Was ist eine URL?
Dieser Artikel behandelt Uniform Resource Locators (URLs), erklärt, was sie sind und wie sie strukturiert sind.
| Voraussetzungen: | Sie müssen zuerst verstehen, wie das Internet funktioniert, was ein Webserver ist und die Konzepte hinter Links im Web. |
|---|---|
| Ziel: | Sie werden lernen, was eine URL ist und wie sie im Web funktioniert. |
Zusammenfassung
Eine URL (Uniform Resource Locator) ist die Adresse einer einzigartigen Ressource im Internet. Sie ist einer der Hauptmechanismen, die von Browsern verwendet werden, um veröffentlichte Ressourcen abzurufen, wie etwa HTML-Seiten, CSS-Dokumente, Bilder und so weiter.
Theoretisch verweist jede gültige URL auf eine einzigartige Ressource. Praktisch gibt es einige Ausnahmen, die häufigste ist eine URL, die auf eine Ressource verweist, die nicht mehr existiert oder verschoben wurde. Da die durch die URL dargestellte Ressource und die URL selbst vom Webserver verwaltet werden, liegt es in der Verantwortung des Besitzers des Webservers, diese Ressource und die zugehörige URL sorgfältig zu verwalten.
Grundlagen: Anatomie einer URL
Hier sind einige Beispiele für URLs:
https://developer.mozilla.org https://developer.mozilla.org/en-US/docs/Learn_web_development/ https://developer.mozilla.org/en-US/search?q=URL
Jede dieser URLs kann in die Adressleiste Ihres Browsers eingegeben werden, um ihm mitzuteilen, dass er die zugehörige Ressource laden soll, die in allen drei Fällen eine Webseite ist.
Eine URL besteht aus verschiedenen Teilen, von denen einige obligatorisch und andere optional sind. Die wichtigsten Teile sind in der nachstehenden URL hervorgehoben (Details werden in den folgenden Abschnitten bereitgestellt):

Hinweis: Sie könnten eine URL wie eine normale Postadresse betrachten: Das Schema repräsentiert den Postdienst, den Sie verwenden möchten, der Domainname ist die Stadt oder der Ort, und der Port ist wie die Postleitzahl; der Pfad repräsentiert das Gebäude, in das Ihre Post geliefert werden soll; die Parameter repräsentieren zusätzliche Informationen wie die Nummer der Wohnung im Gebäude; und schließlich repräsentiert der Anker die tatsächliche Person, an die Sie Ihre Post adressiert haben.
Hinweis: Es gibt einige zusätzliche Teile und Regeln in Bezug auf URLs, aber sie sind für normale Benutzer oder Webentwickler nicht relevant. Machen Sie sich darüber keine Sorgen, Sie müssen sie nicht kennen, um voll funktionsfähige URLs zu erstellen und zu verwenden.
Schema

Der erste Teil der URL ist das Schema, das das Protokoll angibt, das der Browser verwenden muss, um die Ressource anzufordern (ein Protokoll ist eine festgelegte Methode zum Austausch oder Übertragen von Daten in einem Computernetzwerk). Normalerweise ist für Webseiten das Protokoll HTTPS oder HTTP (die ungesicherte Version). Beim Adressieren von Webseiten sind eines dieser beiden erforderlich, aber Browser können auch andere Schemata verarbeiten, wie mailto: (zum Öffnen eines Mail-Clients), also seien Sie nicht überrascht, wenn Sie andere Protokolle sehen.
Autorität

Es folgt die Autorität, die durch das Zeichenmuster :// vom Schema getrennt ist. Wenn vorhanden, enthält die Autorität sowohl die Domain (z.B. www.example.com) als auch den Port (80), getrennt durch einen Doppelpunkt:
- Die Domain gibt an, welcher Webserver angefordert wird. Normalerweise ist dies ein Domainname, aber eine IP-Adresse kann auch verwendet werden (dies ist jedoch selten, da es viel weniger praktisch ist).
- Der Port gibt das technische "Tor" an, das verwendet wird, um auf die Ressourcen auf dem Webserver zuzugreifen. Er wird normalerweise weggelassen, wenn der Webserver die Standardports des HTTP-Protokolls (80 für HTTP und 443 für HTTPS) verwendet, um Zugriff auf seine Ressourcen zu gewähren. Andernfalls ist er obligatorisch.
Hinweis:
Der Trenner zwischen Schema und Autorität ist ://. Der Doppelpunkt trennt das Schema vom nächsten Teil der URL, während // anzeigt, dass der nächste Teil der URL die Autorität ist.
Ein Beispiel für eine URL, die keine Autorität verwendet, ist der Mail-Client (mailto:foobar). Er enthält ein Schema, verwendet jedoch keine Autoritätskomponente. Daher folgt dem Doppelpunkt kein doppelter Schrägstrich und er dient nur als Trennzeichen zwischen dem Schema und der Mail-Adresse.
Pfad zur Ressource

/path/to/myfile.html ist der Pfad zur Ressource auf dem Webserver. In den frühen Tagen des Webs stellte ein solcher Pfad einen physischen Dateispeicherort auf dem Webserver dar. Heutzutage ist es meistens eine Abstraktion, die von Webservern ohne jegliche physische Realität gehandhabt wird.
Parameter
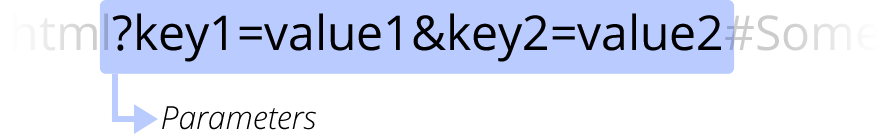
?key1=value1&key2=value2 sind zusätzliche Parameter, die dem Webserver bereitgestellt werden. Diese Parameter sind eine Liste von Schlüssel/Wert-Paaren, die durch das &-Symbol getrennt sind. Der Webserver kann diese Parameter nutzen, um vor der Rückgabe der Ressource zusätzliche Dinge zu tun. Jeder Webserver hat seine eigenen Regeln hinsichtlich der Parameter, und der einzige zuverlässige Weg, um zu wissen, ob ein bestimmter Webserver mit Parametern umgeht, besteht darin, den Besitzer des Webservers zu fragen.
Anker

#SomewhereInTheDocument ist ein Anker zu einem anderen Teil der Ressource selbst. Ein Anker stellt eine Art "Lesezeichen" innerhalb der Ressource dar, das dem Browser die Anweisungen gibt, den Inhalt an der "Lesezeichen"-Stelle anzuzeigen. In einem HTML-Dokument scrollt der Browser beispielsweise zu dem Punkt, an dem der Anker definiert ist; in einem Video- oder Audiodokument versucht der Browser, zu dem Zeitpunkt zu gehen, den der Anker repräsentiert. Es ist anzumerken, dass der Teil nach dem #, auch bekannt als Fragmentbezeichner, niemals mit der Anfrage an den Server gesendet wird.
Anleitung zur Nutzung von URLs
Jede URL kann direkt in die Adressleiste des Browsers eingegeben werden, um die dahinter liegende Ressource abzurufen. Aber das ist nur die Spitze des Eisbergs!
Die HTML-Sprache (siehe Inhalte strukturieren mit HTML) nutzt URLs in großem Umfang:
- um Links zu anderen Dokumenten mit dem
<a>-Element zu erstellen; - um ein Dokument mit seinen zugehörigen Ressourcen über verschiedene Elemente wie
<link>oder<script>zu verknüpfen; - um Medien wie Bilder (mit dem
<img>-Element), Videos (mit dem<video>-Element), Sounds und Musik (mit dem<audio>-Element) usw. anzuzeigen; - um andere HTML-Dokumente mit dem
<iframe>-Element anzuzeigen.
Hinweis:
Wenn Sie URLs angeben, um Ressourcen als Teil einer Seite zu laden (wie beim Verwenden der <script>, <audio>, <img>, <video>-Elemente und ähnlichen), sollten Sie im Allgemeinen nur HTTP- und HTTPS-URLs verwenden, mit wenigen Ausnahmen (eine bemerkenswerte ist data:; siehe Data URLs). Die Verwendung von FTP ist beispielsweise nicht sicher und wird von modernen Browsern nicht mehr unterstützt.
Andere Technologien wie CSS oder JavaScript verwenden URLs umfangreich, und sie bilden wirklich das Herzstück des Webs.
Absolute URLs vs. relative URLs
Das, was wir oben gesehen haben, wird als absolute URL bezeichnet, aber es gibt auch etwas, das als relative URL bezeichnet wird. Der URL-Standard definiert beide — obwohl er die Begriffe absolute URL string und relative URL string verwendet, um sie von URL-Objekten (die im Speicher gehaltene Darstellungen von URLs sind) zu unterscheiden.
Lassen Sie uns das Unterscheidungsmerkmal zwischen absolut und relativ im Kontext von URLs untersuchen.
Die erforderlichen Teile einer URL hängen stark vom Kontext ab, in dem die URL verwendet wird. In der Adressleiste Ihres Browsers hat eine URL keinen Kontext, daher müssen Sie eine vollständige (oder absolute) URL angeben, wie die, die wir oben gesehen haben. Sie müssen das Protokoll nicht einschließen (der Browser verwendet standardmäßig HTTP) oder den Port (der nur erforderlich ist, wenn der anvisierte Webserver einen ungewöhnlichen Port verwendet), aber alle anderen Teile der URL sind notwendig.
Wenn eine URL in einem Dokument verwendet wird, z. B. auf einer HTML-Seite, sind die Dinge etwas anders. Da der Browser bereits die eigene URL des Dokuments hat, kann er diese Informationen verwenden, um die fehlenden Teile einer URL in diesem Dokument auszufüllen. Wir können zwischen einer absoluten URL und einer relativen URL unterscheiden, indem wir nur den Pfad-Teil der URL betrachten. Wenn der Pfad-Teil der URL mit dem Zeichen / beginnt, wird der Browser diese Ressource vom obersten Stamm des Servers abrufen, ohne Bezug auf den Kontext, den das aktuelle Dokument gibt.
Schauen wir uns einige Beispiele an, um dies klarer zu machen. Nehmen wir an, dass die URLs aus dem Dokument heraus definiert sind, das sich unter der folgenden URL befindet: https://developer.mozilla.org/de/docs/Learn.
https://developer.mozilla.org/de/docs/Learn selbst ist eine absolute URL. Sie enthält alle notwendigen Teile, um die Ressource zu lokalisieren, auf die sie verweist.
Alle folgenden URLs sind relative URLs:
- Schema-relative URL:
//developer.mozilla.org/de/docs/Learn— es fehlt nur das Protokoll. Der Browser verwendet dasselbe Protokoll wie das, das zum Laden des Dokuments verwendet wurde, das diese URL enthält. - Domain-relative URL:
/de/docs/Learn— sowohl das Protokoll als auch der Domainname fehlen. Der Browser verwendet dasselbe Protokoll und denselben Domainnamen wie das, das zum Laden des Dokuments verwendet wurde, das diese URL enthält. - Unterressourcen:
Common_questions/Web_mechanics/What_is_a_URL— das Protokoll und der Domainname fehlen, und der Pfad beginnt nicht mit/. Der Browser versucht, das Dokument in einem Unterverzeichnis des Verzeichnisses zu finden, das die aktuelle Ressource enthält. In diesem Fall wollen wir wirklich diese URL erreichen:https://developer.mozilla.org/de/docs/Learn_web_development/Howto/Web_mechanics/What_is_a_URL. - Zurückgehen im Verzeichnisbaum:
../CSS/display— das Protokoll und der Domainname fehlen, und der Pfad beginnt mit... Dies stammt aus der UNIX-Dateisystemwelt — um dem Browser mitzuteilen, dass wir um eine Ebene nach oben gehen möchten. Hier möchten wir diese URL erreichen:https://developer.mozilla.org/de/docs/Learn_web_development/../Web/CSS/display, die vereinfacht werden kann zu:https://developer.mozilla.org/de/docs/Web/CSS/display. - Nur-Anker:
#semantic_urls- alle Teile fehlen außer dem Anker. Der Browser verwendet die URL des aktuellen Dokuments und ersetzt den Anker-Teil oder fügt ihn hinzu. Dies ist nützlich, wenn Sie zu einem bestimmten Teil des aktuellen Dokuments verlinken möchten.
Semantische URLs
Trotz ihres sehr technischen Charakters stellen URLs einen für Menschen lesbaren Einstiegspunkt für eine Website dar. Sie können memoriert werden, und jeder kann sie in die Adressleiste eines Browsers eingeben. Menschen stehen im Mittelpunkt des Webs, und daher gilt es als beste Praxis, sogenannte semantische URLs zu erstellen. Semantische URLs verwenden Wörter mit inhärenter Bedeutung, die von jedem verstanden werden können, unabhängig von ihrem technischen Wissen.
Linguistische Semantik ist natürlich für Computer irrelevant. Sie haben wahrscheinlich oft URLs gesehen, die wie Mischungen aus zufälligen Zeichen aussehen. Aber es gibt viele Vorteile bei der Erstellung für Menschen lesbarer URLs:
- Es ist einfacher für Sie, sie zu manipulieren.
- Es klärt Dinge für Benutzer, wo sie sich befinden, was sie tun, was sie lesen oder womit sie im Web interagieren.
- Einige Suchmaschinen können diese Semantiken verwenden, um die Klassifizierung der zugehörigen Seiten zu verbessern.
Siehe auch
Data URLs: URLs, die mit dem data:-Schema versehen sind, ermöglichen es Inhaltserstellern, kleine Dateien direkt in Dokumenten einzubetten.