Présentation du côté serveur
Bienvenue au cours pour débutant de MDN sur la programmation côté serveur. Dans ce premier article, nous allons regarder la programmation côté serveur sans rentrer dans les détails techniques, en répondant aux questions telles que "qu'est-ce que c'est?", "quelle est la différence avec la programmation côté client?", et "pourquoi est-ce utile?". Après avoir lu cet article vous comprendrez commment la programmation côté serveur donne toute leur puissance aux sites web.
| Prérequis: | Connaissances de base en informatique. Une compréhension de base de ce qu'est un serveur web. |
|---|---|
| Objectif: | Se familiariser avec la programmation côté serveur, ce qu'elle peut faire, et en quoi elle diffère de la programmation côté client. |
La plupart des sites web à grande échelle utilisent du code côté serveur pour afficher dynamiquement différentes données lorsque nécessaire ; ces données sont généralement extraites d'une base de données stockée sur un serveur et envoyées au client pour être affichées avec du code (HTML et/ou JavaScript).
L'avantage le plus significatif du code côté serveur est sans doute qu'il permet d'adapter le contenu du site web à chaque utilisateur. Les sites dynamiques peuvent mettre en évidence du contenu pertinent en fonction des préférences et des habitudes de l'utilisateur. Il peut également faciliter l'utililsation des sites web en stockant des données, des informations personnelles — par exemple donner la possibilité d'enregistrer une carte de crédit pour les achats suivants.
Cela peut même permettre une interaction avec les utilisateurs du site, en envoyant des notifications et mises à jour par email ou via d'autres canaux. Toutes ces capacités rendent possible un engagement plus important avec l'utilisateur.
Dans le monde moderne du développement web, apprendre le développement côté serveur est fortement recommandé.
Qu'est-ce que la programmation côté serveur?
Les navigateurs web communiquent avec les serveurs web en utilisant le protocole HTTP (HyperText Transfer Protocol). Quand vous cliquez sur un lien dans une page web, envoyez un formulaire, ou encore lancez une recherche, une requête HTTP est envoyée du navigateur au serveur cible.
Une requête inclut une URL pour identifier la ressource demandée, une méthode pour définir l'action désirée (comme GET pour obtenir, DELETE pour supprimer ou POST pour publier) et peut également inclure des informations supplémentaires encodées dans les paramètres de l'URL (des paires clés/valeurs envoyées via une chaîne de recherche — query string en anglais), les données POST (données envoyées par la méthode HTTP POST), ou les cookies associés.
Les serveurs web attendent des requêtes du client, les traitent quand elles arrivent, et répondent au navigateur web avec une réponse HTTP. La réponse contient un statut qui indique si la requête a pu être traitée avec succès ou non (exemple "HTTP/1.1 200 OK" pour indiquer le succès).
Le corps de la réponse, si la requête réussit, contient alors la ressource demandée (comme une page HTML, une image, etc...), que le navigateur web peut alors afficher.
Sites statiques
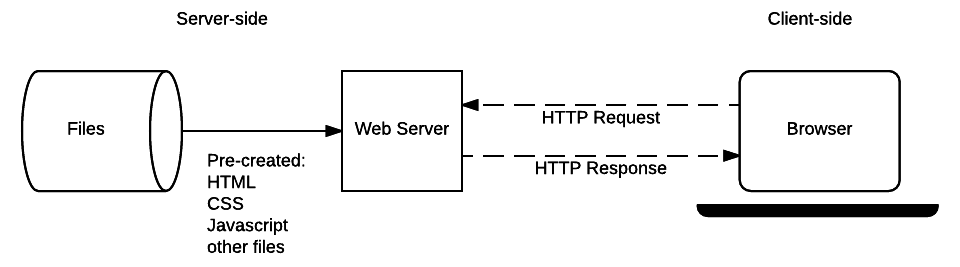
Le diagramme ci-dessous montre l'architecture d'un serveur web basique pour un site statique (un site statique est un site qui renvoie du contenu codé en dur, c'est à dire le contenu d'un fichier, quand une ressource donnée est demandée). Quand un utilisateur veut naviguer sur une page, le navigateur envoie une requête HTTP "GET" spécifiant son URL.
Le serveur récupère le document demandé du système de fichiers et retourne une réponse HTTP contenant le document et le statut de la réponse (habituellement, 200 OK). Si le fichier ne peut pas être recupéré pour une raison x ou y, le statut d'erreur est retourné (voir réponses d'erreur client et réponse d'erreur serveur).
Sites dynamiques
Un site web dynamique, quant à lui, est un site dont une partie des réponses sont générées dynamiquement, à la demande. Sur les sites dynamiques, les pages HTML sont normalement crées en insérant des données d'une base de données dans des espaces réservés à l'intérieur de templates HTML (c'est une manière beaucoup plus efficace que des fichiers statiques pour stocker de grandes quantités de contenu).
Un site dynamique peut retourner des données différentes pour une URL, en se basant sur les informations fournies par l'utilisateur ou les préférences stockées et peut effectuer des opérations avant de retourner la réponse.
La plupart du code pour maintenir un site web dynamique doit s'exécuter sur le serveur. La création de ce code est ce qu'on appelle la "programmation côté serveur" (ou parfois "codage back-end").
Le diagramme ci-dessous montre une architecture simple pour un site web dynamique. Comme dans le diagramme précédent, les navigateurs envoient des requêtes HTTP au serveur, qui les traite et retourne les réponses HTTP appropriées.
Les requêtes pour les ressources statiques sont toujours gérées de la même manière que pour les sites statiques (les ressources statiques sont tous les fichiers qui ne changent pas —typiquement : CSS, JavaScript, Images, fichiers PDF etc).
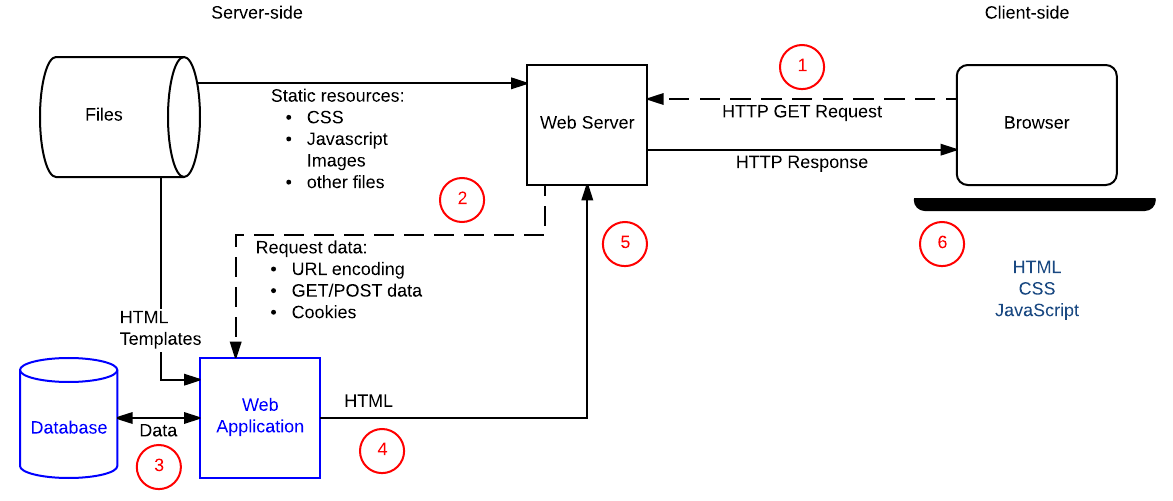
Les requêtes pour les ressources dynamiques, elles, sont transmises (2) au code côté serveur (indiqué dans le diagramme comme Web Application). Le serveur interprète la requête, lit les informations correspondantes dans la base de données (3), combine les données récupérées avec les templates HTML (4), et renvoie la réponse avec le HTML généré (5,6).
La programmation côté serveur c'est pareil que côté client?
Voyons maintenant le code impliqué dans la programmation côté serveur et côté client. Dans chaque cas, le code est significativement différent :
- Ils ont des objectifs et des préoccupations différents.
- Ils n'utilisent généralement pas les mêmes langages de programmation (exception faite de JavaScript, qui peut être utilisé côté serveur et côté client).
- Ils s'exécutent dans des environnements différents du système d'exploitation.
Le code exécuté par le navigateur est connu sous le nom de code côté client (ou front-end) et se préoccupe principalement de l'apparence et du comportement des pages web affichées. Cela inclut sélectionner et styliser les composants de l'interface utilisateur, créer la mise en page, la navigation, valider les formulaires, etc. D'un autre côté, la programmation côté serveur implique de définir le contenu retourné au navigateur en réponse aux requêtes. Le code côté serveur gère des tâches telles que la validation des données envoyées, l'utilisation des bases de données pour stocker et récupérer des données et l'envoi de données générées au client tel qu'attendu.
Le code client est écrit en HTML, CSS, et JavaScript — il est exécuté dans un navigateur web et a peu ou pas accès au système d'exploitation de l'utilisateur (inclut un accès limité au système de fichiers).
Les développeurs web ne peuvent pas contrôler quel navigateur est utilisé par l'utilisateur pour voir le site web — or les navigateurs fournissent des niveaux de compatibilité inconsistants quant aux fonctionnalités du code côté client, et une partie du challenge de la programmation côté client consiste à gérer les différences de support des navigateurs.
Le code côté serveur peut être écrit dans nombre de langages de programmation — les langages les plus populaires pour la programmation web côté serveur sont en autres PHP, Python, Ruby, C#, et NodeJS(JavaScript). Le code côté serveur a plein accès au système d'exploitation du serveur et le développeur est libre de choisir le langage (et la version) qu'il veut utiliser.
Typiquement, les développeurs écrivent leur code en utilisant des frameworks web. Les frameworks web sont des ensembles de fonctions, objets, règles et autres constructions de code conçus pour résoudre des problèmes courants, accélérer le développement et simplifier les différents types de tâches rencontrées dans un domaine particulier.
Encore une fois, bien que le code côté client et côté serveur utilisent des frameworks, les domaines d'application sont très différents et par conséquent les frameworks aussi. Les frameworks web côté client simplifient les tâches de mise en page et de présentation tandis que les frameworks web côté serveur fournissent des fonctionnalités "courantes" que vous auriez probablement à implémenter vous-même autrement (comme le support des sessions, des utilisateurs et de l'authentification, l'accès à la base de données, les bibliothèques de templates, etc.).
Note : Les frameworks côté client sont souvent utilisés pour accélérer le développement du code côté client, mais vous pouvez également choisir d'écrire tout le code à la main ; en vérité, écrire votre code à la main peut être plus rapide et plus efficace si vous n'avez besoin que d'une petite interface web très simple.
En revanche, vous ne penseriez presque jamais à écrire les composants côté serveur d'une application web sans framework — implémenter des fonctionnalités vitales comme un serveur HTTP est très difficile à faire à partir de rien, comme disons en Python, alors que les frameworks web Python comme Django le fournissent tout prêt à l'emploi, accompagné d'autres outils très utiles.
Que peut-on faire côté serveur?
La programmation côté serveur est très utile parce qu'elle nous permet de délivrer efficacement de l'information taillée sur mesure pour l'utilisateur et ainsi créer une bien meilleure expérience utilisateur.
Des compagnies comme Amazon utilisent la programmation côté serveur pour construire la recherche de produits, faire des suggestions de produit ciblées sur les préférences du client et ses habitudes d'achat, simplifier les achats, etc.
Les banques l'utilisent pour stocker les informations du compte ainsi que faire des transactions et n'autoriser à les consulter que les utilisateurs reconnus. D'autres services comme Facebook, Twitter, Instagram, et Wikipédia utilisent la programmation côté serveur pour mettre en avant, partager et contrôler l'accès au contenu.
Les utilisations les plus courantes et les plus bénéfiques de la programmation côté serveur sont listées ci-dessous. Vous verrez qu'il y a quelques recoupements :
Stockage et distribution de l'information plus efficaces
Imaginez combien de produits sont disponibles sur Amazon et combien de posts ont été écrits sur Facebook. Créer une page statique distincte pour chaque produit ou article serait totalement impossible.
La programmation côté serveur nous permet plutôt de stocker l'information dans une base de données et de construire et retourner dynamiquement le HTML ainsi que d'autres types de fichiers (comme les PDF, images, etc.). Il est également possible de simplement retourner des données (JSON, XML, etc.) pour les afficher avec des frameworks côté client (cela réduit la charge de travail du serveur et la quantité de données qui doit être retournée).
Le serveur ne se limite pas à l'envoi d'informations à partir de bases de données, il peut retourner le résultat d'autres outils logiciels, ou les données de services de communication. Le contenu peut même être ciblé pour le type d'appareil client qui le reçoit.
Comme les informations se trouvent dans une base de données, elles peuvent également être partagées et mises à jour plus facilement avec d'autres systèmes (par exemple, quand des produits sont vendus en ligne ou dans un magasin, le magasin peut mettre à jour son inventaire).
Note : Votre imagination n'a pas à travailler dur pour voir les bénéfices du code côté serveur pour le stockage et distribution de l'information:
- Allez sur Amazon ou tout autre site e-commerce.
- Cherchez un certain nombre de mot-clés et remarquez que la structure de la page de change pas, même si les résultats oui.
- Ouvrez deux ou trois produits. Remarquez que la structure et la disposition de la page sont identiques, mais que le contenu pour les différents produits a été extrait de la base de données.
Pour un terme de recherche courant ("poisson", disons) vous pouvez voir littéralement des millions de valeurs retournées. Utiliser une base de données permet à ces données d'être stockées et partagées efficacement, et permet de contrôler la présentation de l'information à partir d'un seul endroit.
Expérience utilisateur personnalisée
Les serveurs peuvent stocker et utiliser des informations sur les clients pour fournir une expérience utilisateur personnalisée. Par exemple, beaucoup de sites proposent d'enregistrer une carte de crédit pour que les détails n'aient pas à être saisis de nouveau. Des sites comme Google Maps peuvent utiliser les emplacement enregistrés ou l'emplacement en cours pour fournir des informations d'itinéraire et chercher ou utiliser l'historique des voyages précédents pour trouver des boutiques locales dans les résultats de recherche.
Une analyse plus approfondie des habitudes des utilisateurs peut être utilisée pour anticiper leurs intérêts et personnaliser les réponses ou les notifications du serveur, par exemple pour fournir une liste des lieux précédemment visités ou les plus populaires que vous pourriez vouloir chercher sur la carte.
Note : Google Maps sauvegarde vos recherches et votre historique de visites. Les emplacement fréquemment visités ou fréquemment recherchés sont plus mis en avant que les autres.
Les résultats de recherche Google sont optimisés en fonction des recherches précédentes.
- Allez sur Google.
- Recherchez "football".
- Maintenant tapez "favoris" dans la barre de recherche et regardez les prédictions de recherche de l'autocomplete.
Coïncidence ? Nada!
Accès contrôlé au contenu
La programmation côté serveur permet aux sites de restreindre l'accès aux utilisateurs autorisés et de ne servir que les informations qu'un utilisateur à la permission de voir.
Quelques exemples du monde réel incluent :
- Les réseaux sociaux comme Facebook permettent aux utilisateurs de contrôler entièrement leurs propres données, mais permettent seulement à leurs amis de les voir ou des les commenter. L'utilisateur détermine qui peut voir ses données, et par extension, dans le flux de qui elles apparaissent — l'autorisation est une partie centrale de l'expérience utilisateur !
- Le site sur lequel vous êtes en ce moment même contrôle l'accès au contenu : les articles sont visibles à tout le monde, mais seuls les utilisateurs identifiés peuvent éditer le contenu. Essayez de cliquer sur le bouton Modifier en haut de cette page — si vous êtes identifié, vous verrez la vue d'édition ; sinon, vous serez redirigé vers la page d'inscription.
Note : Il existe de nombreux autres exemples où l'accès au contenu est contrôlé. Par exemple, que voyez-vous si vous allez sur le site en ligne de votre banque ? Connectez-vous à votre compte — quelles autres informations pouvez-vous voir et modifier ? Quelles informations pouvez-vous voir que seule la banque peut changer ?
Stocker les informations de session/d'état
La programmation côté serveur permet aux développeurs d'utiliser des sessions — en gros, un mécanisme qui permet au serveur de stocker des informations sur l'utilisation en cours d'un site et d'envoyer des réponses différentes selon cette information.
Cela permet, par exemple, à un site de savoir qu'un utilisateur s'est déjà identifié et afficher des messages qui lui sont destinés, d'afficher son historique de commande, ou peut-être encore, dans le cas d'un jeu, lui permettre de reprendre là où il en est resté.
Note : Visitez le site d'un journal qui a une offre d'abonnement et ouvrez des pages (par exemple The Age). Si vous continuez à visiter le site quelques heures/jours, éventuellement, vous commencerez à être redirigé vers des pages expliquant comment vous abonner, et vous ne pourrez plus accéder aux articles. Cette information est un exemple de session stockée dans des cookies.
Notifications et communication
Les serveurs peuvent envoyer des notifications générales ou personnalisées à l'utilisateur via le site web lui-même ou par email, SMS, messagerie instantannée, conversations vidéo ou autres services de communication.
Quelques exemples incluent :
- Facebook et Twitter envoient des emails et SMS pour notifier des nouvelles communications.
- Amazon envoie régulièrement des emails qui suggèrent des produits similaires à ceux que vous avez déjà acheté ou vu, par lesquels vous pourriez être intéressé.
- Un serveur web peut envoyer des messages d'alerte aux administrateurs du site pour les prévenir en cas de mémoire insuffisante sur le serveur ou d'activité suspecte de l'utilisateur.
Note : Le type de notification le plus courant est la "confirmation d'inscription". Choisissez presque n'importe quel site qui vous intéresse (Google, Amazon, Instagram, etc.) et créez un nouveau compte en utilisant votre adresse email. Vous recevrez rapidement un email qui confirme votre inscription, ou qui exige une confirmation pour activer votre compte.
Analyse des données
Un site web peut collecter beaucoup de données sur les utilisateurs : ce qu'ils cherchent, ce qu'ils achètent, ce qu'ils recommandent, combien de temps ils restent sur chaque page. La programmation côté serveur peut être utilisée pour affiner les réponses en fonction de l'analyse de ces données.
Par exemple, Amazon et Google font tous deux de la publicité pour des produits en se basant sur les recherches précédentes, sur les achats que vous avez faits.
Note : Si vous êtes un utilisateur de Facebook, allez sur votre flux principal et regardez les posts. Notez que certains posts ne sont pas classés par ordre numérique — en particulier, les posts qui ont le plus de "likes" sont souvent placés plus haut dans la liste que les posts plus récents.
Observez également quels types de publicités vous voyez — vous pourrez voir des publicités pour des choses que vous avez regardé sur d'autres sites. L'algorithme de Facebook pour mettre en avant du contenu et faire de la publicité est un peu un mystérieux, mais il est clair qu'il prend en compte vos likes et ce que vous avez l'habitude de regarder !
Sommaire
Félicitations, vous avez atteint la fin du premier article sur la programmation côté serveur.
Vous avez maintenant appris que le code côté serveur est exécuté sur un serveur web et que son rôle principal est de contrôler quelle information est envoyée à l'utilisateur (tandis que le code côté client gère principalement la structure et la présentation des données pour l'utilisateur).
Vous devez également comprendre que c'est utile pour créer des sites web qui délivrent de l'information efficacement, adaptée à chaque utilisateur et avoir une bonne idée de quelques choses que vous seriez capable de faire quand vous serez programmeur back-end.
Finalement, vous devez comprendre que le code côté serveur peut être écrit dans de nombreux langages de programmation et que l'on peut utiliser des frameworks web pour rendre ce processus plus facile.
Dans un futur article, nous vous aiderons à choisir le framework le plus adapté pour la création d'un premier site. Ensuite, nous vous présenterons les principales interactions client-serveur plus en détails.