HTML 调试
HTML 优雅明了,但要是出了错,你会不会一头雾水呢,本节将介绍一些查找和修复 HTML 错误的工具。
| 前提: | 阅读并理解 HTML 入门、HTML 文字处理初步 和 创建超链接 等文章,熟悉 HTML 的基本概念。 |
|---|---|
| 学习目标: | 学习调试工具的基础用法,以查找 HTML 中的错误。 |
调试并不可怕
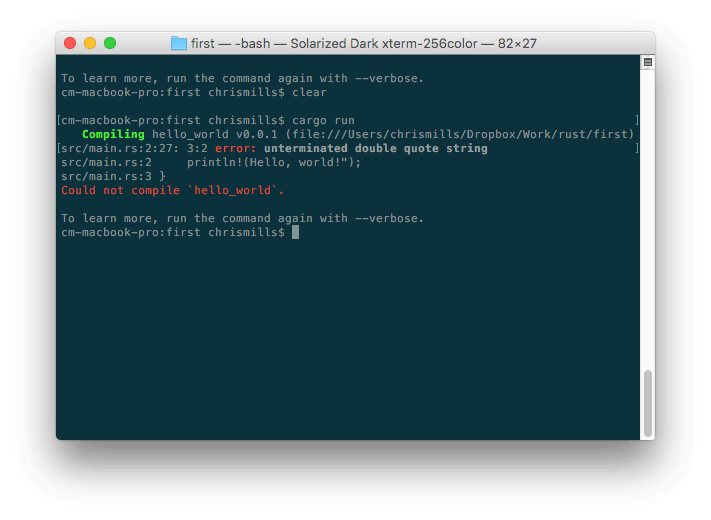 这里错误信息比较容易理解:"unterminated double quote string",即"双引号字符串未闭合"。错误列表中可以看到
这里错误信息比较容易理解:"unterminated double quote string",即"双引号字符串未闭合"。错误列表中可以看到 HTML 和调试
HTML 并不像 Rust 那么难以理解,浏览器并不会将 HTML 编译成其他形式,而是直接解析并显示结果(称之为解释,而非编译)。可以说 HTML 的 元素 语法比 Rust、JavaScript 或 Python 这样“真正的编程语言”更容易理解。浏览器解析 HTML 的过程比编程语言的编译运行的过程要宽松得多,但这是一把双刃剑。
宽松的代码
宽松是什么意思呢?通常写错代码会带来以下两种主要类型的错误:
- 语法错误:由于拼写错误导致程序无法运行,就像上面的 Rust 示例。通常熟悉语法并理解错误信息后很容易修复。
- 逻辑错误:不存在语法错误,但代码无法按预期运行。通常逻辑错误比语法错误更难修复,因为无法得到指向错误源头的信息。
HTML 本身不容易出现语法错误,因为浏览器是以宽松模式运行的,这意味着即使出现语法错误浏览器依然会继续运行。浏览器通常都有内建规则来解析书写错误的标记,所以即使与预期不符,页面仍可显示出来。当然,是存在隐患的。
备注:HTML 之所以以宽松的方式进行解析,是因为 Web 创建的初心就是:人人可发布内容,不去纠结代码语法。如果 Web 以严格的风格起步,也许就不会像今天这样流行了。
主动学习:研究宽容的代码风格
现在来研究 HTML 代码的宽松特性。
-
首先,下载并保存 debug-example.html。代码中故意留了一些错误,以便探究(这里的 HTML 标记写成了糟糕的格式,与良好的格式相反)。
-
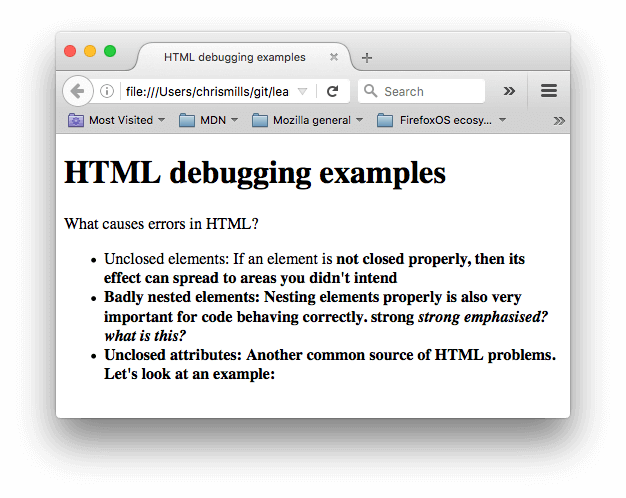
下一步,在浏览器中打开,可以看到:
-
看起来糟透了,我们到源代码中寻找原因(只列出
body部分):html<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> -
以下是问题清单:
- 段落(Paragraph) 和 列表项(list item) 元素没有结束标签。但是由于元素的结束和另一个的开始很容易推断出来,因此上图中并没有太严重的渲染错误。
- 第一个
<strong>元素没有结束标签。这就严重了,因为该元素结束的位置难以确定。事实上所有剩余文本都加粗了。 - 以下嵌套有问题:
<strong>重点(strong)<em>重点强调(strongly emphasised)?</strong>这又是什么鬼?</em>。浏览器很难做出正确解释,理由同上。 href属性缺少了一个双引号。从而导致了一个最严重的问题:整个链接完全没有渲染出来。
-
下面暂时忽略源代码中的标记,先看一下浏览器渲染出的标记。打开浏览器的开发者工具。如果不太熟悉,请先阅读 浏览器开发工具概览。
-
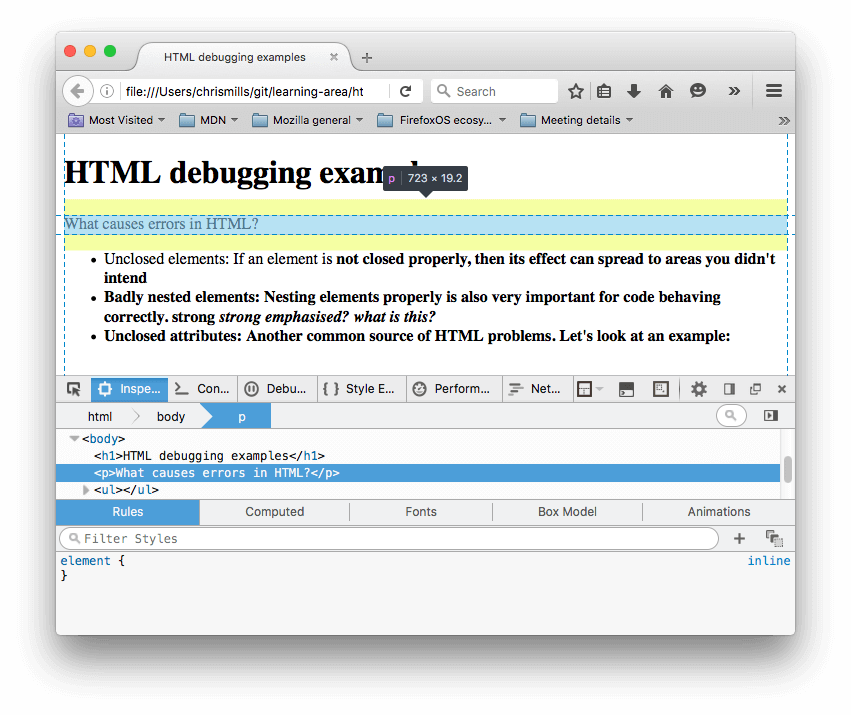
在 DOM 查看器中可以看到渲染的标记:
-
通过 DOM 查看器可以清楚地看到,浏览器已经尝试修补代码错误(我们尝试了 Firefox,其他现代浏览器也应给出同样结果):
-
段落和列表元素加上了关闭标签。
-
第一个
<strong>没有明确的关闭标签,因此浏览器为之后所有独立块都补全了<strong></strong>。 -
浏览器是这样修补嵌套错误的:
html<strong >重点(strong) <em>重点强调(strongly emphasised)?</em> </strong> <em>这又是什么鬼?</em> -
删除整个缺少双引号的链接。最后一个列表项就成了:
html<li> <strong>未闭合的属性:另一种 HTML 常见错误。来看一个示例:</strong> </li>
-
HTML 验证
阅读以上示例后,你发现保持良好 HTML 格式的重要性。那么应该如何做呢?以上示例规模较小,查找错误还不难,但是一个非常庞大、复杂的 HTML 文档呢?
最好的方法就是让你的 HTML 页面通过 Markup Validation Service。由 W3C(制定 HTML、CSS 和其他网络技术标准的组织)创立并维护的标记验证服务。把一个 HTML 文档加载至本网页并运行,网页会返回一个错误报告。
网页可以接受网址、上传一个 HTML 文档,或者直接输入一些 HTML 代码。
主动学习:验证 HTML 文档
不妨用上文的 debug-example.html 尝试一下:
- 在浏览器中打开 Markup Validation Service 。
- 选择 Validate by Direct Input 标签。
- 将整个示例文档的代码(而不仅仅是
body部分)复制粘贴到正中的文本框内。 - 点击 Check 按钮。
将返回一个包含错误和其他信息的列表。
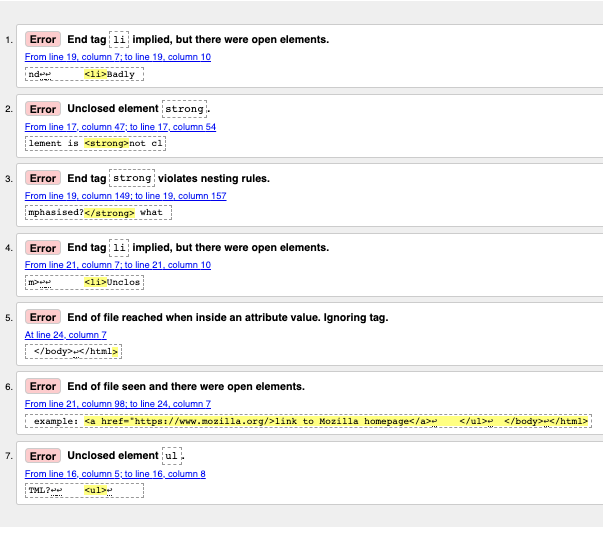
错误信息分析
错误信息一般都是有用的,也有没用的,有一些经验后你就能够分析并修复这些错误。下面来观察这些错误信息。可以看到每条信息都对应一个行号和一条信息,使得定位错误更方便。
-
End tag
liimplied, but there were open elements(需要li的结束标签,但又开始了新的元素)(共出现 2 次):这条信息表明有开始标签必须有结束标签,必须出现结束标签的地方却没有找到它。行/列信息指出结束标签必须出现的位置的第一行,这一线索已经足够明显了。 -
Unclosed element
strong(未闭合元素strong):非常容易理解,<strong>元素没有闭合,行/列信息表明了它的位置。 -
End tag
strongviolates nesting rules(结束标签strong违反了嵌套规则):指出了错误嵌套的元素,行/列信息表明了它的位置。 -
End of file reached when inside an attribute value. Ignoring tag(在属性值内达到文件末尾。忽略标签): 这个比较难懂,它说的是在某个地方有一个属性的值格式有误,估计是在文件末尾附近,因为文件的结尾出现在了一个属性值里。事实上浏览器没有渲染超链接已经是一个很明显的线索了。
-
End of file seen and there were open elements(文件结尾有未闭合的元素):这个略有歧义,但基本上表明了有元素没有正确闭合。行号指向文件最后几行,且错误信息给出了一个这种错误的案例:
来看一个示例:<a href="https://www.mozilla.org/>Mozilla 主页链接</a> ↩ </ul>↩ </body>↩</html>
备注:属性缺少结束引号会导致元素无法闭合。因为文档所有剩余部分(直到文档某处出现一个引号)都将被解析为属性的内容。
-
Unclosed element
ul(未闭合元素ul):这个意义不大,因为<ul>已经正确闭合了。出现这个错误是因为<a>元素没有右引号而没有闭合。
如果你不能一次弄懂所有的错误,别着急,可以试试先修复那些已经弄懂的,再申请验证,看看剩下哪些错误。有时候先修复的错误可能让你摆脱后面一系列的错误,因为一个小问题可能引发一连串错误,就像多米诺骨牌。
所有错误都修复之后会得到以下输出:
![]()