Seitenbefüllung: Wie Browser funktionieren
Benutzer wünschen sich Web-Erlebnisse mit Inhalten, die schnell geladen werden und mit denen man reibungslos interagieren kann. Daher sollte ein Entwickler bestrebt sein, diese beiden Ziele zu erreichen.
Um zu verstehen, wie die Leistung und die wahrgenommene Leistung verbessert werden können, ist es hilfreich zu verstehen, wie der Browser funktioniert.
Überblick
Schnelle Websites bieten bessere Benutzererlebnisse. Benutzer erwarten und wünschen sich Web-Erlebnisse mit Inhalten, die schnell geladen werden und mit denen man reibungslos interagieren kann.
Zwei Hauptprobleme bei der Web-Performance sind Latenzprobleme und das Problem, dass Browser größtenteils einsträngig arbeiten.
Latenz ist die größte Bedrohung für unsere Fähigkeit, eine schnell ladende Seite sicherzustellen. Es ist das Ziel der Entwickler, die Website so schnell wie möglich zu laden – oder zumindest erscheinen zu lassen, als würde sie superschnell laden –, damit der Benutzer die angeforderten Informationen so schnell wie möglich erhält. Netzwerk-Latenz ist die Zeit, die benötigt wird, um Bytes über Funk an Computer zu übertragen. Web-Performance ist das, was wir tun müssen, um die Seite so schnell wie möglich zu laden.
Im Wesentlichen gelten Browser als einsträngig. Das bedeutet, sie führen eine Aufgabe von Anfang bis Ende aus, bevor sie eine andere Aufgabe angehen. Für reibungslose Interaktionen ist es das Ziel des Entwicklers, performante Seiteninteraktionen sicherzustellen, von reibungslosem Scrollen bis hin zur Reaktionsfähigkeit auf Berührungen. Renderzeit ist entscheidend; es muss sichergestellt sein, dass der Haupt-Thread all die Arbeit bewältigen kann, die wir ihm auftragen, und dennoch immer verfügbar ist, um auf Benutzerinteraktionen zu reagieren. Die Web-Performance kann verbessert werden, indem die einsträngige Natur des Browsers verstanden und die Verantwortlichkeiten des Haupt-Threads dort minimiert werden, wo es möglich und angemessen ist, um sicherzustellen, dass das Rendering reibungslos und die Reaktionen auf Interaktionen sofort erfolgen.
Navigation
Navigation ist der erste Schritt beim Laden einer Webseite. Sie erfolgt immer, wenn ein Benutzer eine Seite anfordert, indem er eine URL in die Adressleiste eingibt, auf einen Link klickt, ein Formular einreicht und andere ähnliche Handlungen vornimmt.
Eines der Ziele der Web-Performance ist es, die Zeit zu minimieren, die die Navigation benötigt, um abgeschlossen zu werden. Unter idealen Bedingungen dauert dies normalerweise nicht lange, aber Latenz und Bandbreite sind Gegner, die Verzögerungen verursachen können.
DNS-Abfrage
Der erste Schritt beim Navigieren zu einer Webseite ist das Auffinden der Lage der Assets für diese Seite. Wenn Sie zu https://example.com navigieren, befindet sich die HTML-Seite auf dem Server mit der IP-Adresse 93.184.216.34. Wenn Sie diese Seite noch nie besucht haben, muss eine DNS-Abfrage erfolgen.
Ihr Browser fordert eine DNS-Abfrage an, die letztendlich von einem Namensserver beantwortet wird, der wiederum mit einer IP-Adresse antwortet. Nach dieser ersten Anfrage wird die IP wahrscheinlich für eine Weile im Cache gespeichert, was nachfolgende Anfragen beschleunigt, indem die IP-Adresse aus dem Cache abgerufen wird, anstatt erneut einen Namensserver zu kontaktieren.
DNS-Abfragen müssen meist nur einmal pro Hostname für einen Seitenaufruf durchgeführt werden. Allerdings müssen DNS-Abfragen für jeden eindeutigen Hostnamen erfolgen, auf den die angeforderte Seite verweist. Wenn Ihre Schriften, Bilder, Skripte, Anzeigen und Metriken alle unterschiedliche Hostnamen haben, muss für jeden ein DNS-Lookup durchgeführt werden.

Dies kann problematisch für die Leistung sein, insbesondere in Mobilfunknetzen. Wenn ein Benutzer in einem Mobilfunknetzwerk ist, muss jede DNS-Abfrage vom Telefon über den Funkmast gehen, um einen autoritativen DNS-Server zu erreichen. Die Entfernung zwischen einem Telefon, einem Funkmast und dem Namensserver kann eine erhebliche Latenz hinzufügen.
TCP-Handshake
Sobald die IP-Adresse bekannt ist, stellt der Browser eine Verbindung zum Server über einen TCP-Drei-Wege-Handshake her. Dieser Mechanismus ist so konzipiert, dass zwei Einheiten, die versuchen zu kommunizieren - in diesem Fall der Browser und der Webserver - die Parameter der TCP-Netzwerksockel-Verbindung verhandeln können, bevor Daten gesendet werden, in der Regel über HTTPS.
Die Drei-Wege-Handshake-Technik von TCP wird oft als "SYN-SYN-ACK" bezeichnet - oder genauer SYN, SYN-ACK, ACK - weil TCP drei Nachrichten übermittelt, um eine TCP-Sitzung zwischen zwei Computern auszuhandeln und zu starten. Ja, das bedeutet drei weitere Nachrichten hin und her zwischen jedem Server, und die Anfrage wurde noch nicht gestellt.
TLS-Verhandlung
Für sichere Verbindungen, die über HTTPS hergestellt werden, ist ein weiterer "Handshake" erforderlich. Diese Verhandlung, oder besser gesagt die TLS-Verhandlung, bestimmt, welcher Verschlüsselungsalgorithmus zur Verschlüsselung der Kommunikation verwendet wird, überprüft den Server und stellt sicher, dass eine sichere Verbindung besteht, bevor der tatsächliche Datentransfer beginnt. Dies erfordert fünf weitere Rundreisen zum Server, bevor die Anfrage nach Inhalten tatsächlich gesendet wird.

Während das Herstellen der Verbindung sicher zusätzliche Zeit zum Laden der Seite hinzufügt, ist eine sichere Verbindung die Latenz wert, da die zwischen dem Browser und dem Webserver übertragenen Daten von Dritten nicht entschlüsselt werden können.
Nach den acht Rundreisen zum Server ist der Browser schließlich in der Lage, die Anfrage zu stellen.
Antwort
Sobald wir eine etablierte Verbindung zu einem Webserver haben, sendet der Browser eine anfängliche HTTP GET-Anfrage im Namen des Benutzers, die bei Websites meistens eine HTML-Datei ist. Sobald der Server die Anfrage erhält, antwortet er mit relevanten Antwort-Headern und dem Inhalt des HTML.
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My simple page</title>
<link rel="stylesheet" href="styles.css" />
<script src="myscript.js"></script>
</head>
<body>
<h1 class="heading">My Page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="my-image.jpg" alt="image description" />
</div>
<script src="another-script.js"></script>
</body>
</html>
Diese Antwort auf diese anfängliche Anfrage enthält das erste empfangene Datenbyte. Time to First Byte (TTFB) ist die Zeit zwischen dem Moment, in dem der Benutzer die Anfrage gestellt hat - zum Beispiel durch Klicken auf einen Link - und dem Empfang dieses ersten HTML-Pakets. Der erste Datenblock ist normalerweise 14 KB groß.
In unserem obigen Beispiel ist die Anfrage definitiv weniger als 14 KB, aber die verlinkten Ressourcen werden erst angefordert, wenn der Browser während der unten beschriebenen Analyse auf die Links stößt.
Staukontrolle / TCP Slow Start
TCP-Pakete werden während der Übertragung in Segmente aufgeteilt. Da TCP die Reihenfolge der Pakete garantiert, muss der Server nach dem Senden einer bestimmten Anzahl von Segmenten eine Empfangsbestätigung vom Client in der Form eines ACK-Pakets erhalten.
Wenn der Server nach jedem Segment auf ein ACK wartet, führt das zu häufigen ACKs vom Client und kann die Übertragungszeit erhöhen, selbst bei niedriger Netzauslastung.
Auf der anderen Seite kann das Senden von zu vielen Segmenten auf einmal dazu führen, dass in einem stark ausgelasteten Netzwerk der Client die Segmente nicht empfangen kann und nur lange Zeit mit ACKs antwortet, und der Server die Segmente immer wieder neu senden muss.
Um die Anzahl der gesendeten Segmente auszubalancieren, wird der Algorithmus TCP Slow Start verwendet, um die Menge der gesendeten Daten allmählich zu erhöhen, bis die maximale Netzwerkbandbreite ermittelt werden kann, und um die Menge der gesendeten Daten bei hoher Netzauslastung zu reduzieren.
Die Anzahl der zu sendenden Segmente wird durch den Wert des Stau-Fensters (CWND) gesteuert, das mit 1, 2, 4 oder 10 MSS (MSS sind 1500 Bytes über das Ethernet-Protokoll) initialisiert werden kann. Dieser Wert ist die Anzahl der Bytes, die gesendet werden sollen, deren Empfang der Client bestätigen muss.
Wenn ein ACK empfangen wird, wird der CWND-Wert verdoppelt, sodass der Server beim nächsten Mal mehr Segmente senden kann. Wird stattdessen kein ACK empfangen, wird der CWND-Wert halbiert. Dieser Mechanismus erreicht so ein Gleichgewicht zwischen dem Senden von zu vielen und zu wenigen Segmenten.
Parsing
Sobald der Browser den ersten Datenblock empfängt, kann er mit dem Parsing der empfangenen Informationen beginnen. Parsing ist der Schritt, in dem der Browser die über das Netzwerk empfangenen Daten in den DOM und CSSOM umwandelt, die vom Renderer verwendet werden, um eine Seite auf dem Bildschirm darzustellen.
Der DOM ist die interne Darstellung der Markup-Sprache für den Browser. Der DOM ist auch über verschiedene APIs in JavaScript zugänglich und manipulierbar.
Selbst wenn das HTML der angeforderten Seite größer als das anfängliche 14 KB-Paket ist, beginnt der Browser mit dem Parsing und versucht, eine Erfahrung basierend auf den verfügbaren Daten zu rendern. Aus diesem Grund ist es wichtig, dass die Web-Performance-Optimierung alles umfasst, was der Browser benötigt, um mit dem Rendern einer Seite zu beginnen, oder zumindest eine Vorlage der Seite - das CSS und HTML, das für das erste Rendering benötigt wird - im ersten 14 KB-Paket enthält. Aber bevor etwas auf den Bildschirm gerendert wird, müssen das HTML, CSS und JavaScript geparst werden.
Aufbau des DOM-Baums
Wir beschreiben fünf Schritte im kritischen Rendering-Pfad.
Der erste Schritt ist das Verarbeiten der HTML-Markup-Sprache und der Aufbau des DOM-Baums. Das HTML-Parsen umfasst die Tokenisierung und den Baumaufbau. HTML-Tokens umfassen Start- und End-Tags sowie Attributnamen und -werte. Wenn das Dokument gut strukturiert ist, ist das Parsing einfach und schneller. Der Parser parst eingetokene Eingaben in das Dokument und baut den Dokumentbaum auf.
Der DOM-Baum beschreibt den Inhalt des Dokuments. Das <html>-Element ist das erste Element und der Wurzelknoten des Dokumentbaums. Der Baum spiegelt die Beziehungen und Hierarchien zwischen verschiedenen Elementen wider. In andere Elemente geschachtelte Elemente sind Kindknoten. Je mehr DOM-Knoten vorhanden sind, desto länger dauert es, den DOM-Baum zu konstruieren.
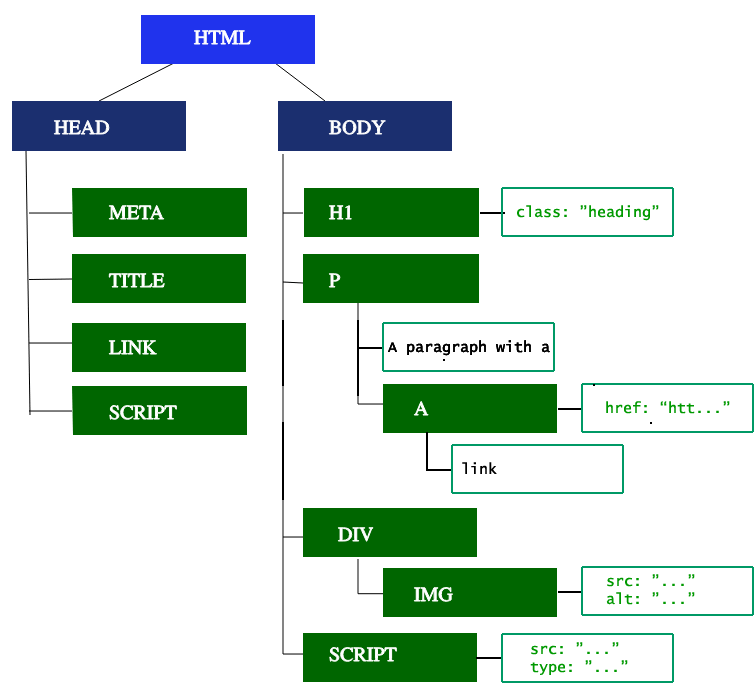
Wenn der Parser nicht blockierende Ressourcen wie ein Bild findet, fordert der Browser diese Ressourcen an und setzt das Parsing fort. Das Parsing kann fortgesetzt werden, wenn eine CSS-Datei entdeckt wird, aber <script>-Elemente – insbesondere solche ohne das async oder defer-Attribut – blockieren das Rendering und pausieren das Parsing von HTML. Obwohl der Preload-Scanner diesen Prozess beschleunigt, können übermäßige Skripte trotzdem ein erheblicher Engpass sein.
Preload-Scanner
Während der Browser den DOM-Baum erstellt, belegt dieser Prozess den Haupt-Thread. Während dies geschieht, durchsucht der Preload-Scanner den verfügbaren Inhalt und fordert hochpriorisierte Ressourcen wie CSS, JavaScript und Web-Schriften an. Dank des Preload-Scanners müssen wir nicht warten, bis der Parser einen Verweis auf eine externe Ressource findet, um sie anzufordern. Er ruft Ressourcen im Hintergrund ab, sodass sie möglicherweise bereits unterwegs sind oder heruntergeladen wurden, wenn der Haupt-HTML-Parser die angeforderten Assets erreicht. Die Optimierungen, die der Preload-Scanner bietet, reduzieren Blockaden.
<link rel="stylesheet" href="styles.css" />
<script src="my-script.js" async></script>
<img src="my-image.jpg" alt="image description" />
<script src="another-script.js" async></script>
In diesem Beispiel findet der Preload-Scanner während der Haupt-Thread das HTML und CSS analysiert, Skripte und Bilder, und beginnt, sie ebenfalls herunterzuladen. Um sicherzustellen, dass das Skript den Prozess nicht blockiert, fügen Sie das async-Attribut hinzu, oder das defer-Attribut, wenn Parsing und Ausführungsreihenfolge von JavaScript wichtig sind.
Das Warten auf das Abrufen von CSS blockiert nicht das HTML-Parsen oder Herunterladen, aber es blockiert JavaScript, da JavaScript oft verwendet wird, um die Auswirkungen von CSS-Eigenschaften auf Elemente abzufragen.
Aufbau des CSSOM-Baums
Der zweite Schritt im kritischen Rendering-Pfad ist das Verarbeiten von CSS und der Aufbau des CSSOM-Baums. Das CSS-Objektmodell ist dem DOM ähnlich. Der DOM und der CSSOM sind beide Bäume. Sie sind unabhängige Datenstrukturen. Der Browser konvertiert die CSS-Regeln in eine Karte von Stilen, die er verstehen und verarbeiten kann. Der Browser geht durch jede Regel im CSS und erstellt einen Baum von Knoten mit Eltern-, Kinder- und Geschwisterbeziehungen basierend auf den CSS-Selektoren.
Wie bei HTML muss der Browser die empfangenen CSS-Regeln in etwas konvertieren, mit dem er arbeiten kann. Deshalb wiederholt er den HTML-zu-Objekt-Prozess für das CSS.
Der CSSOM-Baum umfasst Stile aus dem Benutzeragenten-Stylesheet. Der Browser beginnt mit der allgemeinsten Regel, die auf einen Knoten anwendbar ist, und verfeinert rekursiv die berechneten Stile, indem spezifischere Regeln angewendet werden. Mit anderen Worten, er kaskadiert die Eigenschaftswerte.
Der Aufbau des CSSOM ist sehr, sehr schnell, und diese Bauzeitinformationen werden nicht in den Entwicklertools angezeigt. Stattdessen zeigt "Stile neu berechnen" in den Entwicklertools die Gesamtzeit an, die nötig ist, um CSS zu analysieren, den CSSOM-Baum zu erstellen, und berechnete Stile rekursiv zu berechnen. In Bezug auf die Web-Performance gibt es viele bessere Möglichkeiten, Optimierungsbemühungen zu investieren, da die Gesamtzeit zur Erstellung des CSSOM in der Regel weniger als die Zeit für ein DNS-Lookup beträgt.
Andere Prozesse
JavaScript-Kompilierung
Während das CSS analysiert und der CSSOM erstellt wird, werden andere Assets, einschließlich JavaScript-Dateien, heruntergeladen (dank des Preload-Scanners). JavaScript wird analysiert, kompiliert und interpretiert. Die Skripte werden in abstrakte Syntaxbäume geparst. Einige Browser-Engines nehmen die abstrakten Syntaxbäume und geben sie in einen Compiler ein, der Bytecode ausgibt. Dies ist als JavaScript-Kompilierung bekannt. Der Großteil des Codes wird im Haupt-Thread interpretiert, aber es gibt Ausnahmen wie Code, der in Web-Workern ausgeführt wird.
Aufbau des Zugänglichkeitsbaums
Der Browser erstellt auch einen Zugänglichkeitsbaum, den Hilfsgeräte verwenden, um Inhalte zu parsen und zu interpretieren. Das Accessibility Object Model (AOM) ist wie eine semantische Version des DOM. Der Browser aktualisiert den Zugänglichkeitsbaum, wenn der DOM aktualisiert wird. Der Zugänglichkeitsbaum kann von Hilfstechnologien selbst nicht modifiziert werden.
Bis der AOM erstellt ist, ist der Inhalt nicht für Bildschirmleseprogramme zugänglich.
Rendern
Die Rendering-Schritte umfassen Stil, Layout, Malen und in einigen Fällen Compositing. Die im Parsing-Schritt erstellten CSSOM- und DOM-Bäume werden in einem Renderbaum kombiniert, der dann verwendet wird, um das Layout jedes sichtbaren Elements zu berechnen, das dann auf dem Bildschirm gemalt wird. In einigen Fällen kann Inhalt auf seine eigene Ebene gefördert und zusammengesetzt werden, was die Performance verbessert, indem Teile des Bildschirms auf der GPU anstelle der CPU gemalt werden, was den Haupt-Thread entlastet.
Stil
Der dritte Schritt im kritischen Rendering-Pfad besteht darin, den DOM und den CSSOM in einen Renderbaum zu kombinieren. Die Stilberechnungsbaum- oder Renderbaum-Konstruktion beginnt mit der Wurzel des DOM-Baums und durchläuft jeden sichtbaren Knoten.
Elemente, die nicht angezeigt werden sollen, wie das <head>-Element und seine Kinder sowie alle Knoten mit display: none, wie das script { display: none; }, das Sie in Benutzeragenten-Stylesheets finden, sind nicht im Renderbaum enthalten, da sie im gerenderten Ergebnis nicht dargestellt werden. Knoten mit angewendetem visibility: hidden werden im Renderbaum enthalten, da sie Platz beanspruchen. Da wir keine Direktiven angegeben haben, um die Benutzeragenten-Standardeinstellungen zu überschreiben, wird der script-Knoten in unserem obigen Codebeispiel nicht im Renderbaum enthalten sein.
Jedem sichtbaren Knoten werden seine CSSOM-Regeln angewendet. Der Renderbaum enthält alle sichtbaren Knoten mit Inhalten und berechneten Stilen – er ordnet alle relevanten Stile jedem sichtbaren Knoten im DOM-Baum zu und bestimmt anhand der CSS-Kaskade, welche berechneten Stile für jeden Knoten anzuwenden sind.
Layout
Der vierte Schritt im kritischen Rendering-Pfad ist der Layout-Durchlauf des Renderbaums, um die Geometrie jedes Knotens zu berechnen. Layout ist der Prozess zur Bestimmung der Abmessungen und der Position aller Knoten im Renderbaum, sowie zur Festlegung der Größe und Position jedes Objekts auf der Seite. Reflow ist jede nachfolgende Größen- und Positionsbestimmung eines Teils der Seite oder des gesamten Dokuments.
Sobald der Renderbaum erstellt ist, beginnt das Layout. Der Renderbaum hat bestimmt, welche Knoten angezeigt werden (auch wenn sie unsichtbar sind) zusammen mit ihren berechneten Stilen, aber nicht mit den Abmessungen oder dem Ort jedes Knotens. Um die genaue Größe und Position jedes Objekts zu bestimmen, beginnt der Browser beim Stamm des Renderbaums und durchläuft ihn.
Auf der Webseite ist fast alles ein Kasten. Unterschiedliche Geräte und unterschiedliche Desktop-Präferenzen bedeuten eine unbegrenzte Anzahl unterschiedlicher Ansichtsfenstergrößen. In dieser Phase, unter Berücksichtigung der Ansichtsfenstergröße, bestimmt der Browser, welche Größen alle unterschiedlichen Kästen auf dem Bildschirm haben werden. Ausgehend von der Größe des Ansichtsfensters beginnt das Layout normalerweise mit dem body, legt die Größen aller Nachkommen des body fest, wobei jede Element-Box-Model-Eigenschaft Platzhalterraum für ersetzte Elemente bereitstellt, deren Dimensionen es nicht kennt, wie unser Bild.
Das erste Mal, dass die Größe und Position jedes Knotens bestimmt werden, wird als Layout bezeichnet. Nachfolgende Neuberechnungen des Layouts werden als Reflows bezeichnet. In unserem Beispiel nehmen wir an, dass das erste Layout vor der Rückgabe des Bildes erfolgt. Da wir die Dimensionen unseres Bildes nicht deklariert haben, erfolgt ein Reflow, sobald die Bilddimensionen bekannt sind.
Paint
Der letzte Schritt im kritischen Rendering-Pfad ist das Malen der einzelnen Knoten auf den Bildschirm, wobei das erste Vorkommen als First Meaningful Paint bezeichnet wird. In der Mal- oder Rasterisierungsphase konvertiert der Browser jeden im Layout-Schritt berechneten Kasten in tatsächliche Pixel auf dem Bildschirm. Das Malen umfasst das Zeichnen jedes visuellen Teils eines Elements auf den Bildschirm, einschließlich Text, Farben, Rändern, Schatten und ersetzten Elementen wie Schaltflächen und Bildern. Der Browser muss dies sehr schnell tun.
Um ein reibungsloses Scrollen und Animationen zu gewährleisten, muss alles, was den Haupt-Thread beansprucht, einschließlich der Berechnung von Stilen, zusammen mit Reflow und Paint, dem Browser weniger als 16,67 ms beanspruchen. Bei 2048 x 1536 hat das iPad über 3.145.000 Pixel, die auf den Bildschirm gemalt werden müssen. Das sind viele Pixel, die sehr schnell gemalt werden müssen. Um sicherzustellen, dass das Übermalen noch schneller als das erste Malen durchgeführt werden kann, wird das Zeichnen auf den Bildschirm im Allgemeinen in mehrere Schichten aufgeteilt. Wenn dies auftritt, ist ein Compositing erforderlich.
Das Malen kann die Elemente im Layoutbaum in Schichten aufteilen. Das Fördern von Inhalten in Schichten auf der GPU (anstelle des Haupt-Threads auf der CPU) verbessert die Paint- und Repaint-Performance. Es gibt bestimmte Eigenschaften und Elemente, die eine Schicht instanzieren, einschließlich <video> und <canvas>, und jedes Element, das die CSS-Eigenschaften von opacity, einer 3D-transform, will-change und einigen anderen hat. Diese Knoten werden zusammen mit ihren Nachfahren, es sei denn, ein Nachfahre benötigt eine eigene Schicht aus einem der oben genannten Gründe, auf ihrer eigenen Schicht gemalt.
Schichten verbessern die Leistung, sind jedoch in Bezug auf das Speichermanagement teuer, daher sollten sie nicht übermäßig als Teil von Web-Performance-Optimierungsstrategien verwendet werden.
Compositing
Wenn Abschnitte des Dokuments in verschiedenen Schichten gezeichnet werden und sich überlappen, ist Compositing erforderlich, um sicherzustellen, dass sie in der richtigen Reihenfolge auf den Bildschirm gezeichnet werden und der Inhalt korrekt angezeigt wird.
Während die Seite weiterhin Assets lädt, können Reflows auftreten (erinnern Sie sich an unser Beispielbild, das zu spät ankam). Ein Reflow führt zu einem Neumalen und einem neuen Compositing. Hätten wir die Dimensionen unseres Bildes definiert, wäre kein Reflow notwendig gewesen, und nur die Schicht, die neu bemalt werden musste, hätte neu bemalt und bei Bedarf zusammengesetzt worden. Aber wir haben die Bilddimensionen nicht angegeben! Wenn das Bild vom Server abgerufen wird, kehrt der Rendering-Prozess zu den Layout-Schritten zurück und beginnt dort erneut.
Interaktivität
Sobald der Haupt-Thread mit dem Malen der Seite fertig ist, denkt man, dass alles "erledigt" wäre. Das ist jedoch nicht unbedingt der Fall. Wenn das Laden JavaScript umfasst, das korrekt verschoben wurde und erst nach dem onload-Ereignis ausgeführt wird, könnte der Haupt-Thread beschäftigt sein und nicht für Scrollen, Berührungen und andere Interaktionen verfügbar sein.
Time to Interactive (TTI) ist das Maß dafür, wie lange es gedauert hat, von dieser ersten Anfrage, die zu der DNS-Abfrage und der TCP-Verbindung führte, bis die Seite interaktiv wurde – interaktiv bedeutet der Zeitpunkt nach dem First Contentful Paint, wenn die Seite innerhalb von 50ms auf Benutzerinteraktionen reagiert. Wenn der Haupt-Thread beschäftigt ist, JavaScript zu analysieren, zu kompilieren und auszuführen, ist er nicht verfügbar und kann daher nicht rechtzeitig (weniger als 50ms) auf Benutzerinteraktionen reagieren.
In unserem Beispiel könnte das Bild schnell geladen worden sein, aber vielleicht war die Datei another-script.js 2 MB groß und die Netzwerkverbindung unseres Benutzers war langsam. In diesem Fall würde der Benutzer die Seite sehr schnell sehen, aber nicht ohne Ruckeln scrollen können, bis das Skript heruntergeladen, geparst und ausgeführt wurde. Das ist kein gutes Benutzererlebnis. Vermeiden Sie es, den Haupt-Thread zu beanspruchen, wie in diesem WebPageTest-Beispiel demonstriert:

In diesem Beispiel dauerte die JavaScript-Ausführung über 1,5 Sekunden, und der Haupt-Thread war die gesamte Zeit vollständig ausgelastet, nicht ansprechbar auf Klickereignisse oder Bildschirmberührungen.