maior como um typed array de um certo tamanho.
Um simples stream pode conter chunks de diferentes tamanhos e tipos.
Os chunks alocados em um stream são ditos enqueued (enfileirados) — isto significa que eles estão aguardando em uma fila prontos para serem lidos. Uma internal queue rastreia os chunks que ainda não foram lidos (veja filas internas e estratégias de enfileiramento na sessão abaixo).
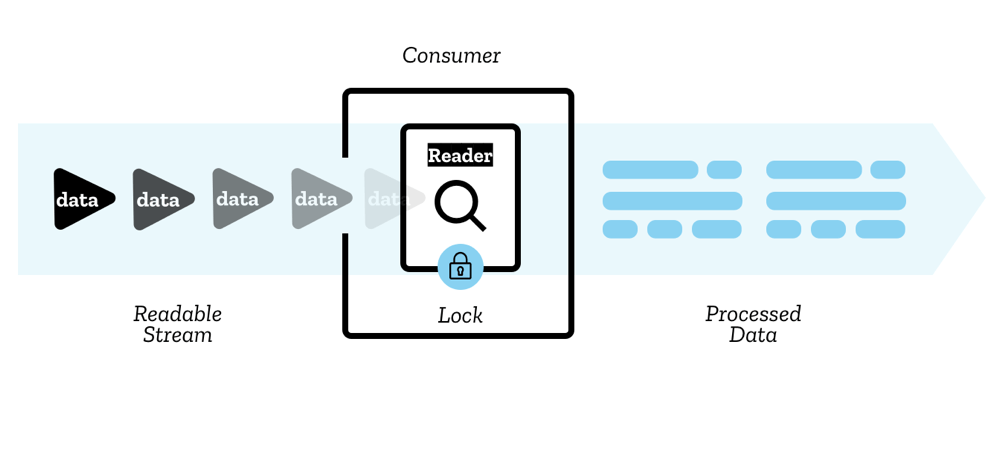
Os chunks dentro de um stream são lidos por um reader — este processa o dado de um chunk por vez, permitindo fazer qualquer tipo de operação que desejar .O reader com mais outro código de processamento junto é chamado consumer.
Há também uma construção que você usará chamada controller — cada reader tem um controller associado que lhe permite controlar o stream (por exemplo, cancelá-lo se desejar).
Apenas um reader pode ler um stream por vez; quando um reader é criado e inicia a leitura de um stream (um active reader), dizemos que ele está atrelado a ele. Se você deseja outro reader para iniciar a leitura de seu stream, você precisa tipicamente cancelar o primeiro reader antes de fazer qualquer coisa (embora você possa usar um stream tee, veja Teeing na sessão abaixo)
Observe que há dois tipos diferentes de readable streams. Assim como um readable stream convencional há um tipo chamado byte stream - este é uma versão extendida de um stream convencional para leitura de underlying byte sources (de outra forma conhecido como BYOB, ou "bring your own buffer"). Estes permitem que streams sejam lidos diretamente em um buffer fornecido pelo desenvolvedor, minimizando a cópia necessária. Tal underlying stream (e por extensão, reader e controller) seu código dependerá em primeiro lugar de como o stream foi criado (veja o ReadableStream.ReadableStream() construtor de página).
Aviso: Importante: Bytes streams não estão implementados ainda em algum lugar, e foram levantadas questões sobre se os detalhes de especificação estão em condições para serem implementados. Isto pode mudar com o tempo.
Você pode fazer uso dos stream readers já implementados via mecanismos como Response.body como uma requisição, ou com seus próprios streams usando o ReadableStream.ReadableStream() como construtor.
Teeing
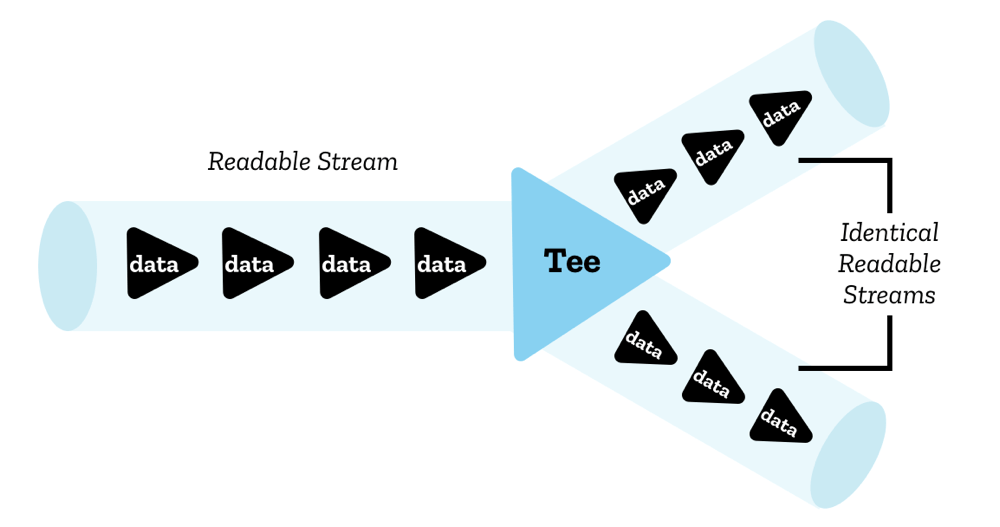
Embora um único reader possa ler um stream por vez, é possível dividir um stream em duas cópias idênticas, que podem então serem lidas por dois readers distintos. Isto é chamado teeing.
Em JavaScript, isto pode ser alcançado pelo método ReadableStream.tee() — ele retorna um array contendo duas cópias idêniticas o readable stream original, o qual pode então ser lido independentemente por dois readers separados.
Você deve fazê-lo por exemplo em um ServiceWorker se deseja pegar a resposta de um servidor e disponibilizar via stream no navegador, mas, também disponibilizá-lo via cache do ServiceWorker. Uma vez que o corpo da resposta não pode ser consumido mais que uma vez, e um stream não pode ser lido por mais de um reader por vez, você precisaria de duas cópias para fazer isto.
Writable streams
Um writable stream é o destino o qual você pode escrever dados, representado em JavaScript pelo objeto WritableStream. Ele serve como uma camada de abstração sobre um underlying sink — um I/O de baixo-nivel que sincroniza quais dados brutos são escritos.
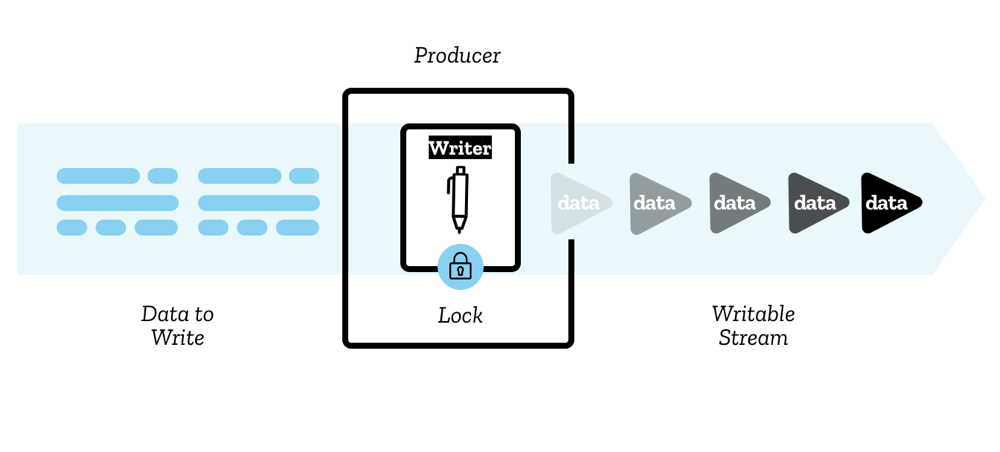
O dado é escrito para o stream via um writer, um chunk por vez. Um chunk pode ter uma infinidade de formas, assim como os chunk em um reader. Você pode usar qualquer código que desejar para produzir chunks prontos para escrever, mais o código associado ao producer.
Quando um writer é criado e inicia a escrita para um stream (um active writer), dizemos estar locked (atrelado) a este. Apenas um writer opde escrever em um writable stream por vez. Se deseja outro writer iniciar a escrita em seu stream, você deve tipicamente abortá-lo antes de anexar outro write à ele.
Uma internal queue mantém os chunks que foram escritos por um stream mas não foram ainda processados por underlying sink.
Há uma construção que você usará chamada controller — cada writer tem um controller associado que permite a você controlar o stream (por exemplo, abortá-lo se desejado).
Você pode fazer uso de writable streams usando o construtor
You can make use of writable streams using the WritableStream.WritableStream(). Estes atualmente possuem uma disponibilidade limitada nos navegadores.
Pipe chains
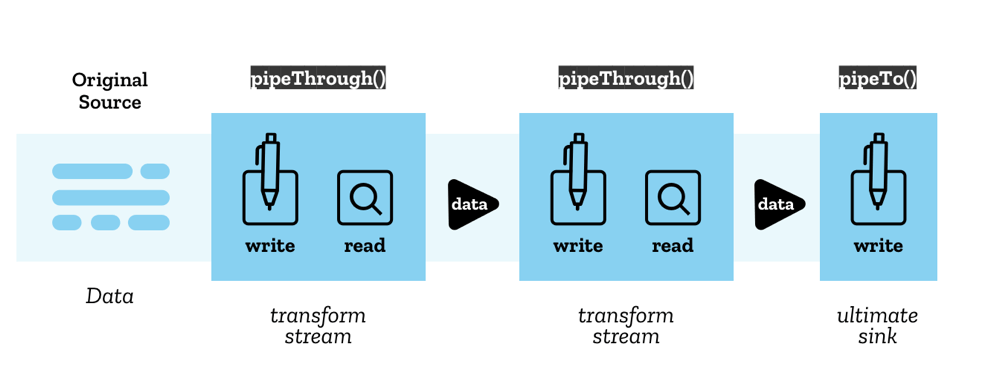
A API de Streams torna possível encadear streams (ou pelo menos irá fazer quando os navegadores implementarem a funcionalidade relevante para tal) usando uma estrutura chamada pipe chain. Há dois métodos disponíveis na especificação para facilitá-lo:
ReadableStream.pipeThrough()— pipes de stream através do transform stream, que é um par compreendido do writable stream que possui dados escritos, e readable stream que então tem os dados lidos dele — ele atua como um tipo de esteira que constantemente pega a entrada de dados e os transforma em um outro estado. Efetivamente o mesmo stream é escrito para então os mesmos valores serem lidos. Um simples exemplo é um decodificador de texto, onde bytes brutos são escritos, e então strings são lidas. Você pode encontrar mais ideias úteis e exemplos na especificação — leia Transform streams para ideias e this web sockets example.ReadableStream.pipeTo()— pipes para um writable stream que atua como um ponto final para a pipe chain.
Para iniciar um pipe chain é chamado o original source, e no final é chamado ultimate sink.
Nota:
Esta funcionalidade não está totalmente pensada ainda, embora disponível em muitos navegadores. Até certo ponto espero que a especificação dos writers pode contribuir para algo como uma clase TransformStream para criar facilmente transform stream.
Backpressure
Um importante conceito sobre streams é backpressure — é um processo pelo qual um stream simples ou uma pipe chain ajusta a velocidade de leitura/escrita. Quando um stream mais tarde na conrrente continua ocupado e não está ainda pronto para aceitar mais chunks, ele envia um sinal de volta através da corrente informar mais tarde o transform stream (ou a fonte original) para diminuir a velocidade de entrega conforme apropriado tal que você não precise terminar com um gargalo em algum lugar.
Para usar backpressure em um ReadableStream, podemos perguntar ao controller pelo tamanho do chunk desejado pelo consumer consultando o atributo ReadableStreamDefaultController.desiredSize no controller. Se estiver muito baixo, nosso ReadableStream pode informar sua underlying source de dados e o backpressure junto a cadeira de stream.
Se mais tarde o consumer novamente deseja receber dados, podemos usar o método pull no stream para informar nossa underlying source para alimentar nosso stream com dados.
Internal queues and queuing strategies
Como mencionado antes, os chunks de um stream que não foram ainda processados e finalizados são mantidos por uma internal queue (fila interna).
- No caso de readable stream, esses chunks foram enfileirados mas ainda não lidos.
- No caso do writable stream, esses chunks que foram escritos mas ainda não processados pela underlying sink.
Filas internas trabalham com uma queuing strategy, o qual dita informar a backpressure baseado na internal queue state.
Em geral, a estratégia compara o tamanho dos chunks na fila com o valor chamado no high water mark, o qual é o total do maior valor de chunk que a fila pode gerenciar de modo realista.
O cálculo realizado é
high water mark - total size of chunks in queue = desired size
O desired size é o tamanho de chunks que um stream ainda pode aceitar para manter o fluxo do stream menor que o high water mark. Após o cálculo ser efetuado, a geração de chunks terá sua velocidade reduzida ou aumentada conforme apropriado para manter o fluxo do stream o mais rápido possível enquanto mantém o tamanho desejado acima de zero. Se o valor cair para zero (ou menor no caso de writable streams), significa que os chunks estão sendo gerados mais rápido que o stream pode lidar, o qual resulta em problemas.
Nota: O que ocorre no caso em que valor desejado for zero ou negativo não foi definido na especificação até o momento. Paciência é uma virtude.
Como um exemplo, vamos pegar um chunk de tamanho 1, e uma high water mark de 3. Isto significa que até 3 chunks podem ser enfileirados antes que a high water mark seja alcançada e o backpressure aplicado.