Remplir la page: comment fonctionnent les navigateurs
Les utilisateurs veulent des expériences Web avec un contenu rapide à charger et une interaction fluide. Par conséquent, un développeur doit s'efforcer d'atteindre ces deux objectifs.
Pour comprendre comment améliorer les performances et les performances perçues, il est utile de comprendre le fonctionnement du navigateur.
Vue générale
Les sites rapides offrent une meilleure expérience utilisateur. Les utilisateurs veulent et s'attendent à des expériences Web avec un contenu rapide à charger et à interagir avec fluidité.
La compréhension des problèmes liés 1) à la latence et 2) les problèmes liés au fait que, dans la plupart des cas, les navigateurs fonctionné à un seul thread. Cela sont deux problèmes majeurs dans les performances Web.
La latence est notre principale menace à surmonter pour assurer une charge rapide. Pour être rapides à charger, les objectifs des développeurs incluent l'envoi des informations demandées aussi rapidement que possible, ou du moins, cela semble super rapide. La latence du réseau est le temps nécessaire pour transmettre des octets par liaison radio aux ordinateurs. La performance Web est ce que nous devons faire pour que le chargement de la page se fasse le plus rapidement possible.
Pour la plupart, les navigateurs sont considérés comme un seul thread. Pour que les interactions se déroulent sans heurt, l'objectif du développeur est d'assurer des interactions de site performantes, du défilement en douceur à la réactivité au touchers Le temps de rendu est essentiel, car il permet de s'assurer que le fil principal peut effectuer tout le travail que nous lui faisons, tout en restant disponible pour gérer les interactions de l'utilisateur.
Les performances Web peuvent être améliorées en comprenant le caractère mono-thread du navigateur et en minimisant les responsabilités du thread principal, lorsque cela est possible et approprié, pour assurer un rendu fluide et des réponses aux interactions immédiates.
Navigation
La navigation est la première étape du chargement d'une page Web. Cela se produit chaque fois qu'un utilisateur demande une page en saisissant une URL dans la barre d'adresse, en cliquant sur un lien, en soumettant un formulaire, ainsi que d'autres actions.
L'un des objectifs de la performance Web est de minimiser le temps de navigation. Dans des conditions idéales, cela ne prend généralement pas trop de temps, mais la latence et la bande passante sont des ennemis qui peuvent causer des retards.
Recherche DNS
La première étape de la navigation vers une page Web consiste à rechercher l'emplacement des actifs de cette page. Si vous accédez à https://example.com, la page HTML se trouve sur le serveur avec l'adresse IP de 93.184.216.34. Si vous n'avez jamais visité ce site, une recherche DNS doit être effectuée.
Votre navigateur demande une recherche DNS, qui est éventuellement effectuée par un serveur de noms, qui lui-même répond avec une adresse IP. Après cette demande initiale, l'adresse IP sera probablement mise en cache pendant un certain temps, ce qui accélérera les demandes suivantes en récupérant l'adresse IP du cache au lieu de contacter à nouveau un serveur de noms.<
Les recherches DNS ne doivent généralement être effectuées qu'une fois par nom d'hôte pour le chargement d'une page. Cependant, des recherches DNS doivent être effectuées pour chaque nom d'hôte unique référencé par la page demandée.
Si vos fichier de police, images, scripts, publicites/annonces et métriques ont tous un nom d'hôte différent, une recherche DNS devra être effectuée pour chacun d'eux.
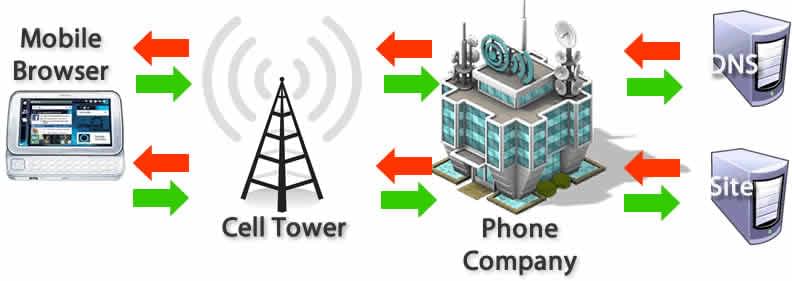
Cela peut être problématique pour les performances, en particulier sur les réseaux mobiles. Lorsqu'un utilisateur est sur un réseau mobile, chaque recherche DNS doit aller du téléphone à la tour cellulaire pour atteindre un serveur DNS faisant autorité. La distance entre un téléphone, une tour de téléphonie cellulaire et le serveur de noms peut ajouter une latence significative.
TCP Handshake
Une fois que l'adresse IP est connue, le navigateur établit une connexion avec le serveur via un négociation de liaison TCP à trois voies. TCe mécanisme est conçu pour que deux entités essayant de communiquer, dans ce cas le navigateur et le serveur Web, puissent négocier les paramètres de la connexion de socket TCP sur le réseau avant de transmettre des données, souvent sur HTTPS.
La technique de négociation à trois voies de TCP est souvent appelée "SYN-SYN-ACK", ou plus précisément SYN, SYN-ACK, ACK, car trois messages sont transmis par TCP pour négocier et démarrer une session TCP entre deux ordinateurs. Oui, cela signifie trois messages supplémentaires entre chaque serveur et la demande doit encore être faite.
Negotiation TLS
Pour les connexions sécurisées établies via HTTPS, une autre "liaison" est requise. Cette négociation, ou plutôt la négociation TLS, détermine quel chiffrement sera utilisé pour chiffrer la communication, vérifie le serveur et établit qu'une connexion sécurisée est en place avant de commencer le transfert effectif des données. Cela nécessite encore trois allers-retours vers le serveur avant que la demande de contenu ne soit réellement envoyée.
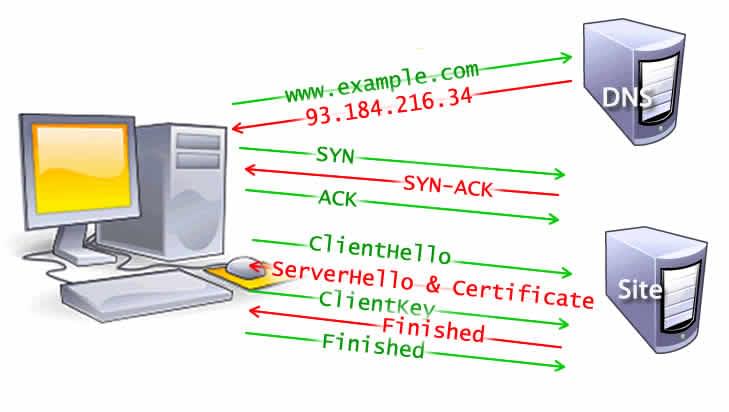
Bien que sécuriser la connexion ajoute du temps au chargement de la page, une connexion sécurisée vaut la dépense en latence, car les données transmises entre le navigateur et le serveur Web ne peuvent pas être déchiffrées par un tiers.
Après les 8 allers-retours, le navigateur est enfin en mesure de faire la demande.
Response
Une fois la connexion établie avec un serveur Web établie, le navigateur envoie une demande HTTP GET initiale au nom de l'utilisateur, qui pour les sites Web est le plus souvent un fichier HTML. Dès que le serveur reçoit la demande, il répond avec les en-têtes de réponse pertinents et le contenu du code HTML.
<!doctype html>
<html lang="fr">
<head>
<meta charset="UTF-8" />
<title>Une page simple</title>
<link rel="stylesheet" src="styles.css" />
<script src="monscript.js"></script>
</head>
<body>
<h1 class="heading">Ma Page</h1>
<p>Un paragraph avec in <a href="https://example.com/about">lien</a></p>
<div>
<img src="monImage.jpg" alt="description de l'image" />
</div>
<script src="unautrescript.js"></script>
</body>
</html>
La réponse pour cette demande initiale contient le premier octet de données reçu. Time to First Byte (en-US) (TTFB) est le temps écoulé entre le moment où l'utilisateur a fait la demande (disons en cliquant sur un lien) et la réception du premier paquet HTML. Le premier bloc de contenu est généralement constitué de 14 Kb de données.
Dans notre exemple ci-dessus, la demande est nettement inférieure à 14 Kb, mais les ressources liées ne sont pas demandées tant que le navigateur n'a pas rencontré les liens lors de l'analyse, décrit ci-dessous.
TCP Slow Start / 14kb rule
Le premier paquet de réponse sera de 14 Kb. Cela fait partie de TCP slow start, un algorithme qui équilibre la vitesse d'une connexion réseau. Le démarrage lent augmente progressivement la quantité de données transmises jusqu'à ce que la bande passante maximale du réseau puisse être déterminée.
Avec un TCP slow start, après la réception du paquet initial, le serveur double la taille du paquet suivant, pour atteindre environ 28 Kb. La taille des paquets suivants augmente jusqu'à atteindre un seuil prédéterminé ou jusqu'à ce qu'un encombrement se produise.

Si vous avez déjà entendu parler de la règle de 14 Kb pour le chargement de page initial, c'est le démarrage lent de TCP qui explique pourquoi la réponse initiale est de 14 Ko et pourquoi l'optimisation des performances Web appelle à l'optimisation de la focalisation avec cette réponse initiale à l'esprit. Le démarrage lent TCP augmente progressivement les vitesses de transmission en fonction des capacités du réseau afin d'éviter les encombrements.
Contrôle congestion
Lorsque le serveur envoie des données sous forme de paquets TCP, le client de l'utilisateur confirme la livraison en renvoyant des accusés de réception, ou ACK. La connexion a une capacité limitée en fonction des conditions matérielles et du réseau. Si le serveur envoie trop de paquets trop rapidement, ils seront supprimés. Sens, il n'y aura pas de reconnaissance. Le serveur l'enregistre comme ACK manquant. Les algorithmes de contrôle d'encombrement utilisent ce flux de paquets envoyés et d'accusés de réception pour déterminer un débit d'envoi.
Parsing
Une fois que le navigateur a reçu le premier bloc de données, il peut commencer à analyser les informations reçues. L'analyse, our parsing, est l'étape par laquelle le navigateur prend pour transformer les données qu'il reçoit sur le réseau en DOM et CSSOM, qui est utilisé par le moteur de rendu pour peindre une page à l'écran.
Le DOM est la représentation interne du balisage pour le navigateur. Le DOM est également exposé et peut être manipulé via diverses API en JavaScript.
Même si le code HTML de la page de demande est plus volumineux que le paquet initial de 14 Kb, le navigateur commencera à analyser et à tenter de restituer une expérience en fonction des données dont il dispose. C'est pourquoi il est important pour l'optimisation des performances Web d'inclure tout ce dont le navigateur a besoin pour commencer le rendu d'une page, ou du moins d'un modèle de page - les CSS et HTML nécessaires au premier rendu - dans les 14 premiers kilo-octets. Mais avant que tout ne soit rendu à l'écran, le HTML, CSS et JavaScript doivent être analysés.
Building the DOM tree
Nous décrivons cinq étapes dans le chemin de rendu critique, ou "critical rendering path (en-US)".
La première étape consiste à traiter le balisage HTML et à créer l'arborescence DOM. L'analyse HTML implique la création de jetons, tokenization, et la construction du DOM tree. Les jetons HTML incluent les balises de début et de fin, ainsi que les noms et les valeurs des attributs. Si le document est bien formé, son analyse est simple et rapide. L'analyseur analyse les entrées sous forme de jetons dans le document, créant ainsi le document tree.
Le DOM tree décrit le contenu du document. L'élément <html> est la première balise et le premier nœud racine de du document tree. L'arbre reflète les relations et les hiérarchies entre différentes balises. Les balises imbriquées dans d'autres balises sont des nœuds enfants. Plus le nombre de nœuds DOM est élevé, le plus de temps ca prends pour construire le DOM tree.
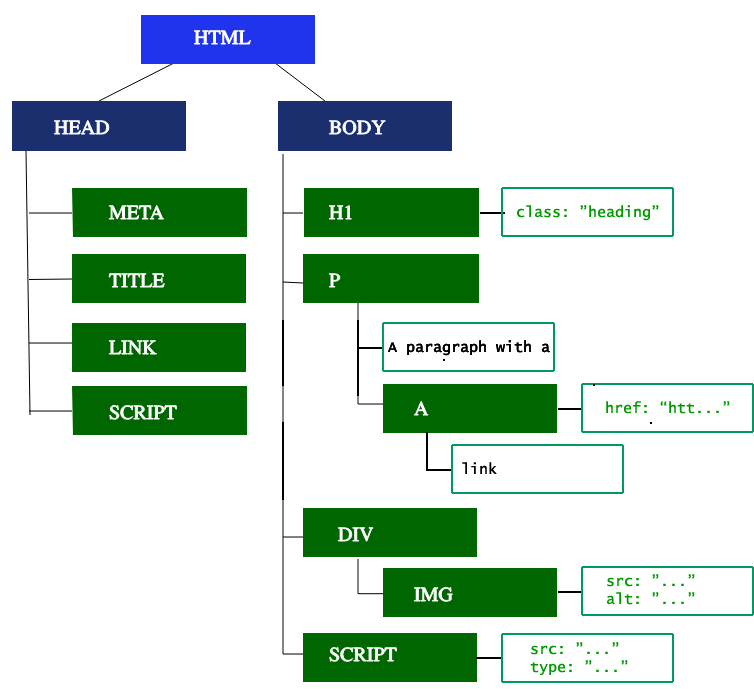
Lorsque l'analyseur trouve des ressources non bloquantes, telles qu'une image, le navigateur demande ces ressources et poursuit l'analyse. L'analyse peut continuer lorsqu'un fichier CSS est rencontré, mais les balises <script>, en particulier celles sans attribut async ou defer, bloquent le rendu et mettent en pause l'analyse du code HTML. Bien que le scanner de précharge du navigateur accélère ce processus, le nombre excessif de scripts peut toujours constituer un goulot d'étranglement important.
Preload scanner
Pendant que le navigateur construit le DOM tree, ce processus occupe le thread principal. Dans ce cas, le scanner de préchargement analysera le contenu disponible et demandera des ressources hautement prioritaires telles que CSS, JavaScript et les polices. Grâce à l'analyseur de précharge, il n'est pas nécessaire d'attendre que l'analyseur trouve une référence à une ressource externe pour la demander. Il récupérera les ressources en arrière-plan, de sorte qu'au moment où l'analyseur HTML principal atteindra les actifs demandés, il se peut qu'ils soient déjà en vol ou aient été téléchargés. Les optimisations fournies par le scanner de précharge permettent de réduire les blocages.
<link rel="stylesheet" src="styles.css" />
<script src="myscript.js" async></script>
<img src="monImage.jpg" alt="description de l'image" />
<script src="unautrescript.js" async></script>
Dans cet exemple, alors que le fil principal analyse HTML et CSS, le scanner de préchargement trouvera les scripts et l'image, et commencera également à les télécharger. Pour vous assurer que le script ne bloque pas le processus, ajoutez l'attribut async ou defer si l'analyse et l'exécution de JavaScript ne sont pas importantes.
L'attente pour obtenir CSS ne bloque pas l'analyse ou le téléchargement HTML, mais bloque JavaScript, car JavaScript est souvent utilisé pour rechercher l'impact des propriétés CSS sur les éléments.
Construction du CSSOM
La deuxième étape du chemin de rendu critique est le traitement de CSS et la construction du CSSOM. Le modèle d'objet CSS est similaire au DOM. Les DOM et CSSOM sont deux arbres. Ce sont des structures de données indépendantes. Le navigateur convertit les règles CSS en une carte de styles qu'il peut comprendre et utiliser. Le navigateur passe en revue chaque ensemble de règles de la feuille de style CSS, créant ainsi une arbre de noeuds avec des relations parent, enfant et sœurs basées sur les sélecteurs CSS.
Comme avec HTML, le navigateur doit convertir les règles CSS reçues en quelque chose avec lequel il peut travailler. Par conséquent, il répète le processus HTML-à-object, mais pour le CSS.
L'arbre CSSOM comprend les styles du stylesheet de l'agent utilisateur. Le navigateur commence par la règle la plus générale applicable à un nœud et affine de manière récursive les styles calculés en appliquant des règles plus spécifiques. En d'autres termes, il cascade les valeurs de propriété.
La construction du CSSOM est très, très rapide et n'est pas affiché dans une couleur unique dans les outils de développement actuels. Le "Style recalculé" dans les outils de développement indique le temps total nécessaire à l'analyse CSS, à la construction du CSSOM et au calcul récursif des styles calculés. En ce qui concerne l'optimisation des performances Web, l'effet de l'effort d'optimisation de la construction CSSOM crée sont minimes, car le temps total nécessaire pour créer le CSSOM est généralement inférieur au temps requis pour une recherche DNS.
Autres Processus
Compilation JavaScript
Lors de l'analyse du CSS et de la création du CSSOM, d'autres ressources, notamment des fichiers JavaScript, sont en cours de téléchargement (grâce au scanner de préchargement). JavaScript est interprété, compilé, analysé et exécuté. Les scripts sont analysés dans des arbres à syntaxe abstraite. Certains moteurs de navigateur utilisent le Arbre de syntaxe abstraite et le transmettent à un interpréteur, générant le code binaire exécuté sur le thread principal. Ceci est connu sous le nom de compilation JavaScript.
Construire l'arbre d'accessibilité
Le navigateur crée également une arbre d'accessibilité que les périphériques d'assistance utilisent pour analyser et interpréter le contenu. Le modèle d'objet d'accessibilité (AOM) est comme une version sémantique du DOM. Le navigateur met à jour l'arbre d'accessibilité lorsque le DOM est mis à jour. L'arbre d'accessibilité n'est pas modifiable par les technologies d'assistance elles-mêmes.
Jusqu'à la construction de l'AOM, le contenu n'est pas accessible aux lecteurs d'écran.
Rendre
Les étapes de rendu incluent le style, la mise en page, la peinture et, dans certains cas, la composition. Les arbres CSSOM et DOM créés à l'étape d'analyse sont combinés en un arbre de rendu qui est ensuite utilisé pour calculer la mise en page de chaque élément visible, qui est ensuite peint à l'écran. Dans certains cas, le contenu peut être promu dans ses propres couches et composé, ce qui améliore les performances en peignant des parties de l'écran sur le GPU au lieu du CPU, libérant ainsi le thread principal.
Style
La troisième étape du chemin de rendu critique consiste à combiner le DOM et CSSOM dans une arborescence de rendu. La construction de l'arbre de style calculé ou de l'arbre de rendu commence à la racine de l'arborescence DOM, en traversant chaque nœud visible.
Les balises qui ne vont pas être affichées, telles que <head> et ses enfants, ainsi que tous les nœuds avec display: none, tel que le script { display: none;} vous trouverez dans les feuilles de style de l'agent utilisateur, ne sont pas inclus dans l'arborescence de rendu car ils n'apparaîtront pas dans la sortie rendue. Les nœuds avec visibility: hidden appliqué sont inclus dans l'arborescence de rendu, car ils occupent de l'espace. Comme nous n'avons donné aucune directive pour remplacer la valeur par défaut de l'agent utilisateur, le noeud de script de notre exemple de code ci-dessus ne sera pas inclus dans l'arbre de rendu.
Les règles CSSOM sont appliquées à chaque nœud visible. L'arborescence de rendu contient tous les nœuds visibles avec le contenu et les styles calculés - en faisant correspondre tous les styles pertinents à chaque nœud visible du DOM tree et en déterminant, en fonction de la cascade CSS, les styles calculés pour chaque nœud.
Disposition
La quatrième étape du chemin de rendu critique consiste à exécuter la disposition sur l'arbre de rendu pour calculer la géométrie de chaque noeud.
La disposition est le processus par lequel la largeur, la hauteur et l'emplacement de tous les noeuds de l'arbre de rendu sont déterminés, ainsi que la détermination de la taille et de la position de chaque objet sur la page. La redistribution correspond à toute détermination ultérieure de la taille et de la position d'une partie de la page ou du document dans son ensemble.
Une fois que l'arborescence de rendu est construite, la mise en page commence. L'arbre de rendu identifiait les nœuds affichés (même s'ils étaient invisibles) avec leurs styles calculés, mais pas les dimensions ou l'emplacement de chaque nœud. Pour déterminer la taille et l'emplacement exact de chaque objet, le navigateur commence à la racine de l'arbre de rendu et le traverse.
Sur la page Web, presque tout est une boîte. Différents périphériques et différentes préférences de bureau signifient un nombre illimité de tailles de fenêtres d'affichage différentes. Au cours de cette phase, prenant en compte la taille de la fenêtre d'affichage, le navigateur détermine les dimensions de toutes les différentes boîtes à l'écran. En prenant la taille de la fenêtre comme base, la présentation commence généralement par le corps, elle présente les dimensions de tous les descendants du corps, ainsi que les propriétés du modèle de boîte de chaque élément, offrant ainsi un espace réservé aux éléments remplacés dont il ne connaît pas les dimensions: comme notre image.
La première fois que la taille et la position des nœuds sont déterminées est appelée "mise en page", ou layout. Les recalculs ultérieurs de la taille et des emplacements des noeuds sont appelés redistributions, ou reflows. Dans notre exemple, supposons que la mise en page initiale se produise avant que l'image ne soit renvoyée. Comme nous n'avons pas déclaré la taille de notre image, il y aura un reflow une fois que la taille de l'image est connue.
Peindre
La dernière étape du chemin de rendu critique consiste à peindre les nœuds individuels à l'écran, la première occurrence étant appelée la première peinture significative, ou first meaningful paint.
Lors de la phase de peinture ou de rastérisation, le navigateur convertit chaque case calculée lors de la phase de mise en page en pixels réels à l'écran. La peinture implique de dessiner chaque partie visuelle d'un élément sur l'écran, y compris le texte, les couleurs, les bordures, les ombres et les éléments remplacés, comme les boutons et les images. Le navigateur doit faire cela très rapidement.
Pour assurer un défilement et une animation fluides, tout ce qui occupe le fil principal, y compris le calcul des styles, ainsi que le redistribution et la peinture, doit nécessiter moins de 16,67ms de navigateur.
À 2048 X 1536, l'iPad a plus de 3 145 000 pixels à peindre à l'écran. C'est beaucoup de pixels qui doivent être peints très rapidement. Afin de pouvoir repeindre même plus rapidement que la peinture initiale, le dessin à l'écran est généralement divisé en plusieurs couches, ou layers. Si cela se produit, la composition est nécessaire.
La peinture peut diviser les éléments de l'arborescence en couches. La promotion du contenu en couches sur le GPU (au lieu du thread principal sur le CPU) améliore la performances de la peinture originale et chaque la performances de repeinte supplémentaire.
Il existe des propriétés et des éléments spécifiques qui instancient un calque, notamment <video> et <canvas>, ainsi que tout élément possédant les propriétés CSS d'opacité, de transformation 3D, de et de plusieurs valeur de will-change, isolation et contain. Ces nœuds seront peints sur leur propre calque, avec leurs descendants, à moins qu'un descendant ne nécessite son propre calque pour une (ou plusieurs) des raisons ci-dessus.
Les couches améliorent les performances, mais sont coûteuses en termes de gestion de la mémoire et ne doivent donc pas être utilisées de manière excessive dans les stratégies d'optimisation des performances Web.
Composition
Lorsque des sections du document sont dessinées dans différentes couches se chevauchant, la composition est nécessaire pour garantir qu'elles sont dessinées à l'écran dans le bon ordre et que le contenu est restitué correctement.
Si la page continue de charger des ressources, des retraits peuvent se produire (rappelez-vous notre exemple d'image arrivé en retard). Un reflux déclenche un repeinte et un recomposition. Si nous avions défini la taille de notre image, aucune refusion n'aurait été nécessaire, et seule la couche à repeindre serait repeinte et composée si nécessaire. Mais nous n'avons pas inclus la taille de l'image! Lorsque l'image est obtenue à partir du serveur, le processus de rendu reprend les étapes de la mise en page et redémarre à partir de là.
L'interactivité
Une fois que le fil principal est terminé, on pourrait penser que nous serions "tout prêt". Ce n'est pas nécessairement le cas. Si le chargement inclut JavaScript, correctement différé et exécuté uniquement après le déclenchement de l'événement onload, le thread principal est peut-être occupé et indisponible pour les interactions de défilement, tactiles et autres.
Time to Interactive (TTI) est la mesure du temps qu'il a fallu à cette première demande pour aboutir à la recherche DNS et à la connexion SSL lorsque la page est interactive - interactif étant le point dans le temps après le First Contentful Paint lorsque la page répond aux interactions de l'utilisateur dans un délai de 50 ms. Si le thread principal est occupé à analyser, compiler et exécuter JavaScript, il n'est pas disponible et ne peut donc pas répondre aux interactions de l'utilisateur dans les meilleurs délais (moins de 50 ms).
Dans notre exemple, l'image a peut-être été chargée rapidement, mais le fichier unautrescript.js faisait 2 MB et la connexion réseau de notre utilisateur était lente. Dans ce cas, l'utilisateur verrait la page très rapidement, mais ne pourrait pas faire défiler sans jank jusqu'à ce que le script soit téléchargé, analysé et exécuté. Ce n'est pas une bonne expérience utilisateur. Évitez d'occuper le fil principal, comme illustré dans cet exemple WebPageTest:
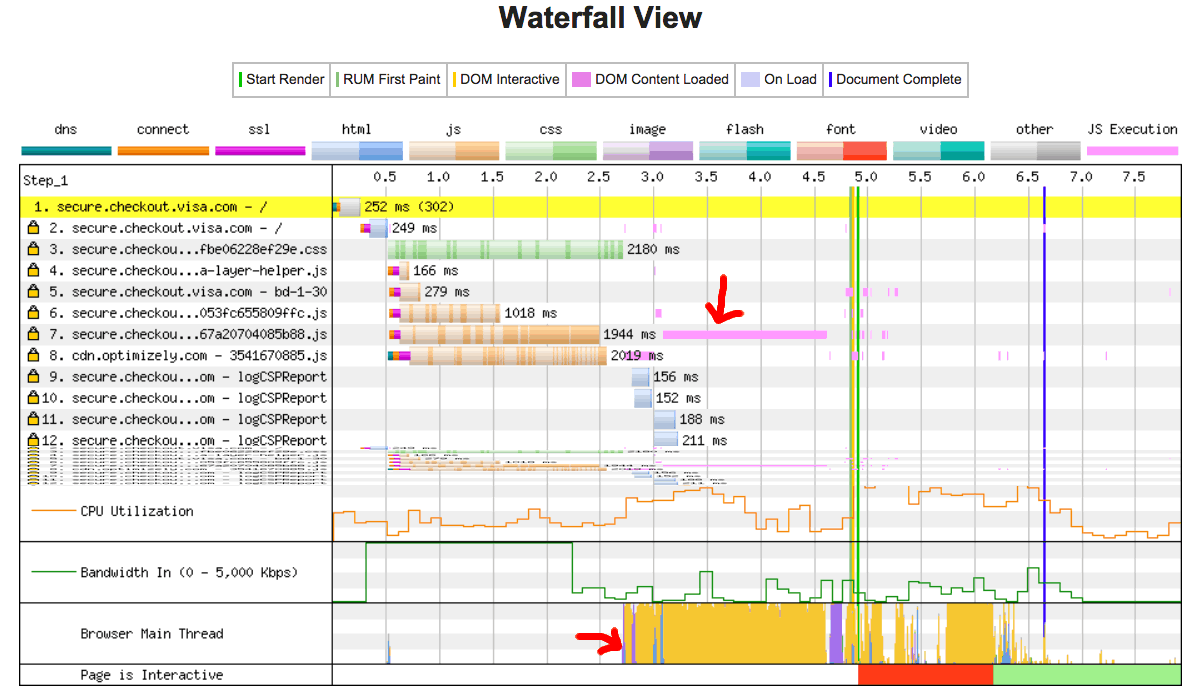
Dans cet exemple, le processus de chargement du contenu du DOM a duré plus de 1,5 seconde et le thread principal a été entièrement occupé pendant tout ce temps, ne répondant pas pour cliquer sur des événements ou sur des taps à l'écran.