Gérer les fichiers
Un site web est composé de nombreux fichiers : contenu textuel, code, feuilles de styles, contenus média, etc. Lors de la construction d'un site web, ces fichiers doivent être organisés et rangés sur votre ordinateur afin qu'ils puissent interagir les uns avec les autres et que le contenu s'affiche correctement. Une fois que c'est fait, vous pourrez alors téléverser ces fichiers sur un serveur. Gérer les fichiers aborde certains problèmes auxquels vous devez faire attention pour mettre en place une organisation judicieuse des fichiers de votre site web.
Où placer votre site web sur votre ordinateur ?
Lorsque vous travaillez sur votre site web sur votre propre ordinateur, tous les fichiers liés au site devraient être présents dans un dossier dont le contenu reflète la structure des fichiers sur le serveur. Ce dossier peut être n'importe où sur votre ordinateur, l'idéal étant qu'il soit simple à retrouver, par exemple sur votre Bureau ou dans votre dossier personnel, voire à la racine du disque dur.
- Sélectionnez un endroit où stocker vos projets de sites web. Là, créez un nouveau dossier appelé
projets-web(ou similaire). C'est l'endroit où vivront vos divers projets de sites web. - À l'intérieur de ce premier dossier, créez un autre dossier pour y enregistrer votre premier site web. Vous pouvez l'appeler
site-test(ou plus imaginatif).
Un rapide aparté sur la casse et l'espacement
Vous remarquerez tout au long de cet article que nous vous demandons de nommer les dossiers et les fichiers totalement en minuscules et sans espace. Voici la raison :
- Nombre d'ordinateurs, notamment des serveurs web, sont sensibles à la casse. Par exemple, si vous placez une image pour votre site à l'emplacement
site-test/MonImage.jpget que, dans un autre fichier, vous faites référence àsite-test/monimage.jpg, cela peut ne pas fonctionner. - Les navigateurs, les serveurs web et les différents langages de programmation ne gèrent pas tous les espaces de la même façon. Par exemple, si vous utilisez un espace dans le nom du fichier, certains systèmes considèreront que le nom du fichier correspond à celui de deux fichiers. Certains serveurs remplaceront les espaces dans le nom du fichier par « %20 » (le code de caractère pour représenter les espaces dans les URI), ce qui cassera tous vos liens. Il est préférable de séparer les mots avec des tirets, plutôt que des soulignés :
mon-fichier.htmlvs.mon_fichier.html.
La réponse la plus simple est d'utiliser le trait d'union (-) pour les noms de fichiers. Le moteur de recherche de Google traite le tiret comme un séparateur de mots, mais n'opère pas de même pour le souligné (_). Pour ces raisons, il est préférable d'écrire les noms des fichiers et dossiers en minuscules sans espaces, les mots étant séparés par des tirets, à moins d'être sûr de ce que vous faites. Cela vous permettra d'éviter certains problèmes en chemin, plus tard.
Quelle structure mettre en place pour votre site web ?
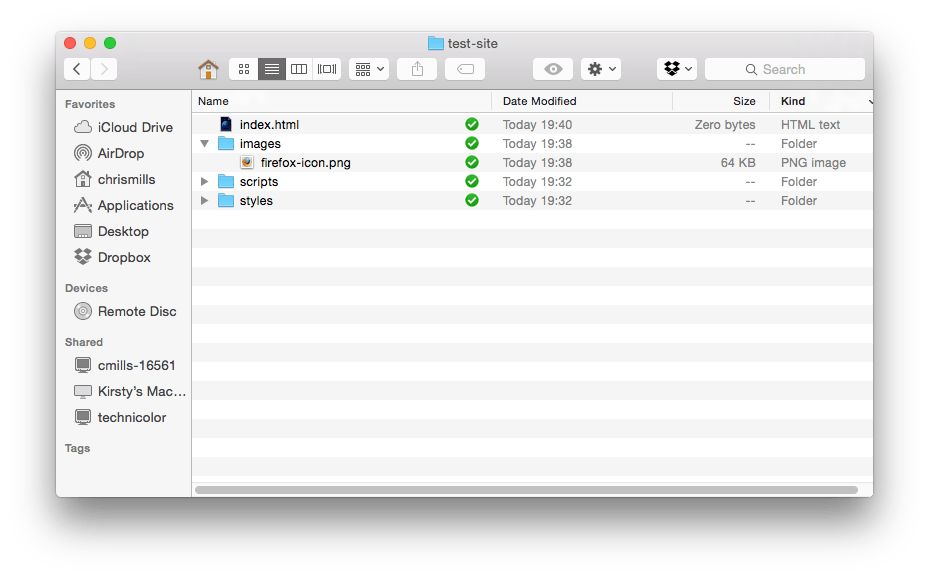
Cela dit, regardons la structure que le site de test devrait avoir. Les éléments retrouvés quasiment dans tout projet de site web sont un fichier HTML d'index, des dossiers pour les images, les scripts et les feuilles de style. Créons‑les maintenant :
index.html: ce fichier contiendra généralement le contenu de votre page d'accueil, c'est-à-dire le texte et les images que les gens verront lorsqu'ils arriveront sur votre site. Avec votre éditeur de texte, créez un fichier nomméindex.htmlpuis enregistrez‑le dans votre dossiersite-test.- un dossier
images: ce dossier contiendra toutes les images utilisées pour votre site. Créez un dossier nomméimagesdans votre dossiersite-test. - un dossier
styles: ce dossier contiendra le code des CSS utilisé pour la mise en forme du contenu (par exemple pour définir les couleurs à utiliser pour le texte et l'arrière-plan). Créez un dossier nomméstylesdans votre dossiersite-test. - un dossier
scripts: ce dossier contiendra le code JavaScript utilisé pour ajouter des fonctionnalités interactives sur votre site (par exemple, des boutons qui permettent de charger des données lorsqu'on clique dessus). Créez un dossier nomméscriptsdans votre dossiersite-test.
Note : Sur Windows, vous aurez peut être des problèmes pour voir le nom des fichiers en entier. En effet, Windows possède une option, activée par défaut : Masquer les extensions pour les types de fichiers connus. Généralement, il est possible de la désactiver en allant dans l'explorateur de fichiers, en sélectionnant Options des dossiers..., en enlevant la coche de Masquer les extensions pour les types de fichier connus puis en cliquant sur OK. Pour des informations propres à votre version de Windows, recherchez sur le Web !
Les chemins de fichiers
Pour que les fichiers puissent converser entre eux, il faut préciser le chemin pour les trouver — en résumé, la route qu'un fichier doit connaître pour situer l'autre fichier. Nous allons illustrer cela avec un peu de HTML dans index.html pour que la page affiche l'image choisie dans l'article « Quel aspect pour votre site web ? ».
- Copiez l'image précédemment choisie dans votre dossier
images. - Ouvrez le fichier
index.htmlet insérez le code suivant exactement comme indiqué. Ne vous préoccupez pas de sa signification pour le moment — nous verrons les structures plus en détail par la suite.html<!doctype html> <html> <head> <meta charset="utf-8" /> <title>Ma page de test</title> </head> <body> <img src="" alt="Mon image de test" /> </body> </html> - La ligne qui contient
<img src="" alt="Mon image de test">correspond au code HTML qui insère une image dans la page. Il faut indiquer au HTML là où l'image se trouve. Cette image est à l'intérieur du dossierimageset ce dossier se situe dans le même dossier qu'index.html. Pour parcourir l'arborescence des fichiers depuisindex.htmljusqu'à l'image, le chemin à utiliser estimages/votre‑fichier‑image. Par exemple, si l'image est nomméefirefox‑icon.png, le chemin seraimages/firefox-icon.png. - Insérez le chemin vers le fichier image dans le code HTML, entre les guillemets dans
src="". - Sauvegardez votre fichier HTML puis chargez la page dans votre navigateur (il suffit de double-cliquer sur le fichier). Vous devriez obtenir une nouvelle page web affichant l'image !

Quelques règles générales à propos des chemins de fichier :
- Pour utiliser un fichier qui est dans le même répertoire que le fichier HTML, il suffit d'utiliser le nom du fichier pour le chemin (par exemple
mon-image.jpg). - Pour faire référence à un fichier dans un sous‑répertoire, on écrira le nom du répertoire, suivi d'une barre oblique (/) suivi du nom du fichier. Par exemple :
mon-sous-repertoire/mon-image.jpg. - Pour faire référence à un fichier qui se situe dans le répertoire parent par rapport au fichier HTML, il faut écrire deux points (..). Par exemple, si votre fichier
index.htmlse situe dans un sous-dossier desite-testet quemon-image.jpgse situe à l'intérieur desite-test, vous pouvez faire référence à votre imagemon-image.jpgdepuisindex.htmlen écrivant../mon-image.jpg. - Ces différentes règles peuvent être combinées autant que nécessaire : par exemple
../sous-dossier/autre-sous-dossier/mon-image.jpg.
Pour le moment, c'est tout ce qu'il y a à savoir.
Note : Le système de fichiers Windows utilise des barres obliques inversées (backslash : « \ ») et non des barres obliques (slash : « / »), par exemple C:\windows. Cela n'intervient pas en HTML — même si vous développez votre site sur Windows, vous devez toujours utiliser des barres obliques (« / ») dans votre code..