什么是 URL?
本文讨论了统一资源定位符(URL),并解释了它是什么,以及它的结构。
| 前提: | 你首先需要知道互联网是如何工作的、什么是 Web 服务器,以及 Web 中超链接的概念。 |
|---|---|
| 目标: | 你将会学习到 URL 是什么,以及它在 Web 中是如何工作的。 |
概述
URL(统一资源定位符)是因特网中的唯一资源的地址。它是浏览器用于检索已发布资源(例如 HTML 页面、CSS 文档、图像等)的关键机制之一。
理论上说,每个有效的 URL 都指向一个唯一的资源。而在实际中,也有一些例外,最常见的情况就是一个 URL 指向了不存在的或是被移动过的资源。由于通过 URL 呈现的资源和 URL 本身由 Web 服务器处理,因此 Web 服务器的拥有者需要认真地维护资源以及与它关联的 URL。
基础:剖析 URL
下面是一些 URL 的示例:
https://developer.mozilla.org https://developer.mozilla.org/zh-CN/docs/Learn/ https://developer.mozilla.org/zh-CN/search?q=URL
你可以将上面的这些网址输进你的浏览器地址栏来告诉浏览器加载相关联的资源(在这三个示例中为网页)。
URL 由不同的部分组成,其中一些是必须的,而另一些是可选的。最重要的部分以在下面的 URL 上高亮(详细信息在下面的各节中提供):

备注:你可以将 URL 视为普通的邮寄地址:方案(scheme)表示你想要使用的邮政服务,域名(domain name)就像是城市或城镇,端口(port)就像邮政编码;路径(path)表示你的邮件应该送到的建筑物;参数(parameter)表示额外的信息,例如建筑物中公寓的编号;最后,锚点(anchor)表示邮件的实际收信人。
备注:关于 URL 还有一些额外的部分和规则,但对于普通用户或 Web 开发人员来说并不相关。不用担心这些,你不需要了解它们来构建和使用功能完整的 URL。
方案

URL 的第一部分是方案(scheme),它表示浏览器必须使用的协议来请求资源(协议是计算机网络中交换或传输数据的一组方法)。通常对于网站,协议是 HTTPS 或 HTTP(它的非安全版本)。访问网页需要这两者之一,但浏览器还知道如何处理其他方案,比如 mailto:(打开邮件客户端),所以如果你看到其他协议也不要感到惊讶。
权威

接下来是权威(authority),它与方案之间用字符模式 :// 分隔。如果存在,权威会包括域(例如 www.example.com)和端口(80),由冒号分隔:
- 域指示被请求的 Web 服务器。通常这是一个域名,但也可以使用 IP 地址(但这很少见,因为它不太方便)。
- 端口指示用于访问 Web 服务器上资源的技术“门户”。如果 Web 服务器使用 HTTP 协议的标准端口(HTTP 为 80,HTTPS 为 443)来授予对其资源的访问权限,则通常会省略端口。否则,端口是强制的。
备注:方案和权威之间的分隔符是 ://。冒号将方案与 URL 的下一部分分隔开,而 // 表示 URL 的下一部分是权威。
不使用权威的 URL 示例之一是邮件客户端(mailto:foobar)。它包含方案,而不使用权威的部分。因此,冒号后没有跟着两个斜杠,并且只充当方案和邮件地址之间的分隔符。
资源路径

/path/to/myfile.html 是 Web 服务器上资源的路径。在 Web 的早期阶段,像这样的路径表示 Web 服务器上的物理文件位置。如今,它主要是由没有任何物理现实的 Web 服务器处理的抽象。
参数
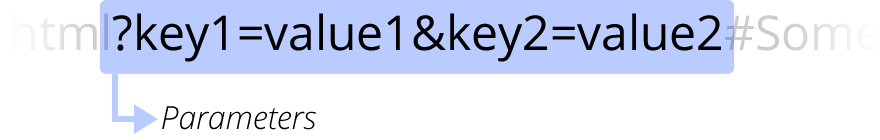
?key1=value1&key2=value2 是提供给 Web 服务器的额外参数。这些参数是用 & 符号分隔的键/值对列表。在返回资源之前,Web 服务器可以使用这些参数来执行额外的操作。每个 Web 服务器都有自己关于参数的规则,唯一可靠的方式来知道特定 Web 服务器是否处理参数是通过询问 Web 服务器所有者。
锚点

#SomewhereInTheDocument 是资源本身的另一部分的锚点。锚点表示资源中的一种“书签”,给浏览器显示位于该“加书签”位置的内容的方向。例如,在 HTML 文档上,浏览器将滚动到定义锚点的位置;在视频或音频文档上,浏览器将尝试转到锚代表的时间。值得注意的是,# 后面的部分(也称为片段标识符)不会随请求被发送到服务器。
如何使用 URL
可以直接在浏览器的地址栏里输入任何 URL,来获得后台的资源。但是这仅仅是冰山一角。
后续会再来讨论在 URL 中有着大量的使用的 HTML 语言:
- 创建到其他文档的链接,用
<a>元素; - 将文档与它的相关资源关联,用各种元素如
<link>或<script>; - 显示多媒体如图片(用
<img>元素)、视频(用<video>元素)、声音和音乐(用<audio>元素)等; - 显示其他 HTML 文档,用
<iframe>元素。
备注:当在页面中加载资源时指定 URL(例如使用 <script>、<audio>、<img>、<video> 等),通常应只使用 HTTP 和 HTTPS URL,除了一些例外情况(一个显著的例外是 data:;参见数据 URL)。例如,使用 FTP 是不安全的,并且不再受现代浏览器的支持。
其他大量使用 URL 的技术(如 CSS 或 JavaScript)才是 Web 的中心。
绝对 URL 和相对 URL
我们上面看到的是一个绝对 URL,但也有一个叫做相对 URL 的东西。URL 标准定义了两者——尽管它使用术语绝对 URL 字符串和相对 URL 字符串,以将它们与 URL 对象(URL 的内存表示)区分开来。
让我们来看看在 URL 的背景下,绝对和相对之间的区别是什么。
URL 的必需部分在很大程度上取决于使用 URL 的上下文。在浏览器的地址栏中,网址没有任何上下文,因此你必须提供一个完整的(或绝对的)URL,就像我们上面看到的一样。你不需要包括协议(浏览器默认使用 HTTP)或端口(仅当目标 Web 服务器使用某些非常用端口时才需要),但 URL 的所有其他部分都是必需的。
当文档中使用 URL 时,例如 HTML 页面中的内容有所不同。因为浏览器已经有文档自己的 URL,它可以使用这些信息来填写该文档中可用的任何 URL 的缺失部分。我们可以通过仅查看 URL 的路径部分来区分绝对 URL 和相对 URL。如果 URL 的路径部分以“/”字符开头,则浏览器将从服务器的顶部根目录获取该资源,而不引用当前文档给出的上下文。
我们来看一些示例来使这个更清楚。我们假设 URL 是在位于以下 URL 的文档中定义的:https://developer.mozilla.org/zh-CN/docs/Learn。
https://developer.mozilla.org/zh-CN/docs/Learn 本身是绝对 URL。它具有定位指向的资源所需的所有必要部分。
以下所有的 URL 是相对 URL:
- 方案相对 URL:
//developer.mozilla.org/zh-CN/docs/Learn——只缺少协议。浏览器将使用与用于加载托管该 URL 的文档相同的协议。 - 域相对 URL:
/zh-CN/docs/Learn——协议和域名同时缺失。浏览器将使用与用于加载托管该 URL 的文档相同的协议和域名。 - 子资源:
Common_questions/Web_mechanics/What_is_a_URL——协议和域名同时缺失,且路径不以/开头。浏览器将尝试在包含当前资源的子目录中查找文档。在这个例子中,我们真想得到的 URL 是:https://developer.mozilla.org/zh-CN/docs/Learn/Common_questions/Web_mechanics/What_is_a_URL。 - 在目录树中返回:
../CSS/display——协议和域名同时缺失,且路径以..开头。这是从 UNIX 文件系统世界继承的——告诉浏览器我们要回到上一级。在这里,我们想要得到的 URL 是:https://developer.mozilla.org/zh-CN/docs/Learn/../CSS/display,可以将其简化为:https://developer.mozilla.org/zh-CN/docs/CSS/display。 - 仅锚点:
#语义_url——除了锚点外,所有部分都缺失。浏览器将使用当前文档的 URL,并替换或添加锚点部分。当你想要链接到当前文档的特定部分时,这十分有用。
语义 URL
尽管 URL 具有非常的技术性,但 URL 表示一个人类可读的网站入口点。它们可以被记住,并且任何人都可以将它们输入浏览器的地址栏。人是 Web 的核心,因此建立所谓的语义 URL被认为是最佳实践。语义 URL 使用具有固有含义的单词,任何人都可以理解,无论他们的技术水平如何。
语言语义当然与电脑无关。你可能经常看到看起来像随机字符混搭的网址。但创建人类可读的 URL 有很多优点:
- 操作它们更容易。
- 可以让用户更清楚地了解他们在哪里、他们在做什么、他们正在阅读或在 Web 上进行交互的内容。
- 一些搜索引擎可以使用这些语义来改进相关页面的分类。
参见
数据 URL:以 data: 方案为前缀的 URL,允许内容创建者在文档中嵌入小文件。