HTTP の概要
HTTP は、 HTML 文書などのリソースを読み取るためのプロトコルです。 これはウェブにおけるデータ交換の基礎をなし、クライアントサーバープロトコルであり、リクエストは受け取り者(一般にはウェブブラウザー)が生成します。 文書全体は、テキスト、レイアウトの定義、画像、動画、スクリプトなど、取り込まれたさまざまなサブ文書から再構成されます。
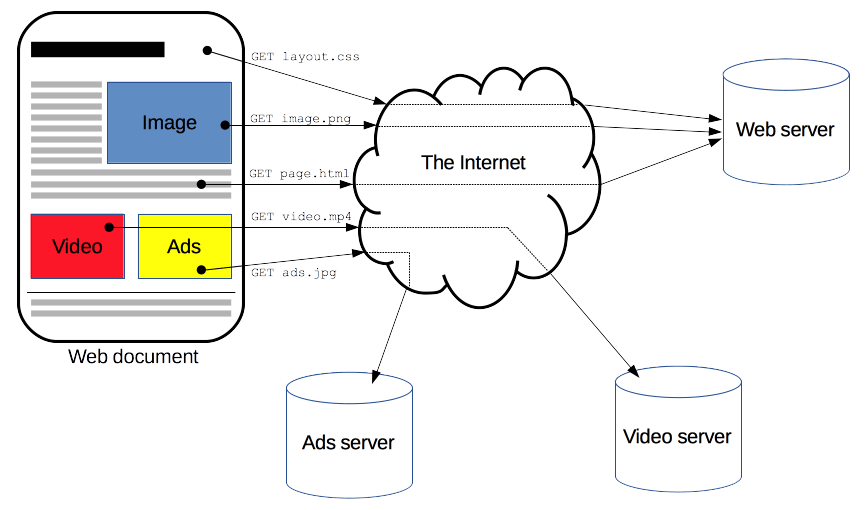
クライアントとサーバーは、(データの流れとは対照的に)個々のメッセージを交換することによって通信します。 クライアント(通常はウェブブラウザー)が送信するメッセージはリクエストと呼ばれます。また、サーバーが回答として送信するメッセージはレスポンスと呼ばれます。
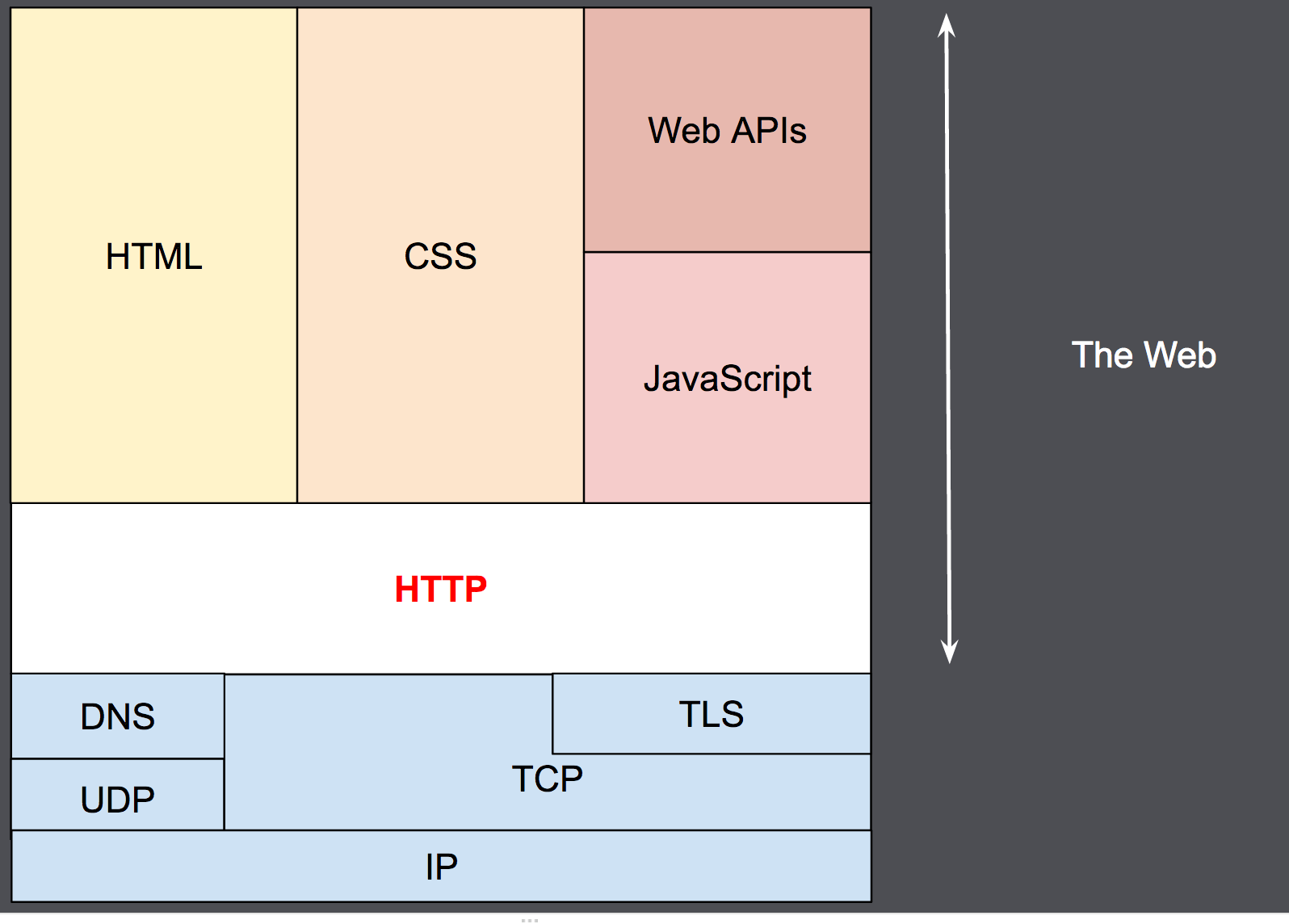 1990 年代初頭に設計された HTTP は、時間をかけて進化した拡張可能なプロトコルです。
HTTP は、 TCP または TLS (暗号化された TCP 接続)を使用して送信されるアプリケーション層のプロトコルですが、理論上は信頼性のある任意のトランスポート層プロトコルを使用できます。
HTTP は拡張性があるため、ハイパーテキスト文書だけでなく画像や動画の取り込みや、 HTML フォームの入力結果などをクライアントからサーバーへ送信することもできます。
また、リクエストに応じてウェブページを更新するために、文書の一部を取り込むこともできます。
1990 年代初頭に設計された HTTP は、時間をかけて進化した拡張可能なプロトコルです。
HTTP は、 TCP または TLS (暗号化された TCP 接続)を使用して送信されるアプリケーション層のプロトコルですが、理論上は信頼性のある任意のトランスポート層プロトコルを使用できます。
HTTP は拡張性があるため、ハイパーテキスト文書だけでなく画像や動画の取り込みや、 HTML フォームの入力結果などをクライアントからサーバーへ送信することもできます。
また、リクエストに応じてウェブページを更新するために、文書の一部を取り込むこともできます。
HTTP ベースシステムの構成要素
HTTP はクライアントサーバープロトコルであり、リクエストはユーザーエージェント(または代理のプロキシー)というひとつの実体から送信されます。 ほとんどの場合、ユーザーエージェントはウェブブラウザーですが、例えば検索エンジンのインデックスを収集および保守するためにウェブをクロールするロボットなど、どれでもクライアントになることができます。
個々のリクエストはサーバーに送信され、処理した後にレスポンスと呼ばれる回答を提供します。 クライアントとサーバーとの間には、例えばゲートウェイやキャッシュなどの様々な操作を行う、まとめてプロキシーサーバーと呼ばれるいくつもの実体が存在しています。

実際はブラウザーとサーバーの間に、ルーターやモデムなどリクエストを扱うコンピューターがさらに存在します。 ウェブが階層構造で設計されたおかげで、これらはネットワークやトランスポート層の中に隠されています。 HTTP はアプリケーション層の最上位に存在します。 ネットワークの問題を診断することは重要ですが、 HTTP を説明する際に下層のことはほとんど重要ではありません。
クライアント: ユーザーエージェント
ユーザーエージェントは、ユーザのために働くツールです。 この役割は主に、ウェブブラウザーが担いますが、エンジニアやウェブ開発者がアプリケーションをデバッグするために使用するプログラムである可能性もあります。
ブラウザーは常に、リクエストを生成する実体です。 サーバーにはなりません(もっとも、サーバーが生成するメッセージをシミュレートする仕組みが近年追加されましたが)。
ウェブページを表示するため、ブラウザーはページを表す HTML 文書を読み込むための最初のリクエストを送信します。 このファイルを解析して、実行するスクリプト、表示するレイアウトの情報 (CSS)、ページに含まれるサブリソース(通常、画像や動画)に対応する追加のリクエストを発行します。 そして、ウェブブラウザーはこれらのリソースを組み合わせて、完全な文書であるウェブページを提供します。 ブラウザーによって実行されるスクリプトが後の段階でさらにリソースを取り込んで、それに応じてブラウザーがウェブページを更新することがあります。
ウェブページは、ハイパーテキスト文書です。 これは表示されているコンテンツの一部が新たなウェブページの取り込みを(通常、マウスのクリックによって)発生させるリンクであり、ユーザーがユーザーエージェントを導いてウェブ内を移動できるということです。 ブラウザーはこれらの導きを HTTP リクエストに変換して、さらにユーザーへ明確なレスポンスを返すために HTTP レスポンスを解釈します。
ウェブサーバー
通信路の反対側は、クライアントのリクエストに応じて文書を提供するサーバーがいます。 サーバーは、仮想的には 1 台だけのマシンとしてしか見えませんが、実際には負荷を分担する(ロードバランシング)サーバーの集合であったり、他にも(キャッシュ、データベースサーバー、電子商取引サーバーなど)、要求に応じて文書を全体的または部分的に生成するソフトウェアであったりします。
サーバーは 1 台のマシンである必要性はありませんが、複数のサーバーのソフトウェアインスタンスを同じマシンで運用することができます。
HTTP/1.1 と Host ヘッダーによって、同じ IP アドレスを共有できます。
プロキシー
ウェブブラウザーとウェブサーバーの間では、多数のコンピューターや端末が HTTP メッセージを中継します。 ウェブスタックは階層構造であるため、これらの処理のほとんどはトランスポート層、ネットワーク層、物理層のいずれかで行われ、 HTTP 層から見れば透過的であり、パフォーマンスにかなりの影響を与えます。 アプリケーション層で行われる処理は、通常プロキシーと呼ばれます。 これらは透過的である場合、すなわち受信したリクエストをいかなる場合も変更せずに転送する場合と、透過的ではない場合、すなわちサーバーを通過する前に何らかの形でリクエストを変更する場合とがあります。 プロキシーはさまざまな機能を実行することがあります。
- キャッシュ(キャッシュは共用、あるいはブラウザーキャッシュのように個人用にできます)
- フィルタリング(アンチウィルススキャンやペアレンタルコントロールなど)
- 負荷分散(複数のサーバーが別々のリクエストに対応できるようにする)
- 認証(さまざまなリソースへのアクセスを制御する)
- ログ記録(履歴情報の保管を可能にする)
HTTP の基本方針
HTTP はシンプル
HTTP/2 で HTTP メッセージをフレームにカプセル化することにより複雑さが増しましたが、 HTTP は全体的にシンプルで人間が読めるように設計されています。 HTTP メッセージは人間が読んで理解することができ、開発者によるテストを容易にしています。また、初心者に対する複雑さも軽減します。
HTTP は拡張可能
HTTP/1.0 で導入された HTTP ヘッダーによって、プロトコルの拡張や実験が容易になっています。 新しい機能であっても、クライアントとサーバーが新たなヘッダーの意味について単純な合意があれば導入できます。
HTTP はステートレスであるがセッションレスではない
HTTP はステートレスです。同じコネクション上であっても、連続的に実行される 2 つのリクエスト間に関係性はありません。 これは電子商取引のショッピングバスケットなどのように、ユーザーが一貫した方法で特定のページと対話したいときに直接問題になります。 しかし HTTP の核心がステートレスであっても、 HTTP Cookie によってステートフルなセッションを実現できます。 ヘッダーの拡張性を利用して、ワークフローに HTTP Cookie が追加されれば、それぞれの HTTP リクエストが同じ状況や同じ状態を共有するためにセッションを作成できるようになります。
HTTP とコネクション
コネクションはトランスポート層で制御されますので、 HTTP の範囲から根本的に外れています。 HTTP は下層のプロトコルがコネクションベースであることに依存はせず、信頼性がある、つまりメッセージを失わないこと(少なくともそのような場合にエラーを表示すること)だけを要求します。 インターネットでもっとも一般的な 2 つのトランスポートプロトコルでは、 TCP には信頼性があり、 UDP には信頼性がありません。 したがって HTTP は、コネクションベースである TCP 標準に依存しています。
クライアントとサーバーが HTTP のリクエスト/レスポンスのペアを交換する前に TCP コネクションの確立が必要で、これは複数のやり取りを必要とします。 HTTP/1.0 の既定の動作は、それぞれのリクエスト/レスポンスのペアに対して個別に TCP コネクションを開くものです。 これは、複数のリクエストが近く連続して送信されたときに単一の TCP コネクションを共有することよりも非効率です。
この欠点を軽減するため、 HTTP/1.1 でパイプライン(実装が難しいことが立証されました)や持続的接続を導入しました。Connection ヘッダーを使用して、下層の TCP コネクションを部分的に制御できます。
HTTP/2 はひとつのコネクションで複数のメッセージを多重化するように進化しました。コネクションををウォーム状態に保つのに役立ち、効率が向上します。
より HTTP に適したトランスポートプロトコルを設計する実験が進んでいます。 たとえば Google は、より信頼性があり効率的なトランスポート層プロトコルを提供するため、 UDP 上に構築する QUIC の実験を行っています。
HTTP が制御できること
HTTP の拡張性により時間をかけて、ウェブの制御性や機能性が向上できました。 キャッシュや認証の方法は、 HTTP の草創期から取り扱われてきた機能です。 対照的に、オリジン制約を緩和する機能は 2010 年代にようやく追加されました。
HTTP で制御できる一般的な機能は以下のとおりです。
- キャッシュ: 文書をどのようにキャッシュするかを、 HTTP で制御できます。 サーバーはプロキシーやクライアントに対して、何をどれだけの間キャッシュするかを指示できます。 クライアントは中間のキャッシュプロキシーに対して、保存されている文書を無視するよう指示できます。
- オリジン制約の緩和: のぞき見や他のプライバシー侵害を避けるため、ウェブブラウザーはウェブサイト間を厳密に分割するよう強制しています。 同一オリジンのページだけが、ウェブページの情報すべてにアクセスできます。 この制約はサーバーにとって負担になりますが、 HTTP ヘッダーでサーバー側の厳密な分割を緩和できます。これにより、さまざまなドメインを情報源とした情報の寄せ集めの文書を作成できます。ただし、このようにするセキュリティ上の理由があります。
-
認証:
特定のユーザーしかアクセスできないように保護されたページがあるでしょう。
基本的な認証は HTTP が提供しており、
WWW-Authenticateなどのヘッダーを使用するか、 HTTP Cookie を使用した特別なセッションを設定するかします。 - プロキシーとトンネリング: サーバーやクライアントがイントラネット内に配置されて、他のコンピューターから本当の IP アドレスが見えなくなっていることがよくあります。 このネットワーク境界を渡るため、 HTTP リクエストはプロキシーを通過します。 すべてのプロキシーが HTTP プロキシーであるとは限りません。 たとえば、 SOCKS プロトコルはより低い層で動作します。 ほかにも FTP などがそれらのプロキシーで処理されることがあります。
- セッション: HTTP Cookie を使用して、リクエストとサーバーのセッションを関連付けできます。 これにより HTTP がステートレスプロトコルであるにもかかわらず、セッションを作成できます。 これは電子商取引のショッピングバスケットだけでなく、出力内容にユーザー設定を適用できるサイトでも有用です。
HTTP のフロー
クライアントがサーバー(最終目的地のサーバーまたは中間のプロキシー)と通信したいとき、クライアントは以下の段階を踏みます。
- TCP コネクションを開く: TCP コネクションはひとつまたは複数のリクエストを送信したり、回答を受け取ったりするために使用します。 クライアントは新しいコネクションを開く、既存のコネクションを再使用する、あるいはサーバーに対して複数の TCP コネクションを開くことができます。
-
HTTP メッセージを送信する: HTTP メッセージを(HTTP/2 より前)は人間が読むことができます。
HTTP/2 では単純なメッセージがフレーム内にカプセル化されており、直接読むことが不可能になりましたが、原理は変わっていません。
http
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - サーバーから送信されたレスポンスを読み取ります。
http
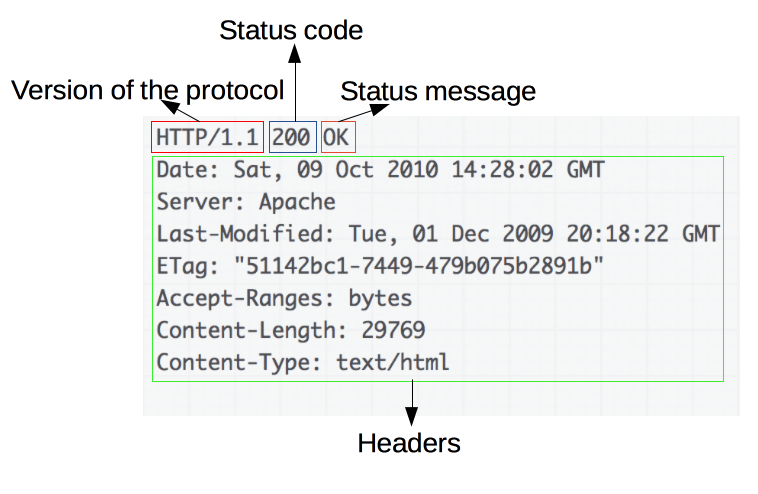
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html...(ここに、リクエストした 29769 バイトのウェブページが来ます) - 次のリクエストのために、コネクションを閉じるか再使用する
HTTP パイプラインが有効である場合は、最初のレスポンスが完全に返るのを待たずに複数のリクエストを送信できます。 HTTP パイプラインは既存のネットワークで実装するのが難しいことが立証されており、古いソフトウェアと最新バージョンのソフトウェアが共存しています。 HTTP パイプラインは、 HTTP/2 でフレーム内にリクエストを強力に多重化する機能によって置き換えられました。
HTTP メッセージ
HTTP/1.1 以前の HTTP メッセージは、人間が読むことができます。 HTTP/2 ではこれらのメッセージがバイナリ構造のフレームに埋め込まれており、ヘッダーの圧縮や多重化といった最適化が可能になりました。 本来の HTTP メッセージの部分だけがこのバージョンの HTTP で送信されていても、各メッセージの意味は変わっておらず、クライアントは本来の HTTP/1.1 メッセージを(事実上)再構成します。 したがって、 HTTP/2 メッセージを HTTP/1.1 形式で理解することは役に立ちます。
HTTP メッセージはリクエストとレスポンスの 2 種類あり、それぞれ固有の形式になっています。
リクエスト
HTTP リクエストの例です。
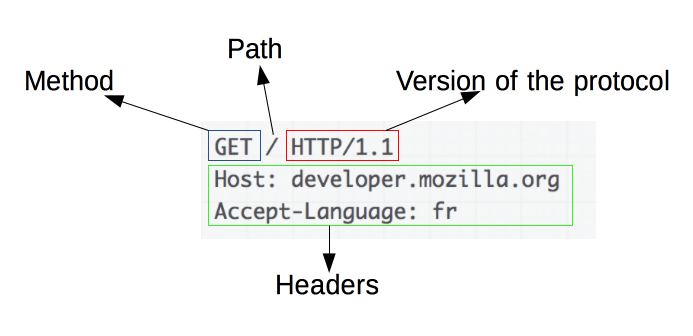
リクエストは以下の要素で構成されます。
-
HTTP メソッド。通常、クライアントが実行したい操作を定義する
GETやPOSTのような動詞か、OPTIONSやHEADのような名詞です。 一般的にクライアントはリソースを取り込む(GETを使用)か HTML フォーム の値を送信する(POSTを使用)ことを望みますが、場合によってはほかの操作が必要になります。 - 取り込むリソースのパス。状況から明らかであればリソースの URL はこの要素から取り除かれます。たとえばプロトコル (
http://)、ドメイン(ここではdeveloper.mozilla.org)、TCP ポート(ここでは80)が取り除かれます。 - HTTP プロトコルのバージョン。
- サーバーに追加の情報を与える任意のヘッダー。
POSTのようなメソッドではレスポンスと同様に、送信するリソースを包含した本体があります。
レスポンス
HTTP に基づく API
最もよく使われている HTTP に基づく API は XMLHttpRequest API で、ユーザーエージェントとサーバーの間でデータを交換するために使用することができます。
新しい Fetch API は、同じ機能をより強力で柔軟な一連の機能で提供します。
他の API、サーバー送信イベントは、サーバーがクライアントにイベントを送信することができる一方通行のサービスで、 HTTP をトランスポートの仕組みとして利用しています。
EventSource インターフェイスを使用して、クライアントは接続を開いてイベントハンドラーを確立します。
クライアントのブラウザーは HTTP ストリームに届くメッセージを自動的に適切な Event オブジェクトに変換します。それからイベントの型が分かればその型に登録されているイベントハンドラーに配信し、型に対してイベントハンドラーが設定されていない場合は、 onmessage イベントハンドラーに配信します。
まとめ
HTTP は容易に使用できる、拡張可能なプロトコルです。クライアントサーバー構造と単純にヘッダーを追加できる機能性を組み合わせて、 HTTP はウェブの機能拡張に合わせて進化できます。
HTTP/2 でパフォーマンスを向上するため、フレーム内に HTTP メッセージを埋め込むことにより複雑さがいくらか増しましたが、メッセージの基本的な構造は HTTP/1.0 から同じままです。 セッションのフローは依然として単純であり、フローの調査やシンプルな HTTP メッセージモニターでデバッグすることができます。